初出茅庐----程序测试与爬虫
一、对程序进行测试
测试采用体育竞技模拟分析程序代码
测试一个函数:
代码实现如下
1 def gameover(a,b):
2 if a>=11 and (a-b)>=2:
3 print(a)
4 if b>=11 and (b-a)>=2:
5 print(b)
6 try:
7 gameover()
8 except:
9 print("error")
10
11 a,b=eval(input("请输入测试值:"))
12 gameover(a,b)
结果如图所示(只有输入的数据准确,才会输入数值)
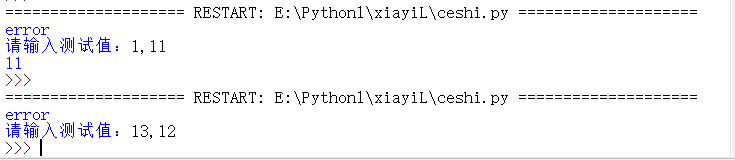
测试多组数据:(暂时不懂)
二、爬虫-----request库
1.request库的安装
在命令行输入pip install request,即可自动下载安装
2.request的使用
(1)request库的网页请求函数
| 函数 | 描述 |
| get(url[,timeot=n]) | 对应于HTTP的GET方式,获取网页最常用的方法,可以增加timeout=n参数,设定每次请求超时时间为n秒 |
| post(url,data={'key':'value'}) | 对应于HTTP的POST方式,其中字典用于传递客户数据 |
| delete(url) | 对应于HTTP的DELETE方式 |
| head(url) | 对应于HTTP的HEAD方式 |
| option(url) | 对应于HTTP的OPTIONS方式 |
| put(url,data={'key':'value'}) | 对应于HTTP的PUT方式,其中字典用于传递客户数据 |
(2)respomse对象的属性
| 属性 | 描述 |
| status_code | HTTP请求的返回状态,整数,200表示连接成功,404表示失败 |
| text | HTTP响应内容的字符串形式,即url对应的网页内容 |
| encoding | HTTP响应内容的编码方式 |
| content | HTTP响应内容的二进制形式 |
(3)response对象的方法
| 方法 | 描述 |
| json() | 如果HTTP响应内容包含json格式数据,则该方法解析json数据 |
| raise_for_status() | 如果不是200,则产生异常 |
3.牛刀小试
1.用request库爬取百度网页内容,并且打印20次
代码实现如下
1 import requests
2 def gethtmltext(url):
3 try:
4 r=requests.get(url,timeout=30)
5 r.raise_for_status()
6 r.encoding='utf-8'
7 return r.text
8 except:
9 return ""
10
11 url="https://www.baidu.com"
12 for i in range(20):
13 print(gethtmltext(url))
结果如图所示(由于打印的内容比较多,这里就不一一展示了)

2.计算text属性和content属性所返回网页内容的长度
代码实现如下
1 import requests
2 def gethtmltext(url):
3 try:
4 r=requests.get(url,timeout=30)
5 r.raise_for_status()
6 r.encoding='utf-8'
7 return len(r.text),len(r.content)
8 except:
9 return ""
10
11 url="https://www.baidu.com"
12 print(gethtmltext(url))
结果如图所示
![]()