先在中国天气网中搜索南京天气,打开南京天气页面,从地址栏中的的到url,按F12,选择Elements

在Elements中移动鼠标,查找天气内容所在div:

展开div后,可以看到每天的天气信息就在ul下的li中.
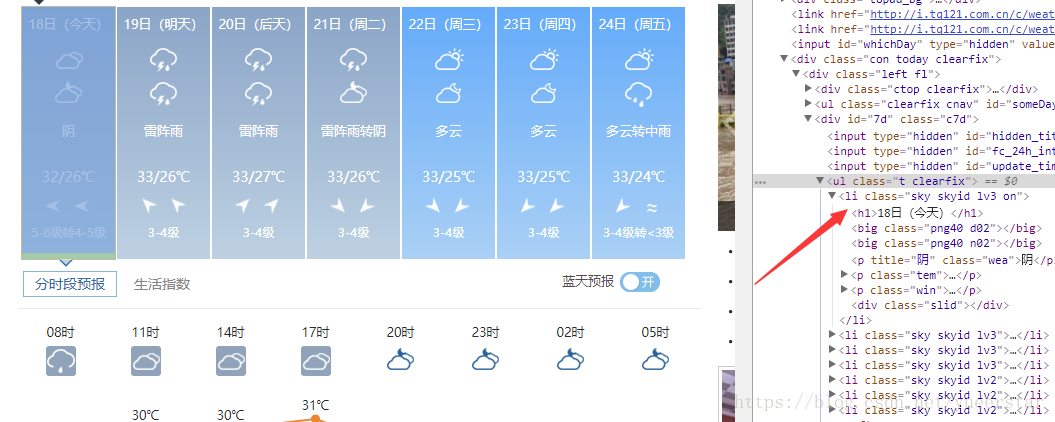
所以,整体思路就是:
1.先根据url拿到整个页面的内容.
2.在内容中,先找到对应的div,然后再找到对应的ul,最后遍历所有的li拿到天气信息.
代码如下:
import requests
import bs4
#获取网页内容
def get_content(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'}
try:
html = requests.get(url, headers = headers)
html.encoding = "utf-8"
content = html.text
except Exception as e:
print(e)
return None
return content
#从网页内容中获取天气信息
def get_weather(content):
final = []
bs = bs4.BeautifulSoup(content, "lxml")
data = bs.find("div",{"id":"7d"}) #先找到对应的div
ul = data.find("ul") #再从div中找到ul
li = ul.find_all("li") #从ul中获取所有li
#遍历li,拿到每天的天气信息.
for day in li:
temp=[]
date=day.find("h1").string
temp.append(date)
inf=day.find_all("p")
temp.append(inf[0].string)
if inf[1].find("span") is None:
temperature_high=None
else:
temperature_high = inf[1].find("span").string
temperature_high = "最高温度: " + temperature_high
temperature_lower = inf[1].find("i").string
temperature_lower = temperature_lower.replace("℃","")
temperature_lower = "最低温度: " + temperature_lower
temp.append(temperature_high)
temp.append(temperature_lower)
final.append(temp)
return final
if __name__=="__main__":
url = "http://www.weather.com.cn/weather/101190101.shtml"
content = get_content(url)
if content is None:
print("get content fail")
else:
weather = get_weather(content)
print("南京天气:")
for we in weather:
print(we)
运行结果:
