
Hardware Efficient C Code
When C code is compiled for a CPU, the complier transforms and optimizes the C code into
a set of CPU machine instructions. In many cases, the developers work is done at this stage.
If however, there is a need for performance the developer will seek to perform some or all
of the following:
• Understand if any additional optimizations can be performed by the compiler.
• Seek to better understand the processor architecture and modify the code to take
advantage of any architecture specific behaviors (for example, reducing conditional
branching to improve instruction pipelining)
• Modify the C code to use CPU-specific intrinsics to perform key operations in parallel.
(for example, ARM NEON intrinsics)
The same methodology applies to code written for a DSP or a GPU, and when using an
FPGA: an FPGA device is simply another target.
C code synthesized by Vivado HLS will execute on an FPGA and provide the same
functionality as the C simulation. In some cases, the developers work is done at this stage.
Typical C Code for a Convolution Function
The algorithm structure can be summarized as follows:
1 template<typename T, int K>
2 static void convolution_orig( 3 int width, 4 int height, 5 const T *src, 6 T *dst, 7 const T *hcoeff, 8 const T *vcoeff) { 9 T local[MAX_IMG_ROWS*MAX_IMG_COLS]; 10 // Horizontal convolution 11 HconvH:for(int col = 0; col < height; col++){ 12 HconvWfor(int row = border_width; row < width - border_width; row++){ 13 Hconv:for(int i = - border_width; i <= border_width; i++){ 14 } 15 } 16 // Vertical convolution 17 VconvH:for(int col = border_width; col < height - border_width; col++){ 18 VconvW:for(int row = 0; row < width; row++){ 19 Vconv:for(int i = - border_width; i <= border_width; i++){ 20 } 21 } 22 // Border pixels 23 Top_Border:for(int col = 0; col < border_width; col++){ 24 } 25 Side_Border:for(int col = border_width; col < height - border_width; col++){ 26 } 27 Bottom_Border:for(int col = height - border_width; col < height; col++){ 28 } 29 }
1 The C code for performing this operation is shown below. 2 const int conv_size = K; 3 const int border_width = int(conv_size / 2); 4 #ifndef __SYNTHESIS__ 5 T * const local = new T[MAX_IMG_ROWS*MAX_IMG_COLS]; 6 #else // Static storage allocation for HLS, dynamic otherwise 7 T local[MAX_IMG_ROWS*MAX_IMG_COLS]; 8 #endif 9 Clear_Local:for(int i = 0; i < height * width; i++){ 10 local[i]=0; 11 } 12 // Horizontal convolution 13 HconvH:for(int col = 0; col < height; col++){ 14 HconvWfor(int row = border_width; row < width - border_width; row++){ 15 int pixel = col * width + row; 16 Hconv:for(int i = - border_width; i <= border_width; i++){ 17 local[pixel] += src[pixel + i] * hcoeff[i + border_width]; 18 } 19 } 20 }
The first issue for the quality of the FPGA implementation is the array local. Since this is
an array it will be implemented using internal FPGA block RAM. This is a very large memory
to implement inside the FPGA. It may require a larger and more costly FPGA device. The use
of block RAM can be minimized by using the DATAFLOW optimization and streaming the
data through small efficient FIFOs, but this will require the data to be used in a streaming
manner.
The next issue is the initialization for array local. The loop Clear_Local is used to set
the values in array local to zero. Even if this loop is pipelined, this operation will require
approximately 2 million clock cycles (HEIGHT*WIDTH) to implement. This same initialization
of the data could be performed using a temporary variable inside loop HConv to initialize
the accumulation before the write.
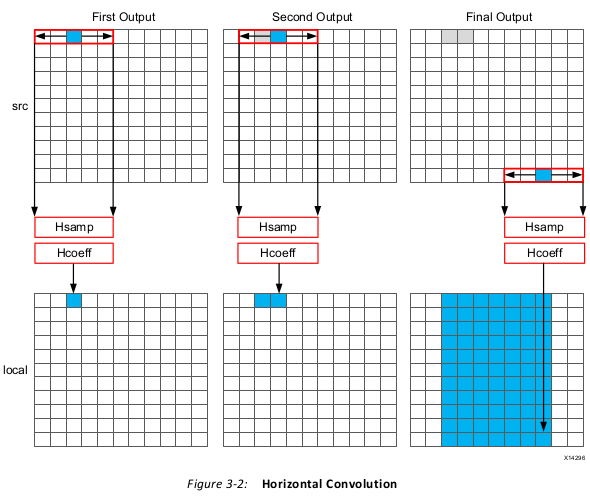
Finally, the throughput of the data is limited by the data access pattern.
