下一个项目将开始研究全景分割,这里把去年和今年出来的paper简单列了一下,全景分割框架内有很多细节,一时半会没法吃透,需要时间慢慢消化。
Panoptic Segmentation
核心思想
http://arxiv.org/abs/1801.00868
- 提出新的任务PS,结合了semantic segmentation和instance segmentation
- 提出新的指标PQ
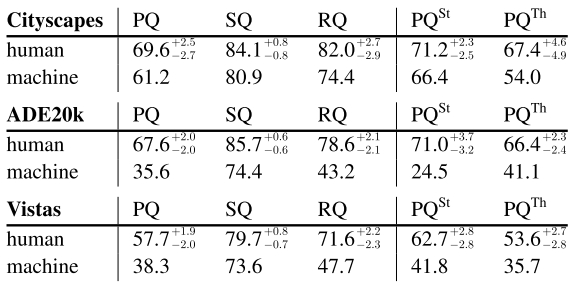
- 在三个数据集上研究了人和机器的表现。
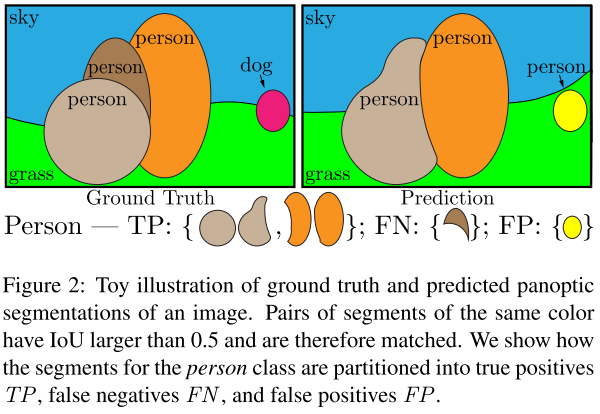
评价指标
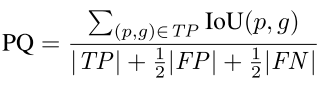
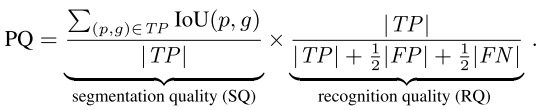
网络架构
結合语义分割和实例分割的output。在Cityscapes数据集上,用PSPNet和Mask R-CNN提供语义和实例分割。
实验结果
Panoptic FPN
核心思想
- 基于Mask R-CNN with FPN,并作了一些小改变来生成语义分割结果。
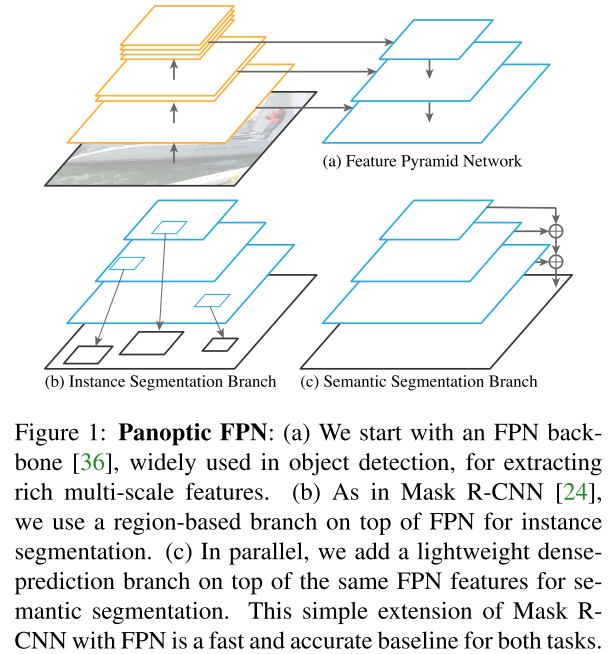
网络架构
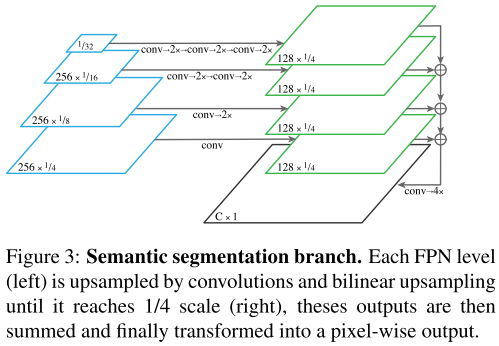
Semantic segmentation branch
从FPN的最深层开始,每层上采样为1/4scale的feature map。每次上采样包含3x3conv,group norm,ReLU和2x双线性插值。
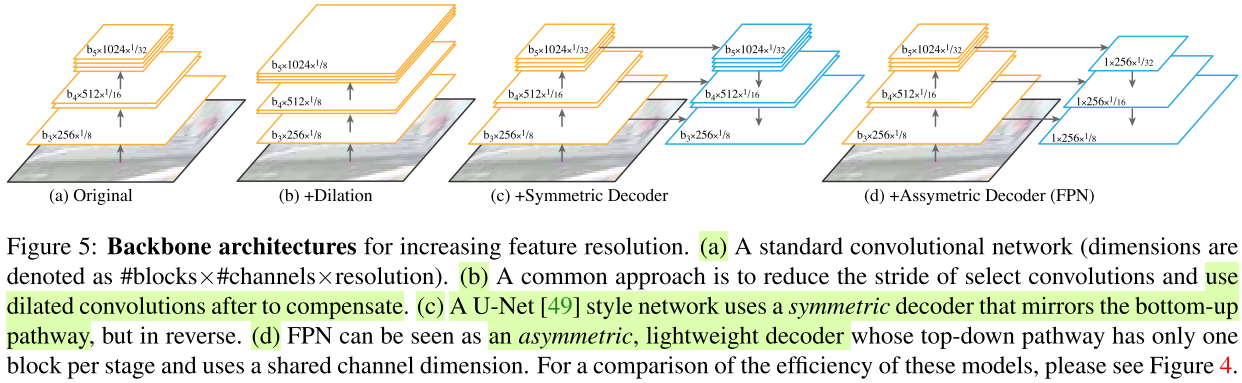
作者还考虑了内存和计算量,对比了如下的不同设计,发现FPN最高效。
联合训练
Instance segmentation losses:\(L_c(classification loss),L_b(bounding-box loss),L_m(mask loss)\)
Semantic segmentation loss:\(L_s\)
Final loss:\(\lambda_i(L_c+L_b+L_m)+\lambda_s L_s\)
实验结果

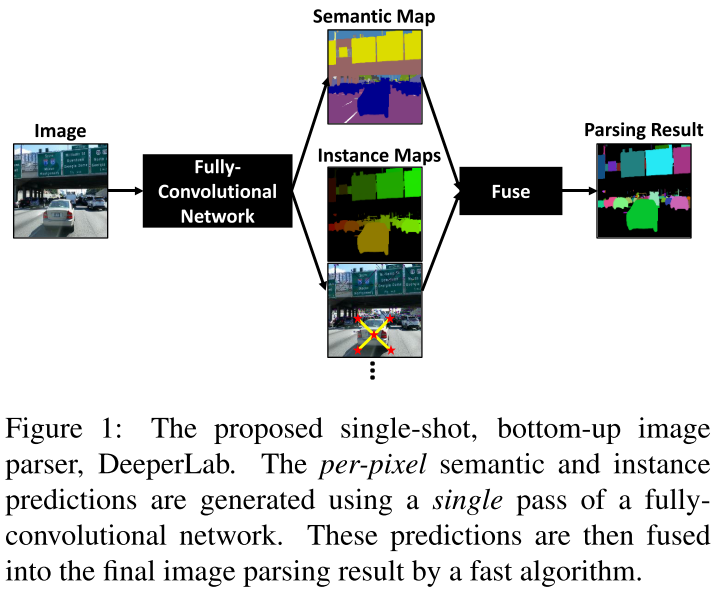
DeeperLab
核心思想
