一、JDK安装配置
(一)为什么要安装JDK
由于Eclipse 是基于 Java 开发的一个可扩展的开发平台,所以在安装 Eclipse 前需要确保你的电脑已经成功安装了JDK。
(二)如何安装配置JDK
1、配置JDK的环境变量
(1)点击“计算机”,然后“右键”——“属性”——“高级系统设置”——“环境变量”,如下图所示:
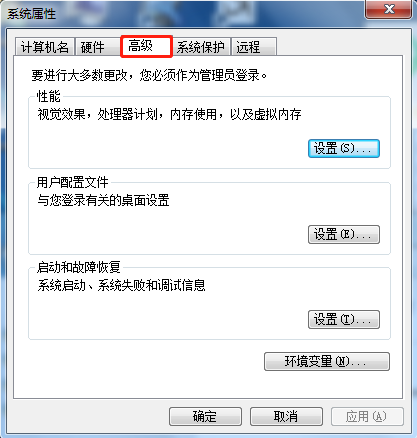
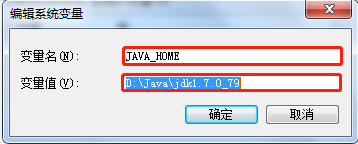
(2)配置系统变量JAVA_HOME,即配置JDK的安装目录。
(3)配置系统变量Path,即配置JDK安装目录的bin目录。

2、验证JDK是否安装成功
如果出现以下结果,说明jdk配置成功。

二、安装部署Eclipse开发环境
安装Eclipse
(1)双击Eclipse安装包,将看到如下界面。然后选择“Java Developers”,满足基本的java开发即可。

