第一部分 JML部分
·JML语言的理论基础
JML的全称是Java建模语言(Java Modeling Language),往上可以追溯到UML(Unified Modeling Language)统一建模语言。
这里既然已经提到建模,可以讨论一下模型的概念。借用百度百科的概念——通过主观意识借助实体或者虚拟表现构成客观阐述形态结构的一种表达目的的物件。
看起来很抽象,其实简而言之就是我们人类对现实世界的一种化简而出现的产物。建模便是建立一个这样的化简产物。建模语言完成的任务,是将具体的实现抽象成为一个简单的模型。它适用于系统开发过程中从需求规格描述到系统完成后测试的不同阶段。在建模分析时主要关心问题域中的主要概念(如抽象、类和对象等)和机制,需要识别这些类以及它们相互间的关系,并只对问题域的对象(待实现的功能)建模,而不考虑定义软件系统中技术细节的类(如处理用户接口等问题的类)。
在本单元所应用的JML,是UML的一部。在完成JML要求的过程中,我们发现它不需求任何具体的数据实现,仅仅要求完成指定的任务。很有面向对象的意味——各个类的数据和方法自己管理,但是必须满足相应需求;内部对外部不可见,外部只能使用内部提供的方法以获取需要的结果。
JML的优点在于:其一,它完全独立于代码,如同算法可以独立于代码(尽管二者不尽相同),代码需要根据JML的目标配合实现;其二,它可由逻辑验证正确,不存在二义性。它仅仅存在唯一满足要求的情况,如同函数中的单射,因而只要符合JML的规范,代码实现一定是正确的。
JML的全称是Java建模语言(Java Modeling Language),往上可以追溯到UML(Unified Modeling Language)统一建模语言。
这里既然已经提到建模,可以讨论一下模型的概念。借用百度百科的概念——通过主观意识借助实体或者虚拟表现构成客观阐述形态结构的一种表达目的的物件。
看起来很抽象,其实简而言之就是我们人类对现实世界的一种化简而出现的产物。建模便是建立一个这样的化简产物。建模语言完成的任务,是将具体的实现抽象成为一个简单的模型。它适用于系统开发过程中从需求规格描述到系统完成后测试的不同阶段。在建模分析时主要关心问题域中的主要概念(如抽象、类和对象等)和机制,需要识别这些类以及它们相互间的关系,并只对问题域的对象(待实现的功能)建模,而不考虑定义软件系统中技术细节的类(如处理用户接口等问题的类)。
在本单元所应用的JML,是UML的一部。在完成JML要求的过程中,我们发现它不需求任何具体的数据实现,仅仅要求完成指定的任务。很有面向对象的意味——各个类的数据和方法自己管理,但是必须满足相应需求;内部对外部不可见,外部只能使用内部提供的方法以获取需要的结果。
JML的优点在于:其一,它完全独立于代码,如同算法可以独立于代码(尽管二者不尽相同),代码需要根据JML的目标配合实现;其二,它可由逻辑验证正确,不存在二义性。它仅仅存在唯一满足要求的情况,如同函数中的单射,因而只要符合JML的规范,代码实现一定是正确的。
·JML的工具链
OPENJML用以检查JML的规范性。现在IDEA官方更新支持到18.2版本,更高的18.3和19.1是不支持的。因而引入该工具时需要从OpenJML官网下载并作为外置插件引入。
JMLUnit/JMLUnitNG可以自动生成测试代码。
JMLUnit/JMLUnitNG可以自动生成测试代码。
第三部分 部署JMLUnit/JMLUnitNG
在本地部署时没有成功实现,因而转为服务器部署并采用rsync指令同步本地和服务器文件。
由于作业中大量存在\exist和\forall指令,因此自己试写了一个简单的Demo作为测试。代码和JML如下图所示。
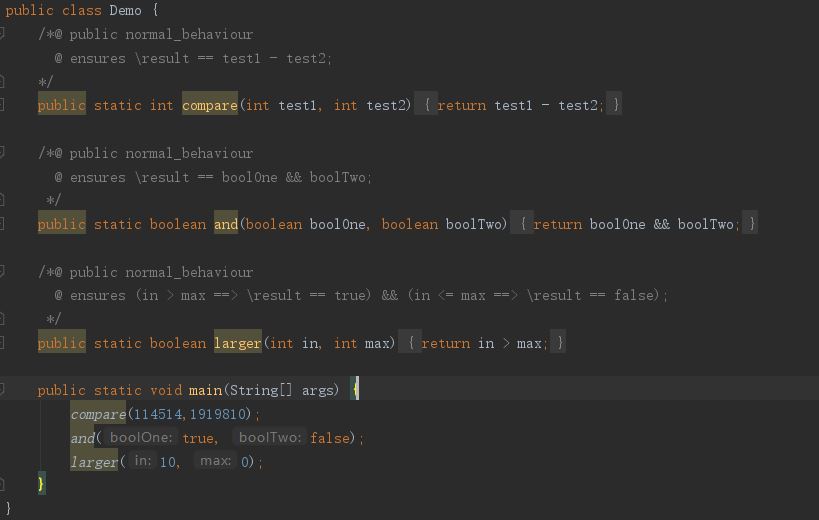
compare方法返回两个参数值之差;and方法返回量布尔值之积;larger方法判断前一参数是否比后一参数更大。自动生成的测试用例如下。
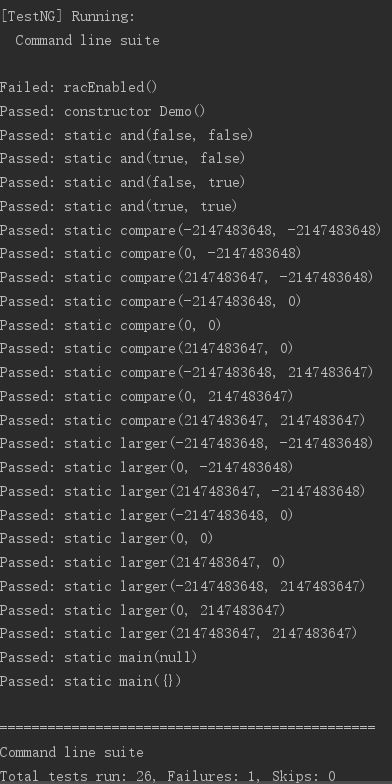
不难发现,boolean的测试覆盖了全部的四种可能,而数值测试则基本为测试边缘点,即0和int型的最大最小值。
采用该方法的好处是,自动生成检测样例,减省人工开销;相应的问题在于,测试的数据太富有规律性和极端性,不容易测出来一些小的可能性的错误,测试的数据错误是容易被考虑到的极端情况。因而以后做测试时,仍需加强自己的测试,不能仅仅依靠自动化工具。
第四部分 代码架构的分析
第九次作业
本次作业的内容非常简单。MyPath需要实现的功能仅需按部就班。这里采用的存储结构是ArrayList,把所有结点存入ArrayList即可,并根据要求返回查询值即可,没有特殊处理。MyPathContainer中也采用了ArrayList的结构用以存储Path和与之对应的Id。但是在进行查询对比时,时间复杂度比较高。举例而言,判断两条路径是否相等,平均的时间复杂度是O(mn),设m是路径平均长度,n是容器内路径条数。由于这类操作的时间复杂度非常高,导致后续测试时出现了很多问题。

第十次作业
本次作业对上回进行了难度增加。MyPath部分没有调整更改。Graph的内容发生了变化。针对上回时间复杂度过高的问题,果断采取了替换ArrayList为HashMap的操作,这样查询的时间复杂度可以瞬间骤降至O(1)。同时,增设类成员变量,在每次路径发生增减之后,更新成员变量内容(比如包含的点,点之间的关系等)。这样做的缺点是,更新原有内容会比直接新建内容复杂;优点是,可以大量节省时间(毕竟查询的指令数很大)。并且,将查询的中间过程(最短路径)一并记录,从而减少不必要的计算次数,以空间换时间(有点像莫斯科保卫战的方式,用苏联士兵换取莫斯科前线的土地,用前线土地换取后方部队的整备时间),从而缩短整体的运行时间开销。

