背景
抱着《python学习手册》啃了很久,心里想着要动手写点东西,但是一直拖延症到最近才真正开始准备。一开始不知道写点啥好,就从生活中挖掘,发现自己每天查天气预报查的挺频繁的,那就爬一波天气预报吧。
技术概览
- selenium
- time
- re
- calendar
爬取网页数据的过程中就用到以上4个模块,其中calendar是可选的,最初的版本是只爬取当月的每日天气所以不需要calendar,后续新增了可选月份的功能,才加上calendar。本次爬虫是用类来实现的,但实际上用简单函数即可,但抱着学以致用的想法还是用类吧,虽然类有很多很强大的功能(继承、多态、定制等),但在我这几十行的代码里并不能体现出来。我的环境是win10+python27,因为工作需要所以个人PC也是python2的,后续会更新成python3。
具体内容
class Weather(object):
def __init__(self):
self.day = time.strftime('%d', time.localtime(time.time()))
self.month = time.strftime('%m', time.localtime(time.time())) 在类的开始定义了一个构造函数,里面有两个属性:day和month分别是今天的日期和当月月份,这里就用到time模块中的time、localtime、strftime。详细的介绍可以看菜鸟教程,我们现场实践下。

这里先导入time模块,然后time.time()是当前时间的一个时间戳,需要用localtime()格式化成time.struct_time类型的对象。(struct_time是在time模块中定义的表示时间的对象)然后再用strftime()接收struct_time对象,返回一个字符串表示的时间值,如图所示,我码字的时候正是5月23号。
def get_weather_html(self):
#打开中国天气网的40天天气预报的网页,爬取数据
url = 'http://www.weather.com.cn/weather40d/101020100.shtml'
driver = webdriver.Chrome()
driver.get(url)
driver.maximize_window()
driver.implicitly_wait(3)
month_input = raw_input('please input month:')
if month_input != '' and month_input != self.month:
self.select_month(month_input,driver)如果想用selenium的话,要先下个驱动下载地址我用的是谷歌浏览器,所以对应的驱动是cromedriver.exe,注意驱动跟版本强相关,没有下对版本的话就会报错。驱动放在python.exe同目录下即可。上面代码主要做的事情就是:
- 创建浏览器的实例driver
