第三单元JML地铁系统博客
第三单元JML地铁系统博客写在前面一、JML基础理论二、设计思路与架构第一次作业第二次作业第三次作业架构总结三、测试与bug情况Junit单元测试尝试使用OpenJML与JMLuniting进行自动测试关于debug四、总结与体会
写在前面
在近三周,我们进入了面向对象程序设计第三单元(根据JML编写地铁系统)。在本单元,我们首次接触了基于JML的规格模式的编程。规格化编程的核心是抽象,规格化的抽象是将用户的需求(函数功能)抽象出来,隐藏具体的实现细节。这是一种非常工程化的编程思想和方法,方便进行形式化的验证。
第三单元作业围绕Path相关的容器,从PathContainer 到 Graph 到 RailwaySystem,增量式设计,非常考验代码的构架好坏,并且对数据结构要求很高,需要我们进行数据结构的抽象,运用继承与接口实现代码的扩展,并且使用相关工具测试进行验证。下面我将梳理JML语言的基础理论,再介绍中的思路与代码架构,再介绍本单元JMLUnit进行测试情况,最后总结心得体会。
一、JML基础理论
JML是一种行为接口规范语言,可用于指定Java模块的行为 。它是结合了契约方法设计和Larch系列接口规范语言的规范方法。 通过使用JML,我们可以进行规格化的设计,代码实现人员的将不是可能带有内在模糊性的自然语言描述,而是逻辑严格的规格。可以提高代码的可维护性,使用各种工具进行自动测试及检测。
使用JML进行规格化设计,是以类为基本单位的,即用户一般把类作为一个整体来使用或重用。类的规格由数据规格与方法规格构成。数据规格规定了类所管理的数据内容,及其有效性条件;方法规格规定了类所提供的操作。开发人员必须确保实现数据内容始终有效,并且任何方法都满足方法本身所定义的规约且不能破坏数据的有效性。
对于数据来说,只需给出类所管理数据的最简单表达,并满足有效性条件,其中包括invariant:任何时刻数据内容都必须满足的约束条件;constraint:任何时刻对数据内容的修改都必须满足的约束条件。
对于方法来说,用户有义务保证提供有效的输入以及有效的对象状态,经过方法的执行用户能够获得满足确定条件的输出结果。方法执行过程中可能会修改用户对象的状态。对于方法的实现者来说规约由前置条件+后置条件+副作用组成。前置条件(requires)是实现者可依赖的初始条件,后置条件(ensures)是实现者要提供满足要求的结果,副作用(assignable)是方法执行过程中可能带来的变化。
对于类来说,对于JML的契约,类提供者信任使用者能够确保所有方法的前置条件都能被满足;类使用者信任设计者能够有效管理相应的数据和访问安全。任何一个类都要能够存储和管理规格所定义的数据,始终保持对象的有效性。类可以拒绝为选择自己的表示对象而不受外部约束,拒绝为不满足前置条件的输入提供服务。
从用户的角度来看,一个设计优良的类应保证操作的完整性(构造、更新、查询和生成),不提供与所管理数据无关的操作行为。并且能够以简单的方式访问和更新所管理的数据,保证数据(线程)安全,最重要的是类的实现与JML规定完全一致。
这种规格化的设计,致力于保证程序正确性的方法,即在规定的输入范畴内给出满足规定要求的输出。其基础就是规格满足需求,实现满足规格。为此我们使用基于JML 的规格模式,以规约逻辑对数据进行条件约束,不关心具体数据结构和实现方式。广泛采用层次化设计和组合机制,其核心是数据的抽象。
同时基于JML规格的设计也为我们提供了很多工具,比如使用OpenJML检查JML规范;使用JMLuniting进行自动测试等等一系列方法,是我们验证代码的有力武器。
二、设计思路与架构
通过阅读JML 规格可以发现本单元作业是在通过path(路径)建立graph(图),在实现基本操作(增、删、改、查)的基础上,进而进行不同应用(RailwaySystem地铁系统,带权最短路径查询)
本单元作业从PathContainer 到 Graph 到 RailwaySystem逐渐继承,需要良好的构架以支持增量式设计,下面我将介绍我在三次作业中构架的递进过程。
第一次作业
第一次作业中,PathContainer是对路径集合Path的封装容器,主要进行Path的增加与删除操作,每一条Path与一个固定的PathId对应,并且要记录PathContainer中的所有结点。所以我们需要建立Path与PathID之间的映射,存储存储所有节点。为此我构造了以下两个数据结构。
Dmap,里面存储了两个map,分别为PathId到Path和Path到PathId的映射。
