第三次作业整个是关于JML的。名为JML,实为数据结构、内存占用与算法
虽然说JML的事情我还不是很明白,但是梳理一下JML语言相关的内容吧
JML语言的理论基础和应用工具链
我总觉得jml好像还不是那么的出名,基本上查阅到的资料也就是在一些学术论文里找到的...
转载至https://www.sciencedirect.com/science/article/pii/S0167642315000398
JML 是一种针对Java定制的行为接口规范语言。它得到了各种验证和测试工具的支持。但是,根据使用的两种方法中的哪一种,语言的使用方式不同。这通常会导致规范与其他方法不兼容。L. du Bousquet等人。使用JML编写,通常也不能用于其他目的。然而,由于它们的互补优势,两种方法的结合很重要。例如,与形式验证不同,测试还考虑由软件和硬件组成的执行环境; 软件修改后,可以快速重复回归测试; 测试擅长检测错误; 但与验证不同,它通常无法证明实现的正确性。由于对整个系统的严格验证通常是不可行的,因此可以通过验证程序的一部分和测试另一部分来组合验证和测试。考虑在该方法的情形甲调用方法乙,验证被施加到甲和测试被施加到乙。因此,方法B的说明扮演两种方法之间的接口角色,因为对B的调用被其规范(即契约)所取代。在另一种方案中,方法C调用方法D,用户想要测试方法C并验证方法D和运行时检查它。只有当被调用者的规范与测试和验证兼容时,这两种情况才有可能。通常,测试的代码量大于验证的代码量。但是,由于验证是一项更加困难的任务,因此本文将更多地关注验证。
在写的时候一般分为行注释和块注释,具体实例如下:
//@ ensures \result == nodes.length;
/*@ requires index >= 0 && index < size();
@ assignable \nothing;
@ ensures \result == nodes[index];
@*/
核心主要包括前置条件,后置条件与副作用范围的限定
常用的语句如下
\result:即方法执行后的返回值。\result表达式的类型就是方法声明中定义的返回值的类型。
\old(expr):顾名思义即之前在这里对应的内容数据
\forall:可理解为“任意”,表示对于给定范围内的元素,每个元素都满足相应的约束。
\exists:顾名思义“存在”,表示对于给定范围内的元素,存在一个元素满足相应的约束。
\sum:返回给定范围内表达式的和,例如:(\sum int i; 0<=i && i< 5; i)得到的结果为0+1+2+3+4=10。
\max:返回给定范围内表达式的最大值。
\min:返回给定范围内表达式的最小值。
\nothing:表示一个空集,常常在副作用中使用,assignable \nothing表示这个方法没有副作用。
JML工具链
JML提供了很多工具,如OpenJML(规格正确性检查),SMT Solver(验证代码等价性,虽然这个不是很好做,要求挺严的),JMLUnitNG(自动生成数据验证正确性)
JMLUnitNG使用体验
体验感我认为奇差无比,不知道是因为什么原因,一开始要么就是自动忽略测试,要么就是无法识别jar包,我也就只能按照大佬给的单独的测试样例自己做一下了...
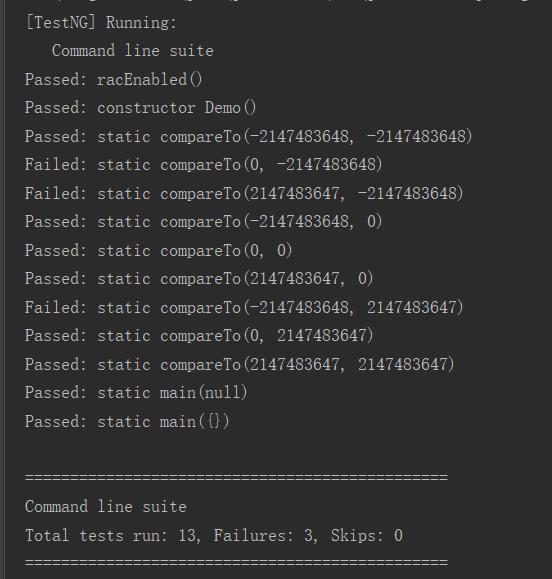
可以看出,基本上都是边界数据,比如0和int的上下限
fail的具体原因没怎么弄明白...
在生成的时候,JMLUnitNG会根据命令行的需求生成对应类的测试类
三次作业架构分析
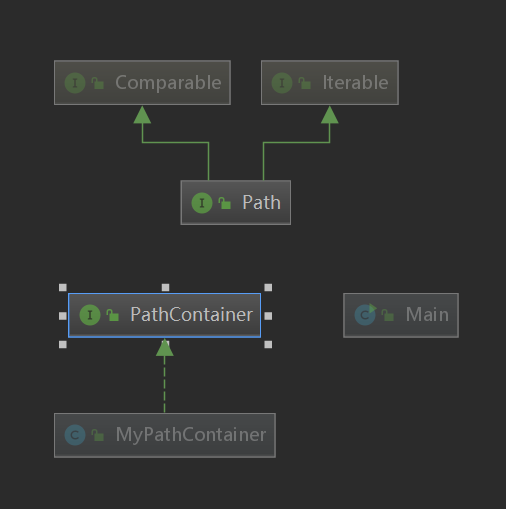
第一次作业就是很普通的情况,我自己一开始写的时候采用了arraylist,然后出现了很多致命的bug,弱测有很多东西测不出来导致强测十分的惨烈...
1.ArrayList寻址复杂度带log,所以说最后的几个测试样例直接TLE了
2.在CompareTo的实现中,完全照抄了String的,导致没有考虑数据溢出的情况,强行用加减判断在判断边界数据的时候(如2147483647和-2147483648)就会出现问题
3.在之前就有犯过的低级错误,在ArrayList等容器当中是绝对绝对不可以使用“==”的,一定要使用“equals”,具体的云因就在于一个需要相同地址,一个有专门的object类的equals方法
然后进行了一次重构
主要是采用了复杂度为O(1)的hashmap和hashset进行存储,并学习了其相应的方法
第二次的类图如下
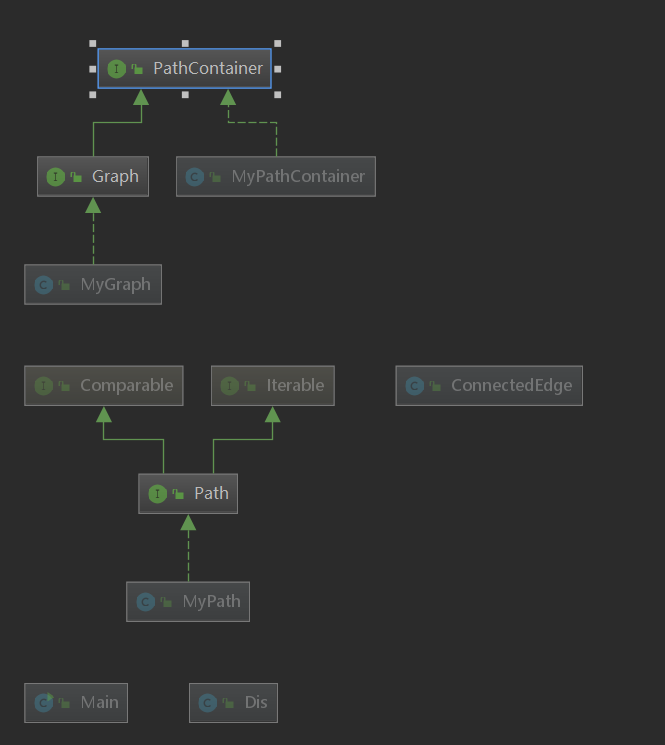
原本来说dis类也应该链接Graph的,因为Dis类是一开始专门建立用于存储点与点之间最短距离的类
在这里我选择全部使用HashMap容器对数据进行存储,也就是形成了一个稀疏矩阵的形式
在我构造的样例当中,虽然够6000行了,但是还是对于节点数较大的而言还是很成问题的,这一点我在自己构造测试样例的时候每一发现。所以后面10个点我还是TLE了(这次是真的没想到,强测的样例可以说是相当的狠毒了)
所以我进行了又一次重构,将邻接矩阵和结果采用静态二位数组和点id与数组下标的映射来表示
一直采用的是Dijkstra算法,在面对双向等权的图时基本不会出现问题
第三次就比较玄幻了,究极算法讨论。然而到最后发现,通过类似于网络流一样的构造方式,依旧可以将这个问题化作最简单的有向图最短路径问题。
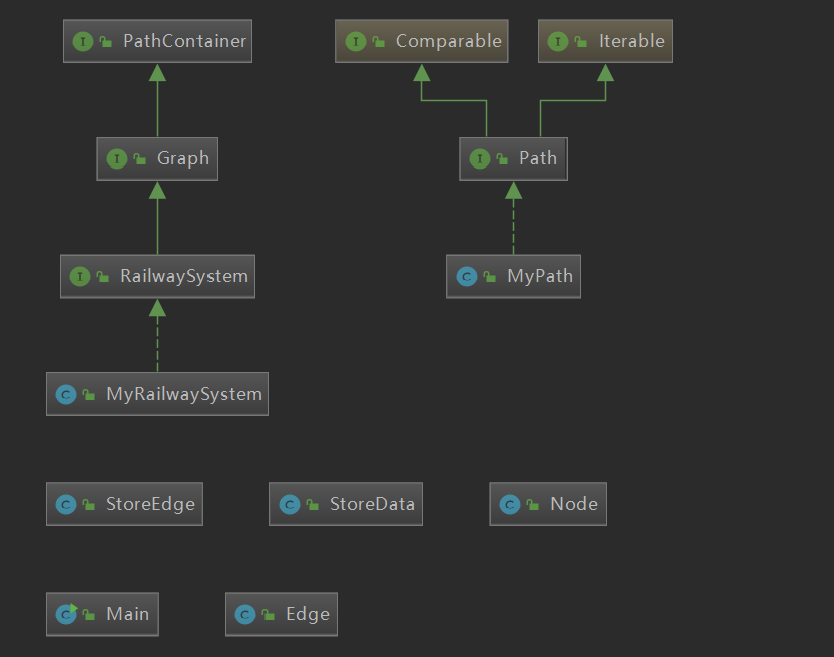
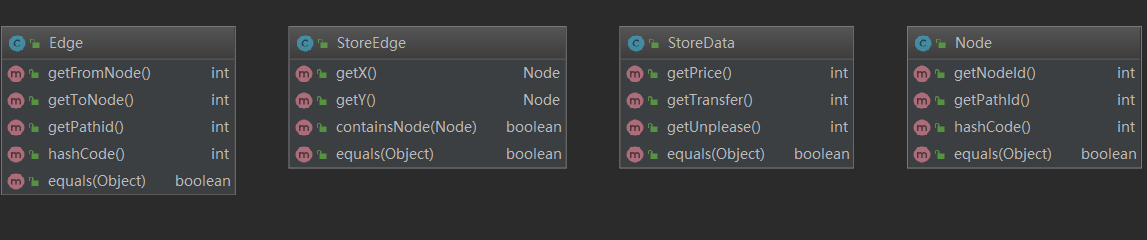
用于存储数据的几个附属类
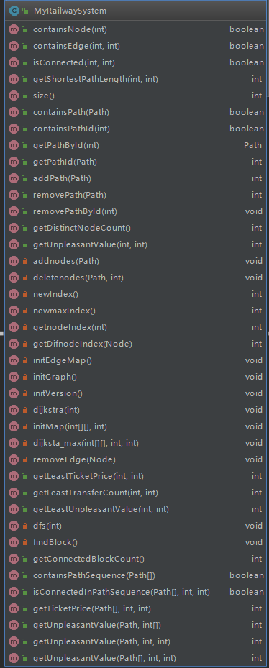
这个类是真的太长了,最后没有时间去简化,所以代码风格也很糟糕
Edge用来记录两个节点之间的距离,利用大佬的方法,将出现在不同的线路的相同站id区别对待,然后进行构造。而所有的点和边的信息,由于数据较大,经过权衡采取了HashMap进行存储。然后利用这些区别对待的点(类似于“网络”结构),进行最短路径的计算,可以同时满足这3个新增的需求(相应的,构造的3个矩阵都是4000+平方个节点,当然不能无脑统一初始化,还是要根据映射来进行的)
而连通块,我才用的就是无脑的dfs递归算法,只要能连成一圈即可。当然了,由于我采用的是静态的数组进行点之间的映射,所以没有启用的点是不可以加入运算当中的。
然而我还是犯了一个比较大的问题...而且是导致强测错了一堆点的致命错误:在删除点的时候需要判断是否已经删除过了,否则在同一路径出现同一个点,已经删除过之后,就会抛出异常...然后就比较凉,好歹最后几个还是对了,十分的幸运
炸的还真的不是算法和内存问题,由于这一次给的上限很高,所以我的程序就处于在TLE的边缘大鹏展翅的一个状态
Bug修复
关于这一点,刚才已经说得差不多了,虽然分数上这一单元确实不尽人意,但我个人觉得也算是熬过来了,也算是收获了很多东西。分数也不是最重要的东西。
在这一单元中,对于时间复杂度,不同容器的遍历方式,内存占用等多方面都有所涉及,进行权衡的过程确实是很棒的一个训练。另外,在构造测试样例,研究新的对拍方法等方式上,也是很不错的。
心得体会
在这一单元,我对于规格已经有了一个大致的了解。而且感觉这一次不用在作业中大批量的写JML,而是有已经写好的作为参照,感觉效果更好,JML自身在这个单元占的比重确实是恰到好处的。
尤其是在团队合作的时候,代码的风格习惯最好统一(这一点通过checkstyle可以做到一定程度上地使代码看上去比较清爽),在规格上也应当保持一致,不能因为不同人独自对整体工程有不同的了解,就导致做出来的项目四不像
然而关于JMLUnitNG的测试,我表示存疑。虽然大部分使用边界数据固然是好的,但是还是无法满足一般的需求和足够大的测试强度。关于这一点我个人还是倾向于自己采用一定随机数来进行构造。