• For the first output, the first K values are read from the input.
• To calculate the second output, the same K-1 values are re-read through the data input
port.
• This process of re-reading the data is repeated for the entire image.
1 Clear_Dst:for(int i = 0; i < height * width; i++){ 2 dst[i]=0; 3 } 4 // Vertical convolution 5 VconvH:for(int col = border_width; col < height - border_width; col++){ 6 VconvW:for(int row = 0; row < width; row++){ 7 int pixel = col * width + row; 8 Vconv:for(int i = - border_width; i <= border_width; i++){ 9 int offset = i * width; 10 dst[pixel] += local[pixel + offset] * vcoeff[i + border_width]; 11 } 12 } 13 }
This code highlights similar issues to those already discussed with the horizontal
convolution code.
• Many clock cycles are spent to set the values in the output image dst to zero. In this
case, approximately another 2 million cycles for a 1920*1080 image size.
• There are multiple accesses per pixel to re-read data stored in array local.
• There are multiple writes per pixel to the output array/port dst.
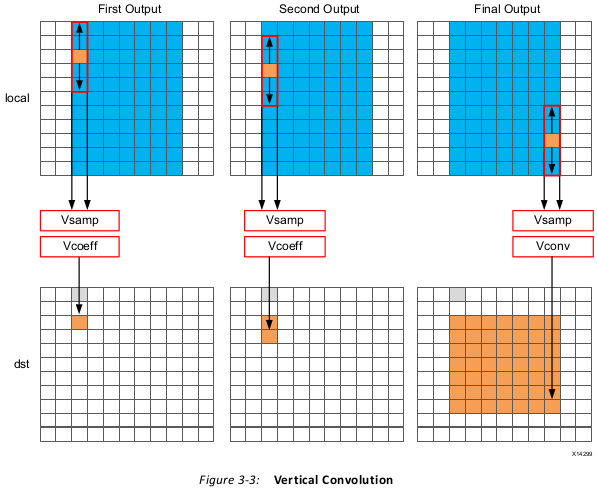
Another issue with the code above is the access pattern into array local. The algorithm
requires the data on row K to be available to perform the first calculation. Processing data
down the rows before proceeding to the next column requires the entire image to be stored
locally. In addition, because the data is not streamed out of array local, a FIFO cannot be
used to implement the memory channels created by DATAFLOW optimization. If DATAFLOW
optimization is used on this design, this memory channel requires a ping-pong buffer: this
doubles the memory requirements for the implementation to approximately 4 million data
samples all stored locally on the FPGA.
1 int border_width_offset = border_width * width; 2 int border_height_offset = (height - border_width - 1) * width; 3 // Border pixels 4 Top_Border:for(int col = 0; col < border_width; col++){ 5 int offset = col * width; 6 for(int row = 0; row < border_width; row++){ 7 int pixel = offset + row; 8 dst[pixel] = dst[border_width_offset + border_width]; 9 } 10 for(int row = border_width; row < width - border_width; row++){ 11 int pixel = offset + row; 12 dst[pixel] = dst[border_width_offset + row]; 13 } 14 for(int row = width - border_width; row < width; row++){ 15 int pixel = offset + row; 16 dst[pixel] = dst[border_width_offset + width - border_width - 1]; 17 } 18 } 19 Side_Border:for(int col = border_width; col < height - border_width; col++){ 20 int offset = col * width; 21 for(int row = 0; row < border_width; row++){ 22 int pixel = offset + row; 23 dst[pixel] = dst[offset + border_width]; 24 } 25 for(int row = width - border_width; row < width; row++){ 26 int pixel = offset + row; 27 dst[pixel] = dst[offset + width - border_width - 1]; 28 } 29 } 30 Bottom_Border:for(int col = height - border_width; col < height; col++){ 31 int offset = col * width; 32 for(int row = 0; row < border_width; row++){ 33 int pixel = offset + row; 34 dst[pixel] = dst[border_height_offset + border_width]; 35 } 36 for(int row = border_width; row < width - border_width; row++){ 37 int pixel = offset + row; 38 dst[pixel] = dst[border_height_offset + row]; 39 } 40 for(int row = width - border_width; row < width; row++){ 41 int pixel = offset + row; 42 dst[pixel] = dst[border_height_offset + width - border_width - 1]; 43 } 44 }
The code suffers from the same repeated access for data. The data stored outside the FPGA
in array dst must now be available to be read as input data re-read multiple time. Even in
the first loop, dst[border_width_offset + border_width] is read multiple times but the
values of border_width_offset and border_width do not change.