- 主要贡献
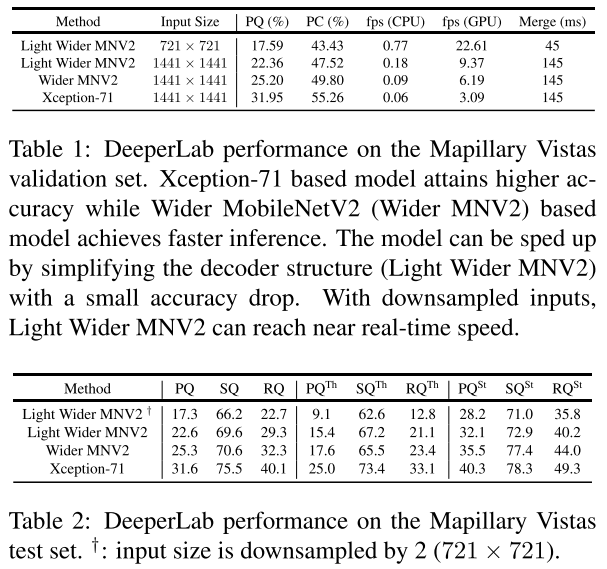
- 提出了几种网络设计策略,特别是减少高分辨率输入的内存占用。
- 基于设计策略,提出了高效single-shot,bottom-up的DeeperLab。
- 提出了新的指标Parsing Covering,从基于区域的角度评估图像解析结果。
Parsing Covering
PQ只关注每个实例的分割质量,而不考虑不同实例的大小,不同大小物体最终分割结果对PQ影响相同,于是提出了PC评价指标。

\(R,R'\)分别表示对应类别的预测segments与真实segments,\(|R|\)表示对应类别的实例在真实标注中像素点数量,\(N_i\)表示类别为i的真实标注像素点总和。通过对大的实例物体赋予更大的权重,使评价指标能够更明显地反映大物体的分割指标。
网络架构

Encoder
- Xception-71或MobileNetV2,并在末尾加了ASPP。
Decoder
- 借鉴了DeepLabV3+。ASPP的输出分别被1x1conv降维然后concat。
- DeepLabV3+在concat前上采样已经降维后的ASPP的输出,但上采样会带来内存消耗,于是采用space-to-depth operation。
- 后面还使用两个7x7的depthwise conv来增大感受野,然后通过depth-to-space降维。

Image Parsing Prediction Heads
- Semantic Segmentation Head:最小化bootstrappd cross-entropy loss并且用了hard example mining,只回传top-K errors。
- Instance Segmentation Head
- the keypoint heatmap:预测像素是否位于关键点中心半径为R的圈内。
- the long-range offset map:预测像素到所有关键点的位置偏移,对每个像素的long-range信息编码。
- the short-range offset map:类似于long-- range其仅关注关键点半径R内的像素。
- the middle-range offset map:预测关键点对之间的偏移。
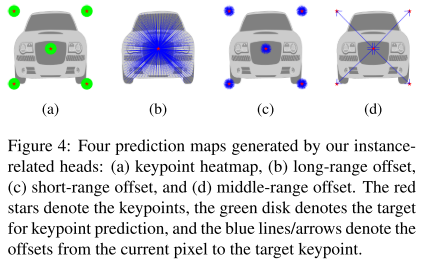