1 private Map<K, Way> kmap = new HashMap<>(); 2 private Map<V, Way> vmap = new HashMap<>();
CountSet是一个有引用计数的Set,里面存储所有节点号及引用次数(在多少条Path中出现)
1 public class CountSet { 2 3 private Map<Integer, Integer> nodeSet = new HashMap<>(); 4 5 public int size() { 6 return nodeSet.size(); 7 } 8 9 public void add(int node) { 10 if (nodeSet.containsKey(node)) { 11 int count = nodeSet.get(node); 12 nodeSet.remove(node); 13 nodeSet.put(node, ++count); 14 } else { 15 nodeSet.put(node, 1); 16 } 17 } 18 19 public void remove(int node) { 20 int count = nodeSet.get(node); 21 if (count > 1) { 22 count--; 23 nodeSet.remove(node); 24 nodeSet.put(node, count); 25 } else if (count == 1) { 26 nodeSet.remove(node); 27 } 28 } 29 30 }
第二次作业
第二次作业中,Graph是一个图结构,要进行图中结点和边是否存在,结点是否相连,节点间最短路径的计算。
我第二次作业中MyGraph类继承于第一次作业中的MyPathContainer,并实现Graph接口

其中包含一个UndirGraph类的实例,这个类是无向图结构,存储所有与图有关的信息,其中具有LinkMat和disMat这两个实例,分别对应邻接矩阵和距离矩阵。包含的主要方法是实现对节点和边的增、删、改、查与连通性、最短路径的计算。linkMat存储着图的连通管理,disMat存储着图节点与节点间的最短路径长度(缓存,O(1)查询)
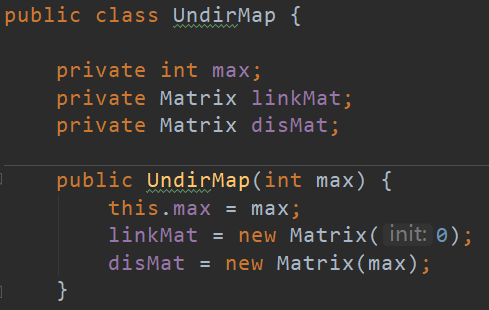
linkMat和disMat是Matrix类的实例,Matrix类当中封装了一个双HaspMap的结构,即Map<Integer,Map<Integer,Integer>>,并实现对此结构的相关操作。

第二次作业中,最复杂的一个方法是对最短路径的计算。由于是无权图,所以我选择了BFS算法(虽然起名字叫Dijk)进行实现,比较简洁。
1 private Map<Integer, Integer> singleDijk(int source) { 2 Map<Integer, Integer> map = new HashMap<>(); 3 for (Integer i : linkMat.getEleList()) { 4 map.put(i, max); 5 } 6 Queue<Integer> queue = new LinkedList<>(); 7 map.put(source, 0); 8 queue.offer(source); 9 while (!queue.isEmpty()) { 10 Integer top = queue.poll(); 11 for (Integer t : linkMat.getListOfA(top)) { 12 if (map.get(t) == max) { 13 map.put(t, map.get(top) + 1); 14 queue.offer(t); 15 } 16 } 17 } 18 return map; 19 }
第三次作业
第三次作业中,要实现一个RailwaySystem地铁系统,要支持多种标准(LeastTicketPrice、LeastTransferCount、LeastUnpleasantValue)的最短线路查询。分析此次作业,地铁系统实质上还是图结构,并且是有权图,对于每种查询标准,给予不同的不同的权值,进行有权最短路径的计算。
本次作业,我的MyRailwaySystem继承上次作业的MyGraph,进一步再建立三种不同标准的有权图。

因为要考虑换乘问题,所以在不同地铁线路上的同名结点可看做不同结点。所以每个结点应包括结点id和路径id两个信息。所以我封装了Node(只有nodeid)和RailwayNode(nodeid和pathid)两个类代替之前的Integer(nodeid信息)
