1.引子:什么是数据解析,为什么需要数据解析?
我们目前可以用浏览器自带的请求requests url进行相关的解析.
下面我们开始演示一下:
我们爬取一张图片,图片是一个网络资源
两种爬取图片的方式:
第一种图片形式的请求
import requests headers={ 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36' } img_url='https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1559053653699&di=71dbc2815b408c98408092e82c5a89d7&imgtype=0&src=http%3A%2F%2Fimg3.duitang.com%2Fuploads%2Fitem%2F201506%2F05%2F20150605103757_MsZS8.thumb.700_0.jpeg' img_data=requests.get(url=img_url,headers=headers).content #我们最后结尾是text字符串形式的?还是json的格式?,图片是二进制的格式我们需要用content,音频视频图片压缩包都是 with open("./meinv2.jpg",'wb')as fp: fp.write(img_data)
第二种图片形式的请求:
from urllib import request img_url='https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1559053653699&di=71dbc2815b408c98408092e82c5a89d7&imgtype=0&src=http%3A%2F%2Fimg3.duitang.com%2Fuploads%2Fitem%2F201506%2F05%2F20150605103757_MsZS8.thumb.700_0.jpeg' request.urlretrieve(img_url,'./meishaonv.jpg')
一定要检查自己写的是否正确
2.数据解析
数据解析的三种方式:在这里只说三种:
-正则
-xpath(通用性比较强)
-bs4
-pyquery(简单,自己了解)
(1)数据解析的原理
思考,如何对源码进行解析
我们需要爬取的内容是标签内的信息!!!
数据解析的步骤:
第一步:标签的定位
第二步:提取标签中存储的文本数据或者标签属性中存储的数据
(2)正则re解析:
需求:爬取糗事百科中所有的糗图图片数据
实现:
1.检查页面中的图片数据是否为动态加载的
2.将当前页面的源码数据请求到
3.使用正则表达式定位相关的img标签,然后获取img的src属性值
4.对src的属性值发起请求获取图片数据
5.持久化存储图片数据
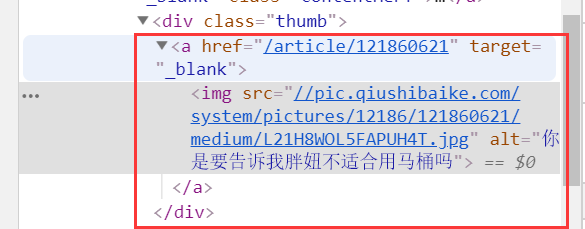
写一个正则匹配到所有的内容
import requests import re from urllib import request headers={ 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36' } url='https://www.qiushibaike.com/pic/' page_text=requests.get(url=url,headers=headers).text #拿到整个页面的字符串 ex='<div class="thumb">.*?<img src="(.*?)" alt.*?</div>' re.findall(ex,page_text,re.S) #第一个参数是正则,第二个参数是匹配的所有字符串 #.*?不能处理回车,所以我们需要加上re.S,也就是多了一个/n回车的功能 #40分钟,上图出错的原因是正则表达式中的alt前面少了一个alt,我们拿到的是图片的地址
升级存储:
import requests import re from urllib import request import os if not os.path.exists('./qiutu'): os.mkdir('./qiutu') #如果当前文件夹不存在,我们就在当前文件夹下,创建一个"qiutu"文件夹 headers={ 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36' } url='https://www.qiushibaike.com/pic/' page_text=requests.get(url=url,headers=headers).text #拿到整个页面的字符串 ex='<div class="thumb">.*?<img src="(.*?)" alt.*?</div>' img_url=re.findall(ex,page_text,re.S) #第一个参数是正则,第二个参数是匹配的所有字符串 #.*?不能处理回车,所以我们需要加上re.S,也就是多了一个/n回车的功能 #40分钟,上图出错的原因是正则表达式中的alt前面少了一个alt,我们拿到的是图片的地址 for url in img_url: url='https:'+url img_name=url.split('/')[-1] img_path='./qiutu/'+img_name request.urlretrieve(url,img_path) print(img_name,'下载成功啦!!!!')