- Prediction Fusion:将四个预测融合到一个类不相关的instance segmentaion map,再最终融合semantic和instance segmentation map。
- Instance Predicton:Recursive offset refinement、Keypoint localization、Instance detection、Assignment of pixels to instances
- Semantic and Instance Prediction Fusion:从语义分割开始,被预测为‘stuff’被分配唯一的instance label。其他像素的instance label通过实例分割确定,其semantic label则通过多数投票。
实验结果
AUNet
核心思想
- 设计了PAM和MAM,分别基于RPN阶段的特征图与实例分割输出的前景分割区域,为stuff segmentation提供了物体层级注意力与像素层级注意力。
网络架构
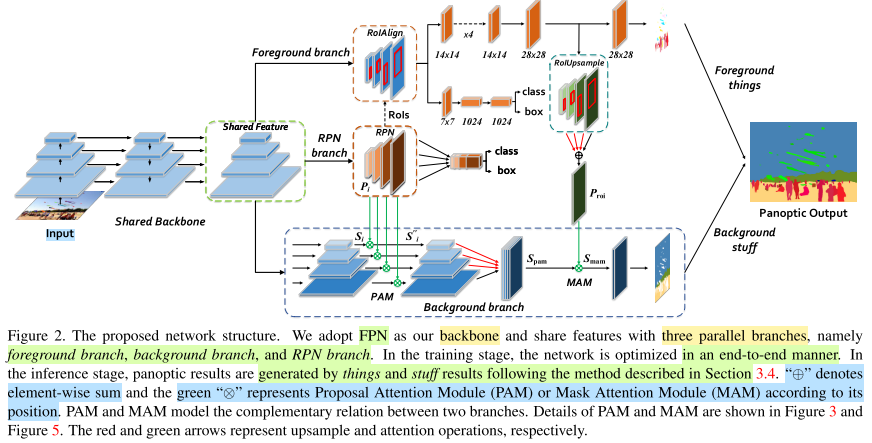
Attention-guided Modules
Proposal Attention Module(PAM)
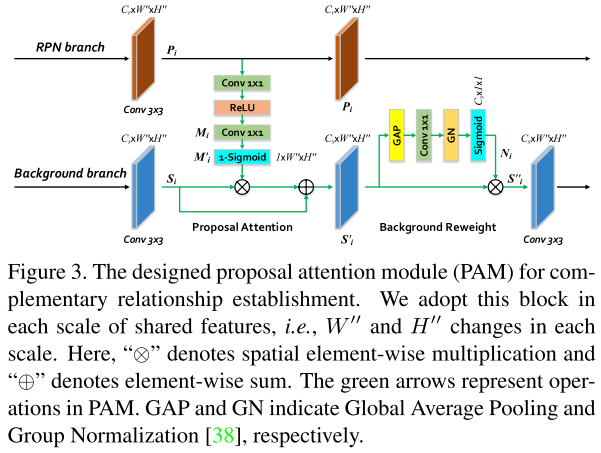
Mask Attention Module(MAM)
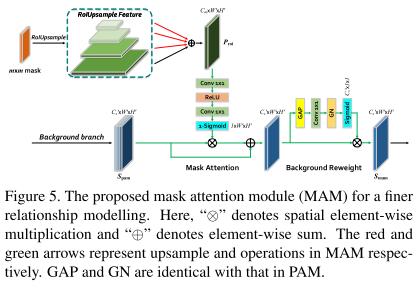
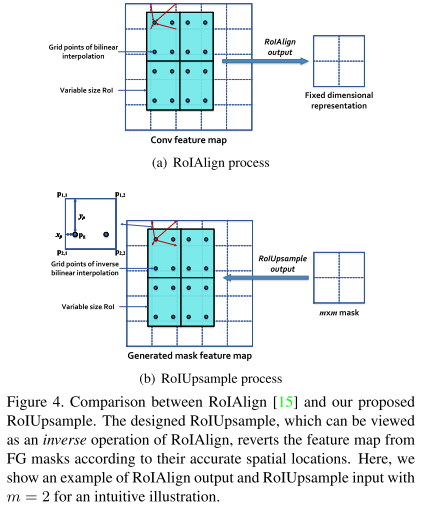
此外还提出了RoIUpsample
实验结果

UPSNet
核心思想
网络架构
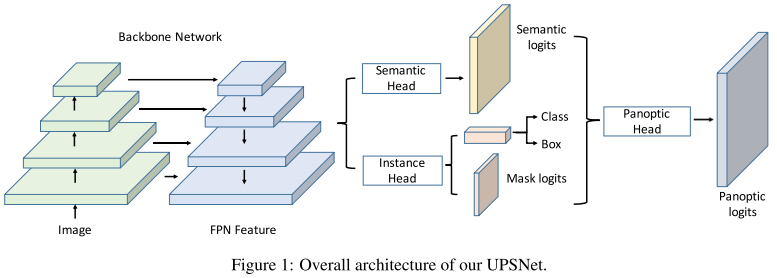
Backbone:Mask R-CNN(ResNet+FPN)
Instance Segmentation Head:Bbox regression output、cls output 和seg mask output。
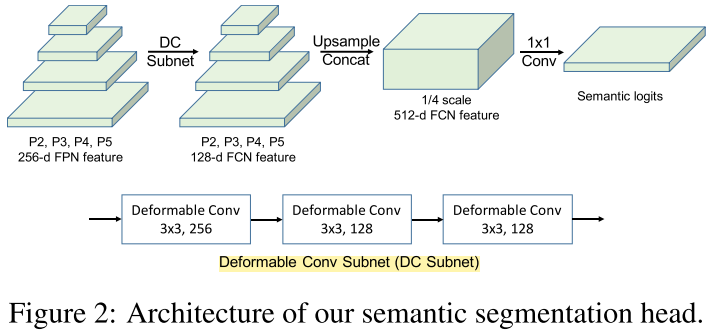
Semantic Segmentation Head:
Panoptic Segmentation Head:
实验结果
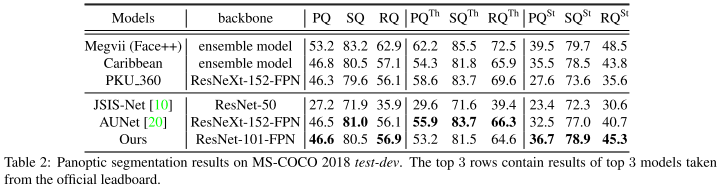