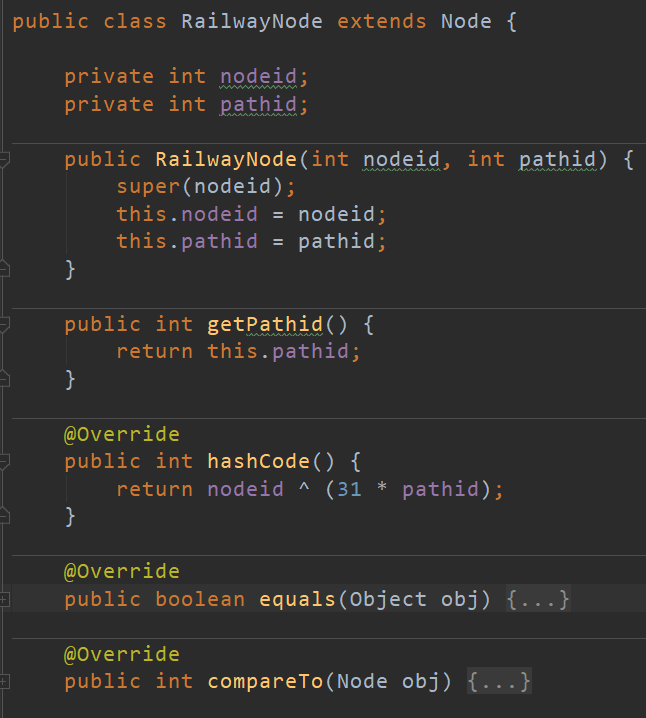
我构建RailwayGraph类继承无权图UndirGraph类,实现对地铁图的构建(改造),因为拆点的原因,我们需要在地铁图中重写addPath和removePath建立同名节点的联系,并且建立虚拟入口与出口,再实现带全路径的计算。
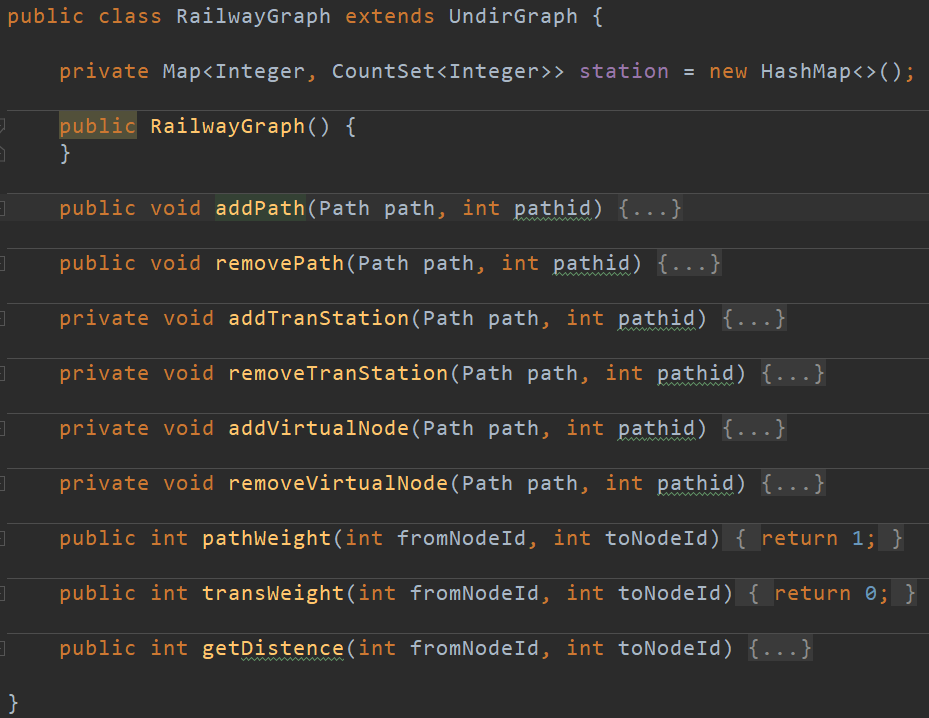
三种不同标准的地铁图,继承RailwayGraph类,并重写其中的路径权重和换乘权重,如下图所示。

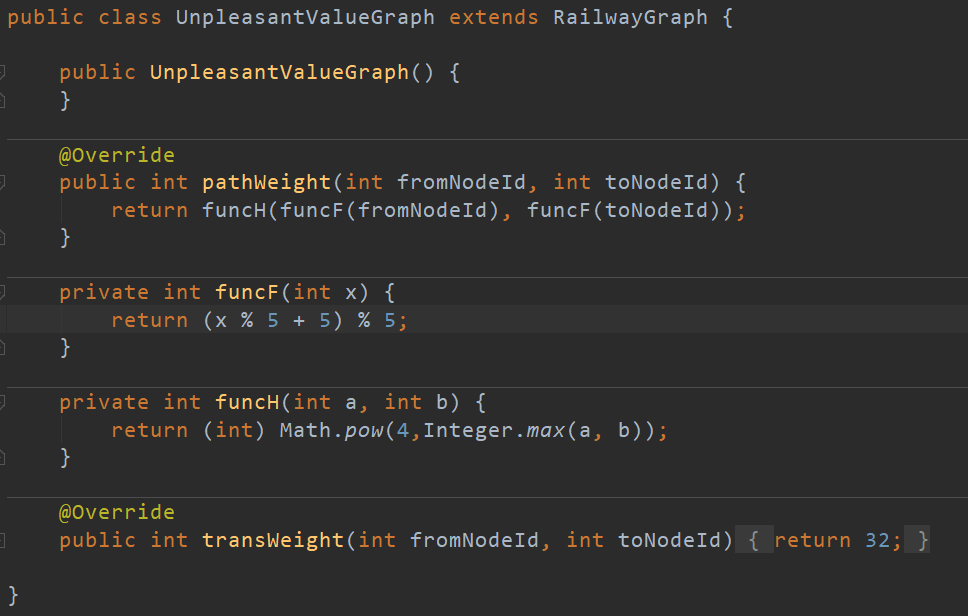
最后考虑最短路径的算法,我使用了堆优化的迪杰斯特拉算法,如下图所示。
1 public void calSingleShortPathLengthOfGraph(Node source) { 2 disMat.setLine(source, singleDijk(source)); 3 modified.remove(source); 4 } 5 6 private Map<Node, Integer> singleDijk(Node source) { 7 Map<Node, Integer> map = new HashMap<>(); 8 Set<Node> visited = new HashSet<>(); 9 class NodeDistance implements Comparable<NodeDistance> { 10 11 private final Node node; 12 private final int distance; 13 14 private NodeDistance(Node node, int distance) { 15 this.node = node; 16 this.distance = distance; 17 } 18 19 @Override 20 public int compareTo(NodeDistance o) { 21 return Integer.compare(this.distance, o.distance); 22 } 23 24 public Node getNode() { 25 return this.node; 26 } 27 28 } 29 30 for (Node i : nodeList) { 31 map.put(i, max); 32 } 33 PriorityQueue<NodeDistance> queue = new PriorityQueue<>(); 34 map.put(source, 0); 35 queue.offer(new NodeDistance(source, map.get(source))); 36 while (!queue.isEmpty()) { 37 Node top = queue.poll().getNode(); 38 if (visited.contains(top)) { 39 continue; 40 } 41 visited.add(top); 42 if (top instanceof RailwayNode) { 43 if (((RailwayNode) top).getPathid() == Integer.MAX_VALUE) { 44 continue; 45 } 46 } 47 for (Node t : linkMat.getListOfA(top)) { 48 if (!visited.contains(t) && 49 map.get(t) > map.get(top) + weightMat.get(top, t)) { 50 map.put(t, map.get(top) + weightMat.get(top, t)); 51 if (!visited.contains(t)) { 52 queue.offer(new NodeDistance(t, map.get(t))); 53 } 54 } 55 } 56 } 57 return map; 58 }
架构总结
总体来说,我的三次作业基本满足增量式的设计模式,不断扩展与继承。PathContainer <-- Graph <-- RailwaySystem,UndirGraph<--RailwayGraph<--priceGraph/transferGraph/satisfactionGraph。并且我对一些数据结构(Dmap,CountSet,Matrix)进行了封装,使每个类的功能更加明确,架构更为清晰。