- 打开中国天气网
- 将浏览器最大化
- 等待页面加载完成
- 等待用户输入期待爬虫的月份
- 如果输入的月份不是当前月份或者不是空字符串(不输入月份直接回车就是空字符串),则调用select_month
这里要强调下implicitly_wait作为隐式等待可以在页面元素找到的时间提前退出等待,但是这里设置的全局的等待时候,假设代码里的路径有错或者其他什么问题,会导致调试时间变长。也可以使用time.sleep(3)这种显式等待,设3s就是等待3s,不管元素找到与否。selenium-python里有很多selenium的详细介绍,关于显示等待和隐式等待的也有。
def select_month(self, month, driver):
driver.find_element_by_xpath('//*[@class="zong"]').click()
month_path = '//div[@class="w_nian"]/ul[2]/li['+month+']'
driver.find_element_by_xpath(month_path).click()
- 点击打开网页上选择月份的弹框
- 创建用户需要的月份的路径
- 点击该月份
xpath安装详见左边链接,亲测可用。这里需要用到xpath相关的知识,w3school、菜鸟教程上有很多很详细的这里就不赘述。让我们动手实践下:
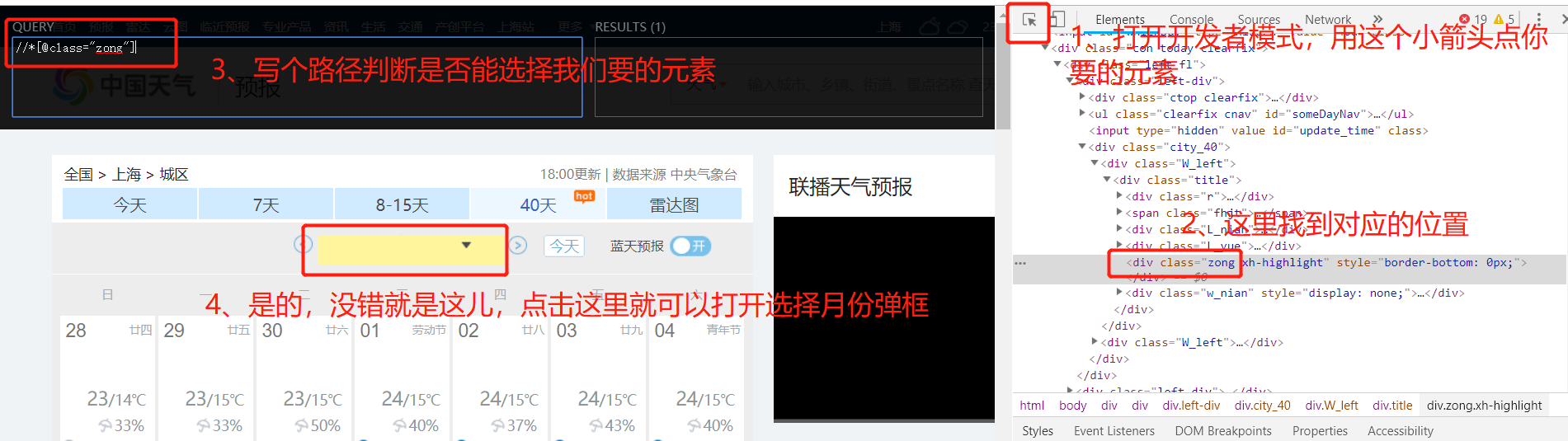
图片文字显示不全,1、打开开发者模式,用这个小箭头点你要的元素。2、这里找到元素对应的位置。
for week_index in range(2,8):
for day_index in range(1,8):
week = str(week_index)
day = str(day_index)
day_path = '//*[@id="table"]/tbody/tr['+week+']/td['+day+']/h2/span[2]'
max_temp_path = '//*[@id="table"]/tbody/tr['+week+']/td['+day+']/div[1]/p/span[1]'
min_temp_path = '//*[@id="table"]/tbody/tr['+week+']/td['+day+']/div[1]/p/span[2]'
date = driver.find_element_by_xpath(day_path)
date = date.text
try:
date_int = int(date)
except(ValueError):
break
if month_input == '':
month = self.month
else:
month = month_input
if date_int == 01 and week_index != 2:
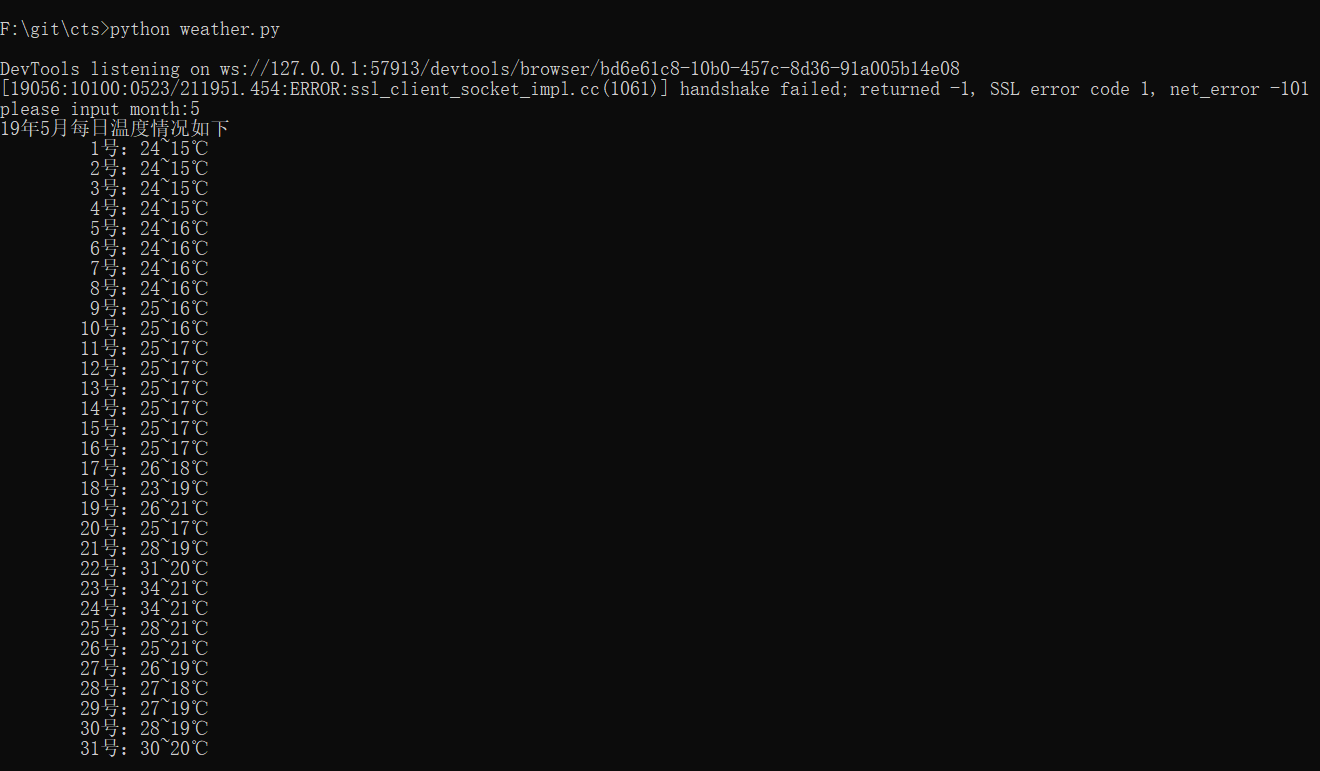
print u'19年{}月每日温度情况如下'.format(month)
break
max_temp = driver.find_element_by_xpath(max_temp_path)
min_temp = driver.find_element_by_xpath(min_temp_path)
max_temp = re.findall('\d+', max_temp.text)
min_temp = re.findall('\d+', min_temp.text)- 循环获取数据
- 创建日期,最高温,最低温的xpath路径
- 获取路径里的文本信息
- 路径获取不到正确的信息或者匹配到下个月的1号就跳出循环
- 用正则把温度中的数字取出来
emm这里就是爬数据处理数据的主要逻辑了,因为天气预报上40天的显示是按日历来的,跟周数,星期数相关,于是这里用了嵌套的循环,但是因为月份的不同,周数有变化,我这里就写死range(2,8)(html数据从2开始到6或者7,range不包括8),有的月份没有第6周会获取不到元素的时候,强行int会报ValueError,等捕捉到这个错就是数据已经全部获取完可以break了。这里我用字典(key=value)存放日期和温度的对应,因为字典的key是唯一的,所以即使会获取到上个月30号的温度,也会被覆盖。这里还有个问题就是温度显示方式有多种,因此获取温度的xpath不是唯一的,于是我把这部分用try包起来,except捕捉到异常后用另一个xpath去获取,直到取到数据。详见下图

if __name__ == '__main__':
weather = Weather()
dict,month = weather.get_weather_html()
count = 0
for key in dict.keys():
monthRange = calendar.monthrange(2019, int(month))
print u"{name:10d}号:{max}~{min}℃".format(name=key,max=dict[key][0],min=dict[key][1])
count += 1
if count == monthRange[-1]:
break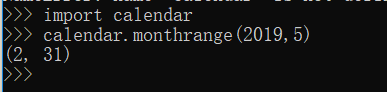
最后我们就可以创建类实例,运行方法,打印数据了。提醒下cmd下运行的话,中文字符前要加个u转成Unicode,不然会报错。下图就是最后的运行结果啦。
其实获取html的方法有很多种页面获取方法,我一开始用了urllib和request都失败了,因为天气预报的页面是动态加载的,而这两个库只能帮助我们获取静态页面,然后我就想试试自己模拟请求,实现动态加载,无奈才疏学浅,最后只能用万能牌selenium。selenium会模拟用户操作,真的在你电脑上打开浏览器然后点点点,这样虽然万能,但是就很慢呐。 以上就是我代码的大部分了,源码的话可以去我的github获取。