TASCNet
核心思想
- 使实例分割和语义分割的预测输出保持一致性。
网络架构
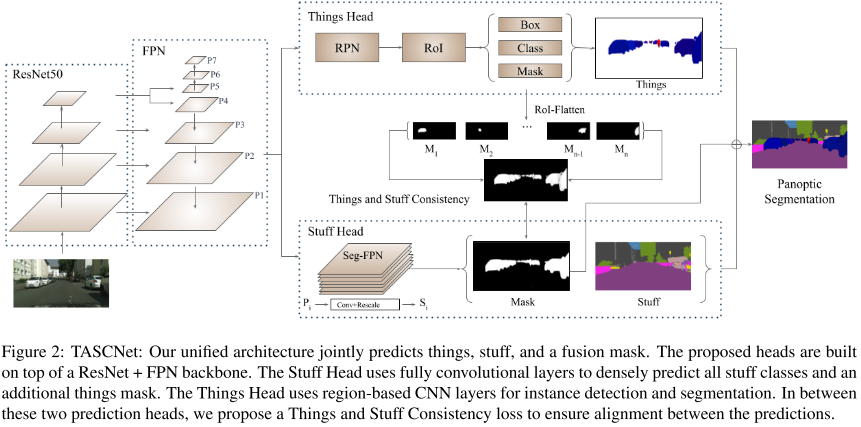
- Backbone:ResNet50+FPN,可捕获更深层次的低级特征,识别更广泛的对象尺度。
- Stuff Head
- 用3x3conv 将维度从256降到128。
- 使用group normalization归一化层。
- 使用额外的3x3conv,保持channel。
- 归一化并上采样到FPN最大尺度的feature map。
- Things Head:类似于Mask R-CNN,有三个head。
- Stuff Head
- TASC:将两个head的输出分布分开。
- Mask-Guided Fusion
实验结果
JSIS-Net
核心思想
- CNN联合预测语义分割和实例分割输出
- 启发式合并输出来生成全景分割结果
网络架构
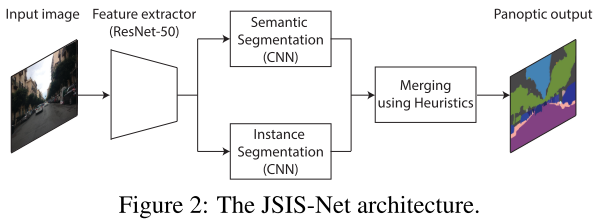
框架
Backbone:ResNet-50,被语义分割和实例分割共享。
semantic segmentation branch:首先采用Pyramid Pooling Module来生成feature map,再使用混合上采样将预测变成原图尺度。混合上采样首先采用了转置卷积然后是双线性插值。
instance segmentation branch:基于Mask R-CNN。
用Loss来平衡联合学习。
- 合并输出:需要解决两类冲突:overlapping instance masks和conflicting stuff predictions
- Ovelapping instance masks:对所有重叠的instance mask采用NMS,但是会移除很多true的预测。相反,我们选择利用每个实例的概率图来解决冲突。在多个instance mask预测像素属于某个物体,采取特定像素处具有最高概率的。
- Conflicting predictions for things classes:thing存在于语义分割和实例分割,无可避免会有冲突。于是我们移除语义分割输出中所有thing类并用最可能的stuff类替换它们,这样语义分割输出中只有stuff类。然后用实例分割输出的thing替代语义分割输出。
实验结果

OANet
http://arxiv.org/abs/1903.05027
核心思想
Contribution
第一个提出全景分割中的end-to-end occlusion aware pipeline。
- 提出了一种spatial ranking module来解决重叠关系的模糊性。
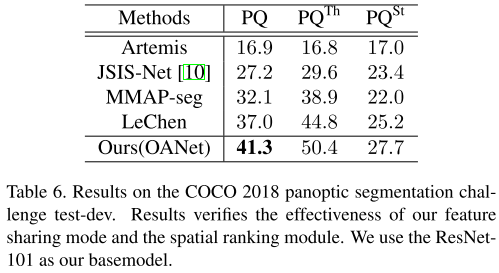
在COCO全景分割数据集上达到了SOTA。
网络架构
算法包含三部分
- stuff branch预测整张图的stuff segmentation
- instance branch提供instance segmentation
- spatial ranking module为每个instance生成ranking score
End-to-end 网络架构
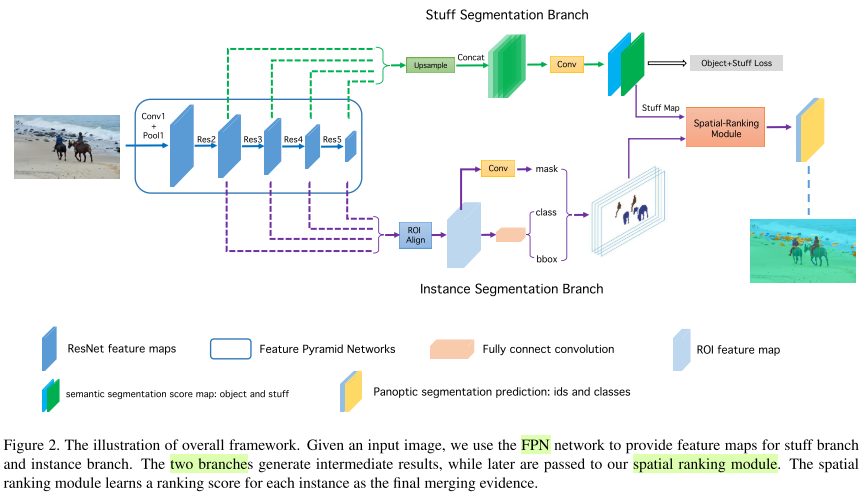
- backbone:FPN
- Instance segmentation:Mask R-CNN提供proposal classification score、proposal bb coordinates和proposal instance mask。
- stuff segmentation:两个3x3conv叠加在RPN的feature map上,之后concatenate。共享backbone和skip-connection。object信息可以为stuff提供上下文,在测试时,我们只提取stuff preditions并将其归一化为概率。
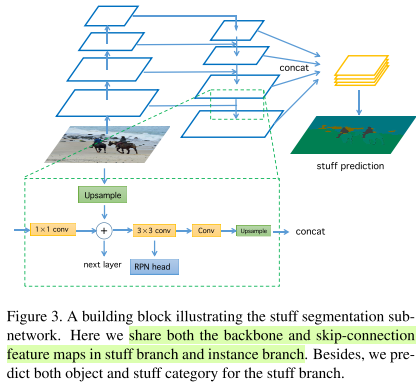
为了平衡两种监督,我们提出了multiple losses。
\[L_{total}=(L_{rpn_cls}+L_{rpn_bbox}+L_{cls}+L_{bbox}+L_{mask})+\lambda \cdot L_{seg_(stuff+object)+L_{srm}}\]
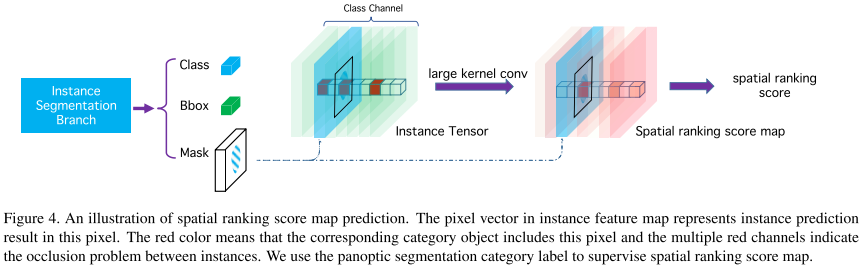
Spatial Ranking Module
当前的实例分割框架没有考虑不类间的重叠问题,因为指标AP等不受此问题影响。然而全景分割任务中图像中的像素固定,因此必须解决重叠问题,或一个像素多分配。