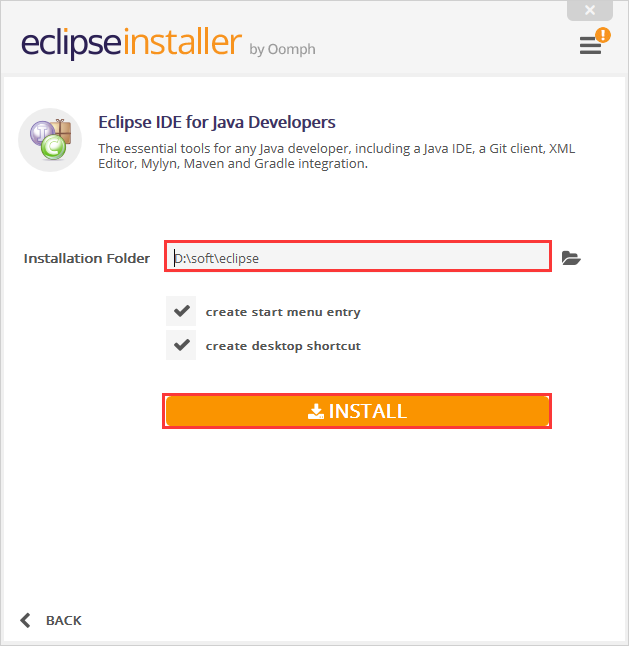
(2)在如下界面选择Eclipse的安装路径,然后点击“INSTALL”即可。
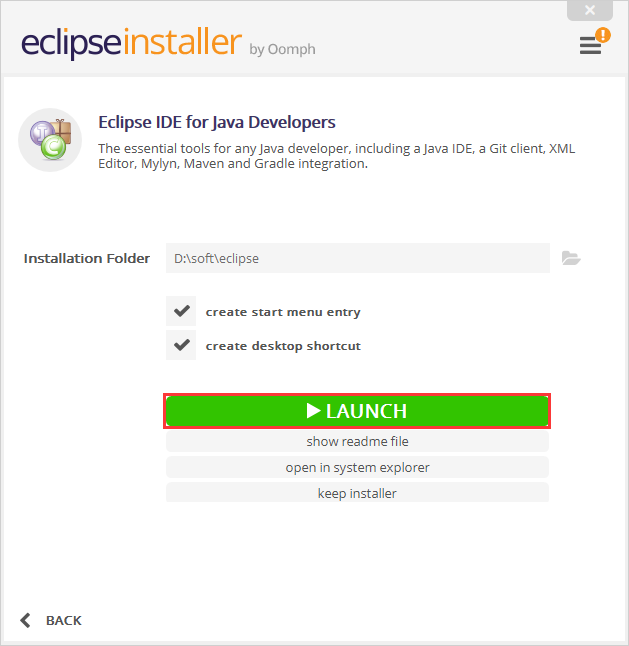
(3)在如下界面点击“LAUNCH”,然后就正式开始安装。
(4)在如下界面选择项目的工作空间,可以使用默认的路径和工作空间,也可以选择其他工作空间。勾选“Use this as the default and do not ask again”,然后点击“OK”即可。
(5)如下界面就是Eclipse的欢迎界面,并没有实际作用,只需要关闭“Welcome”窗口即可。
(6)如下界面就是开发者真正需要使用的界面了。
(三)创建java项目,验证Eclipse开发环境是否部署成功
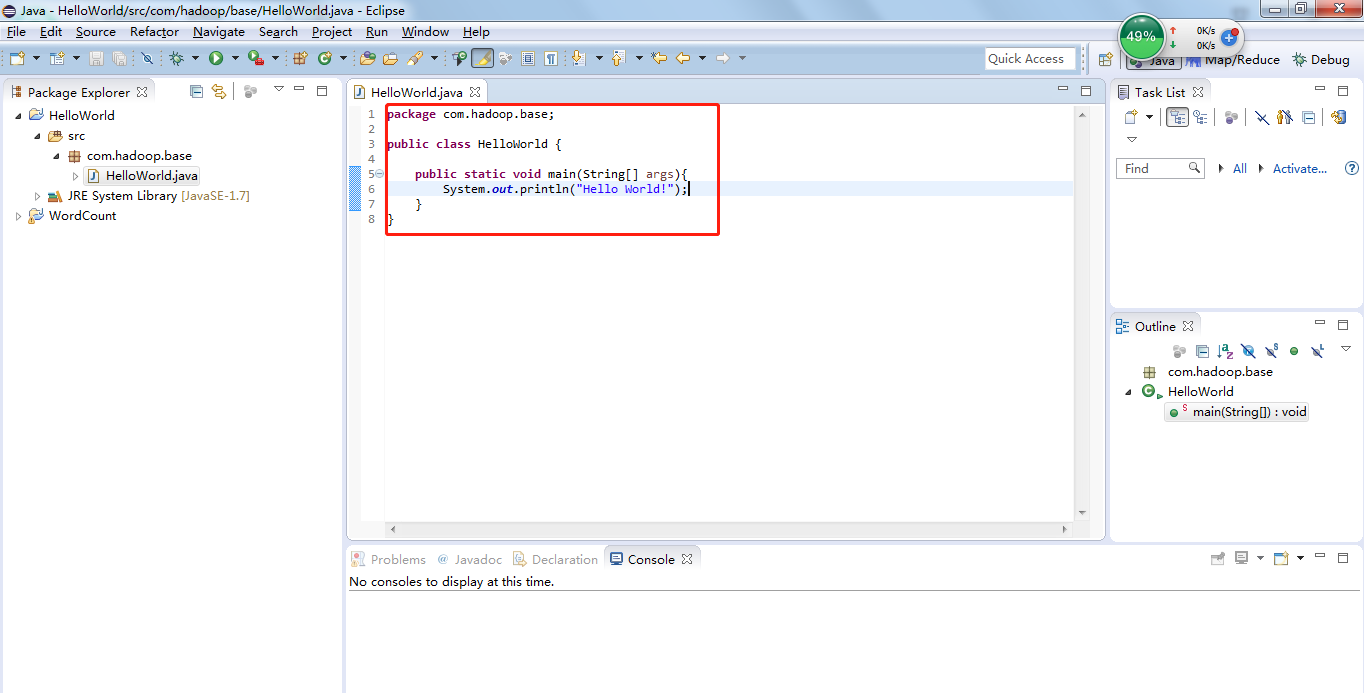
(1)创建一个HelloWorld的项目。
(2)在项目下创建一个包com.hadoop.base。