但是我每次在架构的设计当中,是存在考虑不足的问题,比如设计为无向图而非有向图,一开始没考虑权重,最短路径算法的选择等等都是等下一次作业的需求出现才做更改的,没有预先设计好。并且,我的扩展比较硬性,没有运用很多可以复用的中间变量,比如说最后一次作业中的三个新图的邻接矩阵应该是相同的,只有权重矩阵不同,但我构建了三遍,造成了一些冗杂,拖慢了一些运行的效率。我认为经过OO面向对象课程的学习,我面向对象的思想和代码构架能力有了一定的提高,但考虑还不够全面,需要进一步提高和细节上的优化。下面是我整个单元作业的价格UML图。

三、测试与bug情况
Junit单元测试
在本单元,我还联系使用了junit进行单元测试,在每一单元对新增模块编写了junit单元测试数据。
尝试使用OpenJML与JMLuniting进行自动测试
我写了两个简单方法的JML及其实现,分别为是计算两个数中比基础值大的数的个数。练习使用OpenJML与JMLuniting配合进行测试。
方法如下:
1 /*@ public normal_behaviour 2 @ ensures (first > base) && (second > base) ==> (\result == 2); 3 @ ensures (first > base) && (second <= base) ==> (\result == 1); 4 @ ensures (first <= base) && (second > base) ==> (\result == 1); 5 @ ensures (first <= base) && (second <= base) ==> (\result == 0); 6 */ 7 public static int countBigger(int base, int first, int second) { 8 int result = 0; 9 if (first > base) { 10 result++; 11 } 12 if (second > base) { 13 result++; 14 } 15 return result; 16 } 17 18 /*@ public normal_behaviour 19 @ ensures (first >= base) && (second >= base) ==> (\result == 0); 20 @ ensures (first >= base) && (second < base) ==> (\result == 1); 21 @ ensures (first < base) && (second >= base) ==> (\result == 1); 22 @ ensures (first < base) && (second < base) ==> (\result == 2); 23 */ 24 public static int countSmaller(int base, int first, int second) { 25 int result = 0; 26 if (first < base) { 27 result++; 28 } 29 if (second < base) { 30 result++; 31 } 32 return result; 33 }
测试结果如下:
1 [TestNG] Running: 2 Command line suite 3 4 Failed: racEnabled() 5 Passed: constructor Demo() 6 Passed: static countBigger(-2147483648, -2147483648, -2147483648) 7 Passed: static countBigger(0, -2147483648, -2147483648) 8 Passed: static countBigger(2147483647, -2147483648, -2147483648) 9 Passed: static countBigger(-2147483648, 0, -2147483648) 10 Passed: static countBigger(0, 0, -2147483648) 11 Passed: static countBigger(2147483647, 0, -2147483648) 12 Passed: static countBigger(-2147483648, 2147483647, -2147483648) 13 Passed: static countBigger(0, 2147483647, -2147483648) 14 Passed: static countBigger(2147483647, 2147483647, -2147483648) 15 Passed: static countBigger(-2147483648, -2147483648, 0) 16 Passed: static countBigger(0, -2147483648, 0) 17 Passed: static countBigger(2147483647, -2147483648, 0) 18 Passed: static countBigger(-2147483648, 0, 0) 19 Passed: static countBigger(0, 0, 0) 20 Passed: static countBigger(2147483647, 0, 0) 21 Passed: static countBigger(-2147483648, 2147483647, 0) 22 Passed: static countBigger(0, 2147483647, 0) 23 Passed: static countBigger(2147483647, 2147483647, 0) 24 Passed: static countBigger(-2147483648, -2147483648, 2147483647) 25 Passed: static countBigger(0, -2147483648, 2147483647) 26 Passed: static countBigger(2147483647, -2147483648, 2147483647) 27 Passed: static countBigger(-2147483648, 0, 2147483647) 28 Passed: static countBigger(0, 0, 2147483647) 29 Passed: static countBigger(2147483647, 0, 2147483647) 30 Passed: static countBigger(-2147483648, 2147483647, 2147483647) 31 Passed: static countBigger(0, 2147483647, 2147483647) 32 Passed: static countBigger(2147483647, 2147483647, 2147483647) 33 Passed: static countSmaller(-2147483648, -2147483648, -2147483648) 34 Passed: static countSmaller(0, -2147483648, -2147483648) 35 Passed: static countSmaller(2147483647, -2147483648, -2147483648) 36 Passed: static countSmaller(-2147483648, 0, -2147483648) 37 Passed: static countSmaller(0, 0, -2147483648) 38 Passed: static countSmaller(2147483647, 0, -2147483648) 39 Passed: static countSmaller(-2147483648, 2147483647, -2147483648) 40 Passed: static countSmaller(0, 2147483647, -2147483648) 41 Passed: static countSmaller(2147483647, 2147483647, -2147483648) 42 Passed: static countSmaller(-2147483648, -2147483648, 0) 43 Passed: static countSmaller(0, -2147483648, 0) 44 Passed: static countSmaller(2147483647, -2147483648, 0) 45 Passed: static