检测分数通常对instance采用降序排列,由于COCO中人更加频繁,使得领带被误判为人。 于是本文提出spatial ranking module模块,isntance tensor被初始化为0,mapping value被设置为1。然后我们在tensor后采用large kernel conv来获得ranking score map。最后使用pixel-wise cross entropy loss来优化ranking score map。
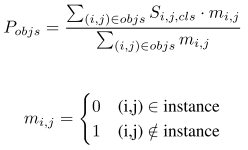
实验结果
Weakly- and Semi-Supervised Panoptic Segmentation
核心思想
- 首个采用弱监督学习全景分割的方法,在没有足够全景分割标注的情况下,学习模型。
总结
- 可以从以下三个角度分析与优化全景分割算法:
- 网络框架搭建:这里指提出一个整体网络,实现端到端。
- 子任务融合(Subtask Fusion):通常stuff 和instance分支通常相互独立,这里指两个分支间是否建立了关联并相互促进。
- 全景输出预测(Panoptic Output):合并stuff和instance分支结果时,通常采用先验逻辑判断;这里指是否设计了针对全景分割结果合并的模块。
| Method | Contribution | End-to-end | Subtask Fusion | Panoptic Output | COCO 2018 task |
|---|---|---|---|---|---|
| Panoptic Segmention | define the ps task、Metric:PQ | × | × | × | |
| Panoptic FPN | Up-to-Down | √ | × | × | 40.9 |
| JSIS-Net | Try end-to-end | √ | × | × | 27.2 |
| DeeperLab | Bottom-to-Up、Metric:PC | √ | × | √ | - |
| UPSNet | Panoptic Head | √ | × | √ | 46.6 |
| OANet | Occlusion Aware | √ | × | √ | 41.3 |
| AUNet | Attention-guided | √ | √ | × | 46.5 |
| TASCNet | Cross-task Consistency | √ | √ | √ | - |
参考
- paper
[1]Kirillov A, He K, Girshick R, et al. Panoptic segmentation[J]. arXiv preprint arXiv:1801.00868, 2018.
[2]Kirillov A, Girshick R, He K, et al. Panoptic Feature Pyramid Networks[J]. arXiv preprint arXiv:1901.02446, 2019.
[3]Yang T J, Collins M D, Zhu Y, et al. DeeperLab: Single-Shot Image Parser[J]. arXiv preprint arXiv:1902.05093, 2019.
[4]Li Y, Chen X, Zhu Z, et al. Attention-guided unified network for panoptic segmentation[J]. arXiv preprint arXiv:1812.03904, 2018.
[5]Xiong Y, Liao R, Zhao H, et al. UPSNet: A Unified Panoptic Segmentation Network[J]. arXiv preprint arXiv:1901.03784, 2019.
[6]Li J, Raventos A, Bhargava A, et al. Learning to fuse things and stuff[J]. arXiv preprint arXiv:1812.01192, 2018.
[7]de Geus D, Meletis P, Dubbelman G. Panoptic segmentation with a joint semantic and instance segmentation network[J]. arXiv preprint arXiv:1809.02110, 2018.
[8]Liu H, Peng C, Yu C, et al. An End-to-End Network for Panoptic Segmentation[J]. arXiv preprint arXiv:1903.05027, 2019.
- blog