(3)在包中创建一个类HelloWorld。

(4)在类中编写如下代码并运行,如果能正确输出结果则表明Eclipse开发环境已经搭建成功,接下来开发者就可以正常开发普通的java项目了。
三、构建MapReduce项目
通过安装对应版本的Hadoop-Eclipse插件,即可显示对应的MapReduce项目选项。然后就可以像创建普通的java项目一样创建MapReduce项目了。
(一)Hadoop-Eclipse插件的安装配置
(1)点击对应版本的Hadoop-Eclipse插件
(2)将插件放到Eclipse安装目录下的dropins目录中
(3)然后重启Eclipse
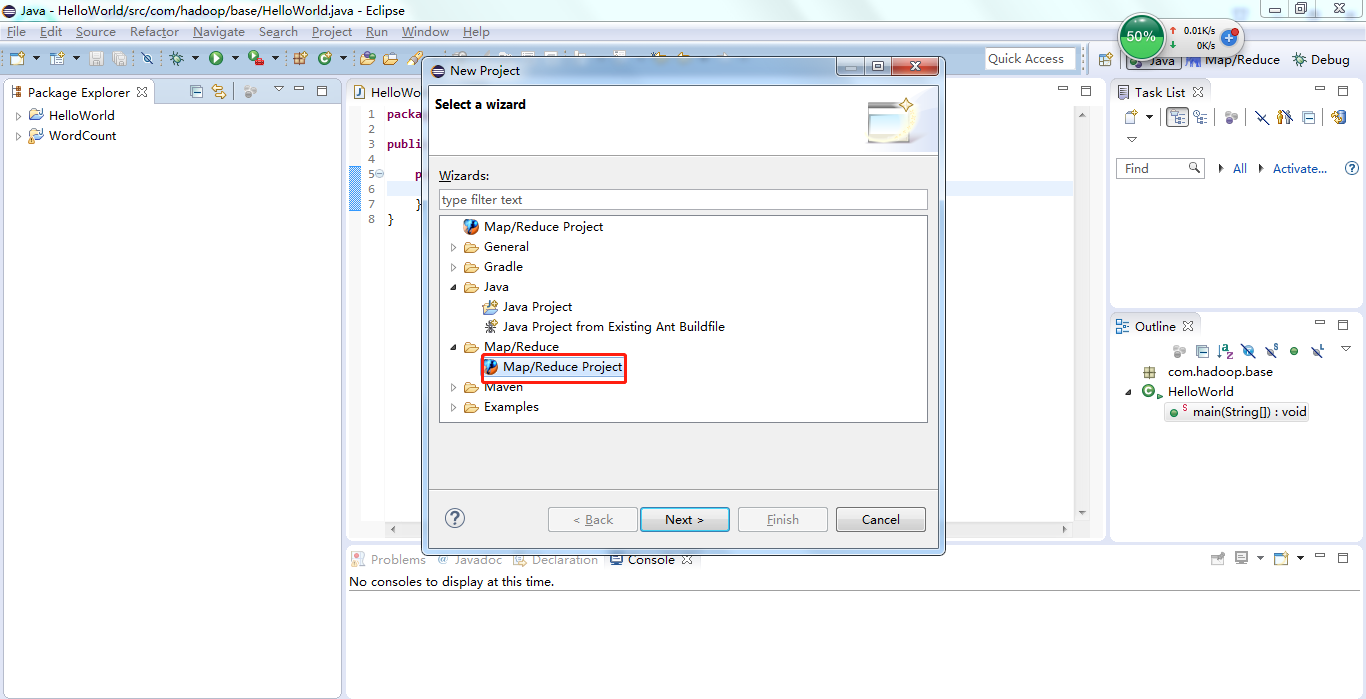
(4)创建MapReduce项目
如果插件安装成功,那么在新建项目选择时就会显示MapReduce项目。如下图所示:
(5)创建一个WordCount的项目,然后配置Hadoop安装目录。因为Hadoop-Eclipse插件一边连接着Eclipse,另一边连接着Hadoop,所以还要在Eclipse中对Hadoop进行相关的配置。

(6)配置Hadoop安装目录。
需要把下载到本地的hadoop安装包解压(就是提前下载到本地,上传到Linux虚拟机上的Hadoop安装包,因为Hadoop安装包是不分Linux或windows操作系统的)。然后配置Hadoop安装路径即可。然后点击“Apply”和“OK”。
注意:指定路径指定的是hadoop解压之后的那个文件夹的位置。而不是其他。

(7)在跳转的如下界面中点击“Finish”即可。

(8)在跳转的如下界面中点击“Yes”即可。

(二)Hadoop-Eclipse插件的作用
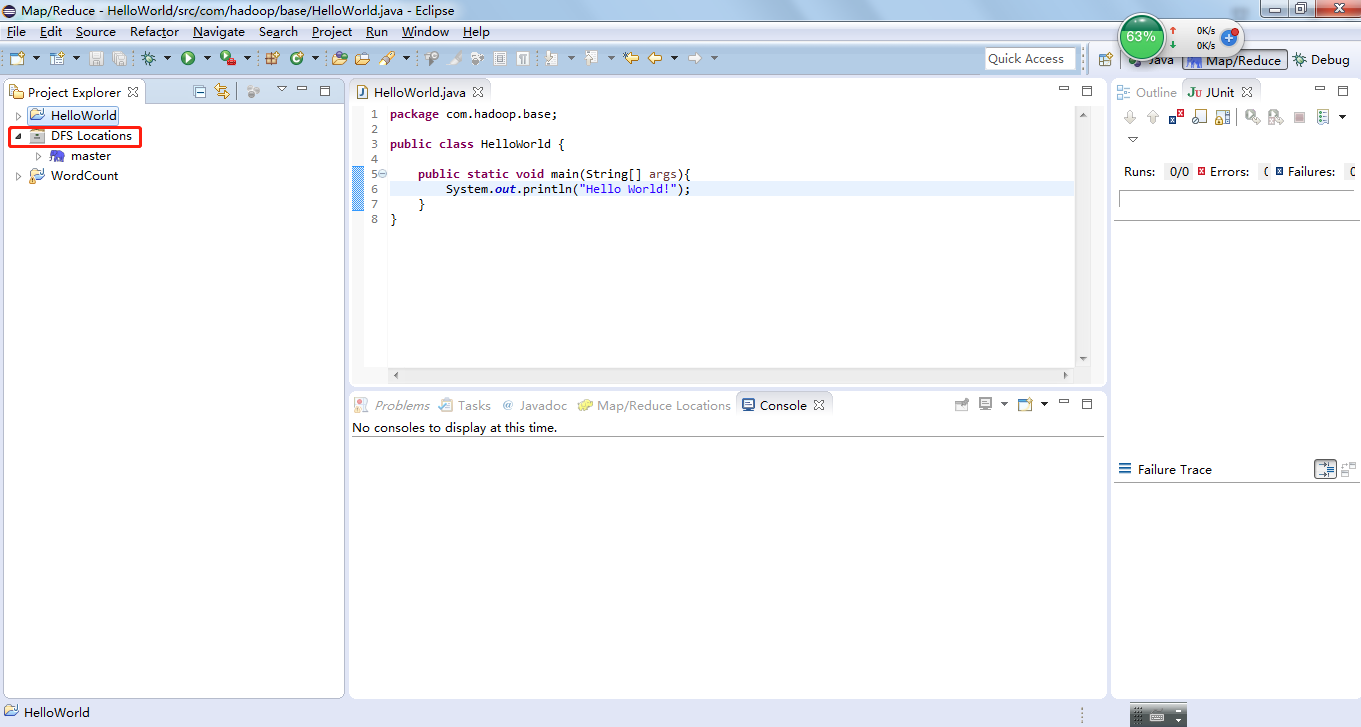
(1)在Eclipse中显示DFS Locations
如果以上配置都成功之后,那么在Project Explorer就会多了一个DFS Locations.窗口。这是安装Hadoop-Eclipse的第一个作用。DFS Locations的作用是在Eclipse中显示HDFS文件系统的列表,但是由于还需要启动Hadoop集群,并进行相关连接的配置,比较麻烦且容易出错。
(2)项目自动导入MapReduce相关的依赖包
安装完Hadoop-Eclipse插件之后,创建的MapReduce项目会自动导入hadoop相关的依赖包,而无需手动创建。
(三)创建一个WordCount类,验证Eclipse是否可以成功开发MapReduce项目
(1)WordCount代码可以直接从官网上下载
http://hadoop.apache.org/docs/r2.6.0/hadoop-mapreduce-client/hadoop-mapreduce-client-core/MapReduceTutorial.html#Example:_WordCount_v1.0
(2)准备输入数据源(自己可以创建一个文件,然后随便写几条数据),并指定输入输出路径。
注意:一定要保证输入路径存在且正确,输出路径不能提前存在,否则代码运行将会报对应的错误,然后运行代码。(具体操作可参照本任务对应的视频内容)
(3)代码运行常见错误及解决方法
1)报log4j问题
只需要在src中导入log4j文件即可。
2)然后再运行报如下错误:

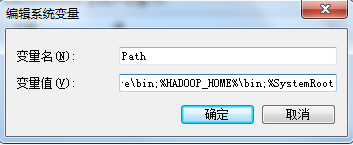
错误原因:hadoop环境变量没有配置或配置有问。
解决办法:只需要配置并检查HADOOP_HOME和Path变量即可。如下所示:

3)重启Eclipse,重新运行之后又报如下错误:

错误原因:本地Hadoop运行目录的bin目录下中没有winutils.exe或者32位/64位版本不匹配
解决办法:下载相应的winutils.exe和hadoop.dll放到Hadoop运行目录的bin文件夹下,注意选择正确的32位/64位版本把对应版本的那两个文件放到hadoop安装目录的bin目录下即可。
然后重新Eclipse并运行WordCount,发现就没有问题了。(包括前边报的空指针异常也一并解决了)
4)有时候还会出现一些其他问题:

解决方法:把winutils.exe和hadoop.dll这两个文件上传到C:\Windows\System32目录下,重新运行代码即可。
到此为止,Eclipse开发MapReduce项目就部署成功