思考题:
将糗图中前5页的图片进行下载(可以适当使用其他网站)
(3)bs解析
解析原理:
实例化一个Beautifulsoup的对象,且将页面源码数据加载到对象中
使用该对象的相关属性或方法实现标签定位和数据提取
环境的安装:
pip install bs4
pip install lxml
实例化BeautifulSoup对象,lxml是解析器,page_text表示的是拿到的响应数据,fp是with的返回值
第一种形式:BeautifulSoup(page_text,'lxml') #将互联网上请求到的页面源码数据加载到该对象中
第二种形式:BeautifulSoup(fp,'lxml') #将本地存储的一样页面源码数据加载到该对象中
第一种方式用的会多一些,测试本地的数据.test,html文件
<html lang="en"> <head> <meta charset="UTF-8" /> <title>测试bs4</title> </head> <body> <div> <p>百里守约</p> </div> <div class="song"> <p>李清照</p> <p>王安石</p> <p>苏轼</p> <p>柳宗元</p> <a href="http://www.song.com/" title="赵匡胤" target="_self"> <span>this is span</span> 宋朝是最强大的王朝,不是军队的强大,而是经济很强大,国民都很有钱</a> <a href="" class="du">总为浮云能蔽日,长安不见使人愁</a> <img src="http://www.baidu.com/meinv.jpg" alt="" /> </div> <div class="tang"> <ul> <li><a href="http://www.baidu.com" title="qing">清明时节雨纷纷,路上行人欲断魂,借问酒家何处有,牧童遥指杏花村</a></li> <li><a href="http://www.163.com" title="qin">秦时明月汉时关,万里长征人未还,但使龙城飞将在,不教胡马度阴山</a></li> <li><a href="http://www.126.com" alt="qi">岐王宅里寻常见,崔九堂前几度闻,正是江南好风景,落花时节又逢君</a></li> <li><a href="http://www.sina.com" class="du">杜甫</a></li> <li><a href="http://www.dudu.com" class="du">杜牧</a></li> <li><b>杜小月</b></li> <li><i>度蜜月</i></li> <li><a href="http://www.haha.com" id="feng">凤凰台上凤凰游,凤去台空江自流,吴宫花草埋幽径,晋代衣冠成古丘</a></li> </ul> </div> </body> </html>
示例:
from bs4 import BeautifulSoup fp=open('./test.html','r',encoding='utf-8') soup=BeautifulSoup(fp,'lxml') soup
思考:如何进行标签定位?
#注意,这个文件和上边的test.html在同一个目录下 from bs4 import BeautifulSoup fp=open('./test.html','r',encoding='utf-8') soup=BeautifulSoup(fp,'lxml') #测试1,标记定位 #soup.title #定位到title标签 #结果: #<title>测试bs4</title> #测试2 #soup.div #只可以定位到第一个出现tagName的标签div,返回的永远是单数. #结果: # <div> # <p>百里守约</p> # </div> #测试3 # soup.find('a') #得到的是第1个内容.等价于soup.a #标准格式,属性定位,拿到第一个结果 #结果: # <a href="http://www.song.com/" target="_self" title="赵匡胤"> # <span>this is span</span> # 宋朝是最强大的王朝,不是军队的强大,而是经济很强大,国民都很有钱</a> #测试4:原因是class是关键字,属性定位 # soup.find('div',class_='song') #注意class的横杠在后边? #soup.find('div',class_='tang') #测试5:find_all #soup.find_all('div') #返回的是列表,列表里边是所有的div #soup.find_all('div')[2] #我们可以加上索引,进行返回 #测试6:select选择器 #soup.select('.song') #返回所有符合条件的内容,注意这个返回的是列表 # soup.select('div') #测试7.层级选择器 ,定义到所有的li,直系子标签, #跨一个层级的用法 #soup.select('.tang > ul > li > a') #注意必须要有括号 #跨多个层级的用法, #soup.select('.tang a') # 注意: # >表示单个层级,空格表示多个层级 #测试8,取文本,取第一个文本 #soup.p.string #测试9.取所有的文本的数据的两种方式 #soup.find('div',class_='tang').get_text() #soup.find('div',class_='tang').text #总结:string取的是直系的文本数据,text获取的是全部的数据 #测试10,取属性 #soup.a #soup.a['href'] #测试11,取某标签内的url soup.select('.tang > ul > li > a')[0]['href']
(4)一个例子:爬取三国演义小说流程:http://www.shicimingju.com/book/sanguoyanyi.html
-判断页面数据是否为动态加载数据
-在首页中解析章节标题和标题对应的详情页的url
-对详情页url发起请求获取详情页的源码数据
-检查详情页是否存在动态加载的数据
-解析详情页中的章节内容
-持久化存储
import requests headers={ 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36' } url='http://www.shicimingju.com/book/sanguoyanyi.html' page_text=requests.get(url=url,headers=headers).text #字符串 #数据解析;标题和url soup=BeautifulSoup(page_text,'lxml') #第一次解析 li_list=soup.select('.book-mulu > ul > li') #存储的是所有的li标签,是列表 for li in li_list: title=li.a.string #只取1个 detail_url='http://www.shicimingju.com'+li.a['href'] #在获取的href需要加上部分链接 #print(title,detail_url) #单独对详情页发起请求获取源码数据 detail_page_text=requests.get(url=detail_url,headers=headers).text soup=BeautifulSoup(detail_page_text,'lxml') #第二次解析 content = soup.find('div',class_="chapter_content").text #下划线.写错,一定要注意细节 print(content) break
爬取三国数据的文件:最后得到的文件是sanguo.txt
import requests headers={ 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36' } url='http://www.shicimingju.com/book/sanguoyanyi.html' page_text=requests.get(url=url,headers=headers).text #字符串 #数据解析;标题和url soup=BeautifulSoup(page_text,'lxml') #第一次解析 li_list=soup.select('.book-mulu > ul > li') #存储的是所有的li标签,是列表 fp=open('./sanguo.txt','a',encoding='utf-8') #在外部发开的文件 for li in li_list: title=li.a.string #只取1个 detail_url='http://www.shicimingju.com'+li.a['href'] #在获取的href需要加上部分链接 #print(title,detail_url) #单独对详情页发起请求获取源码数据 detail_page_text=requests.get(url=detail_url,headers=headers).text soup=BeautifulSoup(detail_page_text,'lxml') #第二次解析 content = soup.find('div',class_="chapter_content").text #下划线.写错,一定要注意细节 fp.write(title+'\n'+content+'\n') print(title,':下载成功!') fp.close()
(4)xpath解析:
--解析效率比较高
--通用性最强的,其他语言也是用这个的
--环境安装:pip install lxml
--解析原理:
--实例化一个etree对象且将即将被解析的页面源码数据加载到该对象中
--使用etree对象中的xpath方法结合着xpath表达式进行标签定位和数据提取
--实例化etree对象
--etree.parse('本地文件路径')
--etree.HTML(page_text)
from lxml import etree tree=etree.parse('./test.html') tree
思考上边的xpath和beautifulsoup的区别是什么?
区别:BeautifulSoup返回的页面源码,xpath返回的是对象
下面学习下xpath的表达式.
test1,定位title标签,html是一个树状图
from lxml import etree tree=etree.parse('./test.html') #定位title标签 ,第一个/表示的是根节点 tree.xpath('/html/head/title') #这样返回的是列表,里边是Element标签
tree.xpath('/html//title') #第二种方式
tree.xpath('//title')
tree.xpath('//div')#定位到三个列表
#定位
from lxml import etree tree=etree.parse('./test.html') #定位title标签 ,第一个/表示的是根节点 # tree.xpath('/html/head/title') #这样返回的是列表,里边是Element标签 # tree.xpath('/html//title') # tree.xpath('//title') #tree.xpath('//div') #定位class=song的div # tree.xpath('//div[@class="song"]') # tree.xpath('//div[2]') #注意:xpath表达式中的索引是从1开始的 #tree.xpath('//div[@class="tang"]/ul/li[4]/a') #tree.xpath('//div[@class="tang"]//li[4]/a') #等价上边的这个 #取文本(获取李清照) /text() 取直系文本内容 //text()取所有的文本内容 #tree.xpath('//div[@class="song"]/p[1]/text()') #返回的是一个列表 # tree.xpath('//div[@class="song"]/p[1]/text()')[0] # tree.xpath('//div[@class="song"]/p/text()') # //text() #取属性,取所有a的属性 tree.xpath('//a/@href') #最后总结还是需要记忆的 tree.xpath('//a/@title')
爬取boss直聘的信息:
#boss直聘,爬虫工程师爬取数据 import requests headers={ 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36' } url='https://www.zhipin.com/job_detail/?query=python%E7%88%AC%E8%99%AB&city=101010100&industry=&position=' page_text=requests.get(url=url,headers=headers).text #数据分析(jobtitle,salary,company) tree=etree.HTML(page_text) li_list=tree.xpath('//div[@class="job-list"]/ul/li') for li in li_list: title=li.xpath('.//div[@class="job-title"]/text()')[0] #//a定位到所有的a,我们用./a定位到的是当前li下的a #上边这个点很重要 salary=li.xpath('.//span[@class="red"]/text()')[0] company=li.xpath('.//div[@class="company-text"]/h3/a/text()')[0] print(title," ",salary," ",company)
思考,如何处理中文乱码的问题?
测试:
1.将糗图中前5页的图片进行下载(可以适当使用其他网站)
2.爬取boss相关的岗位信息(详情页)