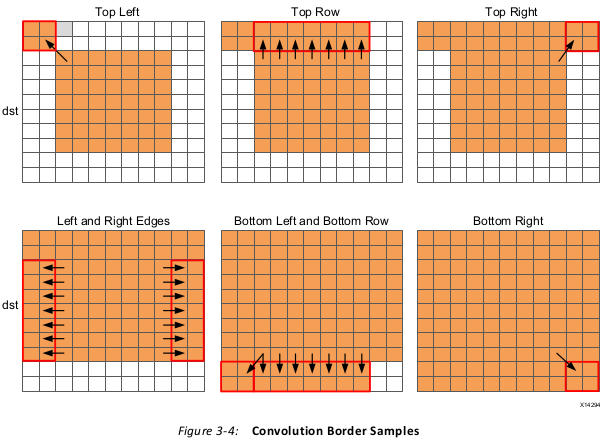
The final aspect where this coding style negatively impact the performance and quality of
the FPGA implementation is the structure of how the different conditions is address. A
for-loop processes the operations for each condition: top-left, top-row, etc. The
optimization choice here is to:
Pipelining the top-level loops, (Top_Border, Side_Border, Bottom_Border) is not
possible in this case because some of the sub-loops have variable bounds (based on the
value of input width). In this case you must pipeline the sub-loops and execute each set of
pipelined loops serially.
The question of whether to pipeline the top-level loop and unroll the sub-loops or pipeline
the sub-loops individually is determined by the loop limits and how many resources are
available on the FPGA device. If the top-level loop limit is small, unroll the loops to replicate
the hardware and meet performance. If the top-level loop limit is large, pipeline the lower
level loops and lose some performance by executing them sequentially in a loop
(Top_Border, Side_Border, Bottom_Border).
As shown in this review of a standard convolution algorithm, the following coding styles
negatively impact the performance and size of the FPGA implementation:
• Setting default values in arrays costs clock cycles and performance.
• Multiple accesses to read and then re-read data costs clock cycles and performance.
• Accessing data in an arbitrary or random access manner requires the data to be stored
locally in arrays and costs resources.
Ensuring the Continuous Flow of Data and Data Reuse
Summary of C for Efficient Hardware
Minimize data input reads. Once data has been read into the block it can easily feed many
parallel paths but the input ports can be bottlenecks to performance. Read data once and
use a local cache if the data must be reused.
Minimize accesses to arrays, especially large arrays. Arrays are implemented in block RAM
which like I/O ports only have a limited number of ports and can be bottlenecks to
performance. Arrays can be partitioned into smaller arrays and even individual registers but
partitioning large arrays will result in many registers being used. Use small localized caches
to hold results such as accumulations and then write the final result to the array.
Seek to perform conditional branching inside pipelined tasks rather than conditionally
execute tasks, even pipelined tasks. Conditionals will be implemented as separate paths in
the pipeline. Allowing the data from one task to flow into with the conditional performed
inside the next task will result in a higher performing system.
Minimize output writes for the same reason as input reads: ports are bottlenecks.
Replicating addition ports simply pushes the issue further out into the system.
For C code which processes data in a streaming manner, consider using hls::streams as
these will enforce good coding practices. It is much more productive to design an algorithm
in C which will result in a high-performance FPGA implementation than debug why the
FPGA is not operating at the performance required.
Reference:
1. Xilinx UG902