第十一次作业
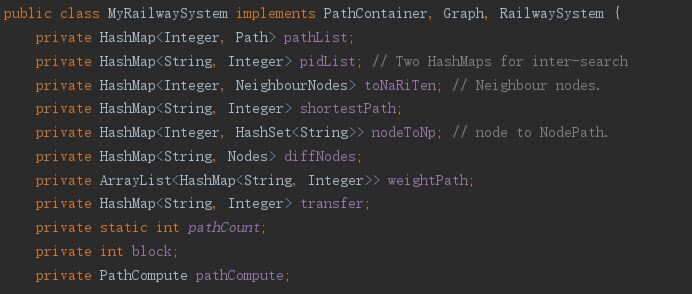
本次作业相对上次更加复杂,主要体现在换乘站的设计。在延续了上次作业的基础之上,保留了上回作业的绝大部分内容,本次作业采用了大量的HashMap,大量存储最短路径、邻接点等信息。由于邻接点存储内容复杂,我开启了数个HashMap并产生了嵌套关系,使得整个层次结构非常复杂。设计架构如下:采用<结点,结点>的存储方式,每个结点会存储该点的编号和该点所在的路径编号,同时在邻接表中存储结点的权值。在采用Dijkstra对所有权值进行遍历时,会遍历结点中不同的权值(这个是根据传入的参数决定的)。在做最低票价和最小不满意度遍历时,除去使用的权值不同之外,其它完全一致;而对最少换乘做遍历时,会根据自己定义的权值做适当的调整,同时会增设新的函数解决换乘次数的问题。
第五部分 问题和bug分析
第九次作业
很大的问题是时间复杂度的问题,由于没有采用HashMap等高速结构,使得一半的强测点超时。仅仅采用了ArrayList的数据存储结构,使得查找时仅能采用循环查找的方式,使得效率极低。
第十次作业
未在测试中被hack。
第十一次作业
在作业中出现了我认为不可能出现的WA,后来检查了一下发现均是同一个错误导致的,在后续的调整当中,发现仅需增加一行代码即可解决问题。然而,由于结构设计复杂,导致主要发生的问题是超时。看到一些其他的同学说没有什么超时问题我着实很羡慕,因为我自以为采用了HashMap的结构已经基本是最优的算法,但是测试时发现确实时间很长,发现其他人能用数组解决问题时,感觉不可思议。
第六部分 总结和感想
这回作业的主要问题在于超时。由于之前的程序設計对于时间的限制都没有很好体现,因而本次的时间的超出让我很不适应。也因此被扣了大量的分数。有一种以后OO课程组可以再多给一些提示的感觉,毕竟“萬事開頭難”,多一些指南可以帮助同学们少走一点不必要的弯路(嗯,是不必要的,而不是少走弯路)。
我个人感觉,本轮作业的收获不是很大(相较于前两单元而言),而且有一定的挫败感(尽管这种小小的失败是很好的抗压良方,也正如习总书记2014年在北大讲话时指出:不应出现,在顺境时,看山是山看水是水,在逆境时就看山不是山看水不是水了)。但是收获还是有的,毕竟学到了HashMap的使用方法,感受到了它的便利之处。同时也体会到了JML语言,认识到了这种形式化的强大性和其逻辑正确性。
本轮作业在后次作业基于前次代码的扩展自认为做的较上轮作业有进步,尽管第十次作业几乎重构了第九次作业的内容。还是需要学习保留更多的可扩展性原则,使得以后的代码构建更加清晰和简单。