countSmaller(-2147483648, 0, 0) 46 Passed: static countSmaller(0, 0, 0) 47 Passed: static countSmaller(2147483647, 0, 0) 48 Passed: static countSmaller(-2147483648, 2147483647, 0) 49 Passed: static countSmaller(0, 2147483647, 0) 50 Passed: static countSmaller(2147483647, 2147483647, 0) 51 Passed: static countSmaller(-2147483648, -2147483648, 2147483647) 52 Passed: static countSmaller(0, -2147483648, 2147483647) 53 Passed: static countSmaller(2147483647, -2147483648, 2147483647) 54 Passed: static countSmaller(-2147483648, 0, 2147483647) 55 Passed: static countSmaller(0, 0, 2147483647) 56 Passed: static countSmaller(2147483647, 0, 2147483647) 57 Passed: static countSmaller(-2147483648, 2147483647, 2147483647) 58 Passed: static countSmaller(0, 2147483647, 2147483647) 59 Passed: static countSmaller(2147483647, 2147483647, 2147483647) 60 Passed: static main(null) 61 Passed: static main({}) 62 63 =============================================== 64 Command line suite 65 Total tests run: 58, Failures: 1, Skips: 0 66 ===============================================
关于debug
在本单元,我们使用了JML规格方法,严格按照JML规格,进行单元测试及自动测试可以避免很多错误。在课下,我还使用datamaker生成数据并进行计时对拍。
但本单元容易出错的地方还有时间,我在三次强测中未出现错误,但在第三次互测中,被一个数据hack了CTLE,主要还是因为使用了拆点的方法使图巨大,每次跑全部的节点消耗时间过多。debug时选择用了lazy的方法,并进行一些优化。
四、总结与体会
本单元作业中,初次接触基于JML的规格化设计。我们第一次经历了根据JML所规定的规格,实现相应接口的工作模式。本单元中,需要我们阅读,理解JML所规定的规格,这除了需要我们对JML基本语法的理解,更需要的是建立起规格化设计的思想。
JML规格只是规定对输入的前置约束和对输出的后置约束,而对于我们具体运用何种数据结构,如何实现没有明确要求。所以,我们的具体实现,还要考虑很多方面。因为我们有大量的查询指令,要保证不CTLE,需要相应结构缓存计算层,使查询为O(1)复杂度。并且,因为三次作业的增量式递增,所以架构的可扩展性非常重要。
经过前两个单元的联系,我认为我在OO面相对象的思想有了一定的提高。本次作业中,我基本上是进行增量式重构,架构有了一定的可扩展性。并且我学习封装了一系列数据结构,使类的功能性更加集中,代码架构更加加清晰。这从复杂度测试中可以看出,本单元作业的CK复杂度和方法复杂度测试显示都处于一个良好的状态。这也从另一方面让我体会到JML规格化设计的好处。因为我根据JML的规约进行设计与扩展,实现接口PathContainer <-- Graph <-- RailwaySystem逐步递进,让我的代码的架构自然具有了一定的扩展性。
使用JML规格化设计的另一方面的优势就在于测试与验证上。在本单元我还体验了几种不一样的测试方法,如Junit单元测试,OpenJML和JMLuniting的自动测试。基于JML还有很多测试手段和方法可以进一步探究。
希望能在今后的代码生涯中,更好的运用面向对象、抽象、规格化的思想。设计好的构架,写好的代码,实现好的性能。