一.综述
第三单元的主题为社交网络,即构建一个由众多人(Person类)组成的社交网络,并且在后续作业中加入了分组功能和众多查询方法。
整体架构一直延续,三次作业的不同在于后续的两次作业相比第一次添加了许多新方法,其中有许多还是有一定难度的。
本次作业侧重于对JML与契约式编程的理解,考察十分偏重于算法和优化策略,本单元呈现出的新特点是中测和弱测约等于不测,强测十分强悍,而且取消了性能分,超时直接判错。
另外,为了保证每一单元总结格式的一致性,此博客并未严格按照给出的顺序来,附目录对照:
- (1)梳理JML语言的理论基础、应用工具链情况……………………………………………………………………第四部分
- (2) (选做,能较为完善完成的酌情加分) 部署SMT Solver,至少选择3个主要方法来尝试进行验证,报告结果,有可能要补充JML规格……………………………………………………我不想看满屏的报错,所以就不浪费时间了。
- (3)部署JMLUnitNG/JMLUnit,针对Group接口的实现自动生成测试用例,并结合规格对生成的测试用例和数据进行简要分析………………………………第三部分
- (4)按照作业梳理自己的架构设计,特别分析自己的模型构建策略……………………………………………………第二部分
- (5)按照作业分析代码实现的bug和修复情况……………………………………………………第二部分
- (6)阐述对规格撰写和理解上的心得体会……………………………………………………第五部分
二.作业与BUG分析
第一次作业
1.代码思路
第一次作业较简单,但是也较繁琐,因为第一次作业是需要补充的方法最多的一次,不过好在除了iscircle方法之外,其他方法难度普遍较低。只要读懂了JML,基本就可以轻松完成。
大多数方法采用了直接和JML相同的方法,不过值得注意的是person类直接采用的ArrayList存储,虽然简单好用但是制杖,每次通过id来getPerson还要进行一次遍历,简直就是憨憨操作。不过由于此次作业较为简单,并未在此出现问题(取而代之的是更为严重的问题)。
唯一有难度的isCircle方法采用了bfs的方法查找路径。
2.代码度量分析
UML类图
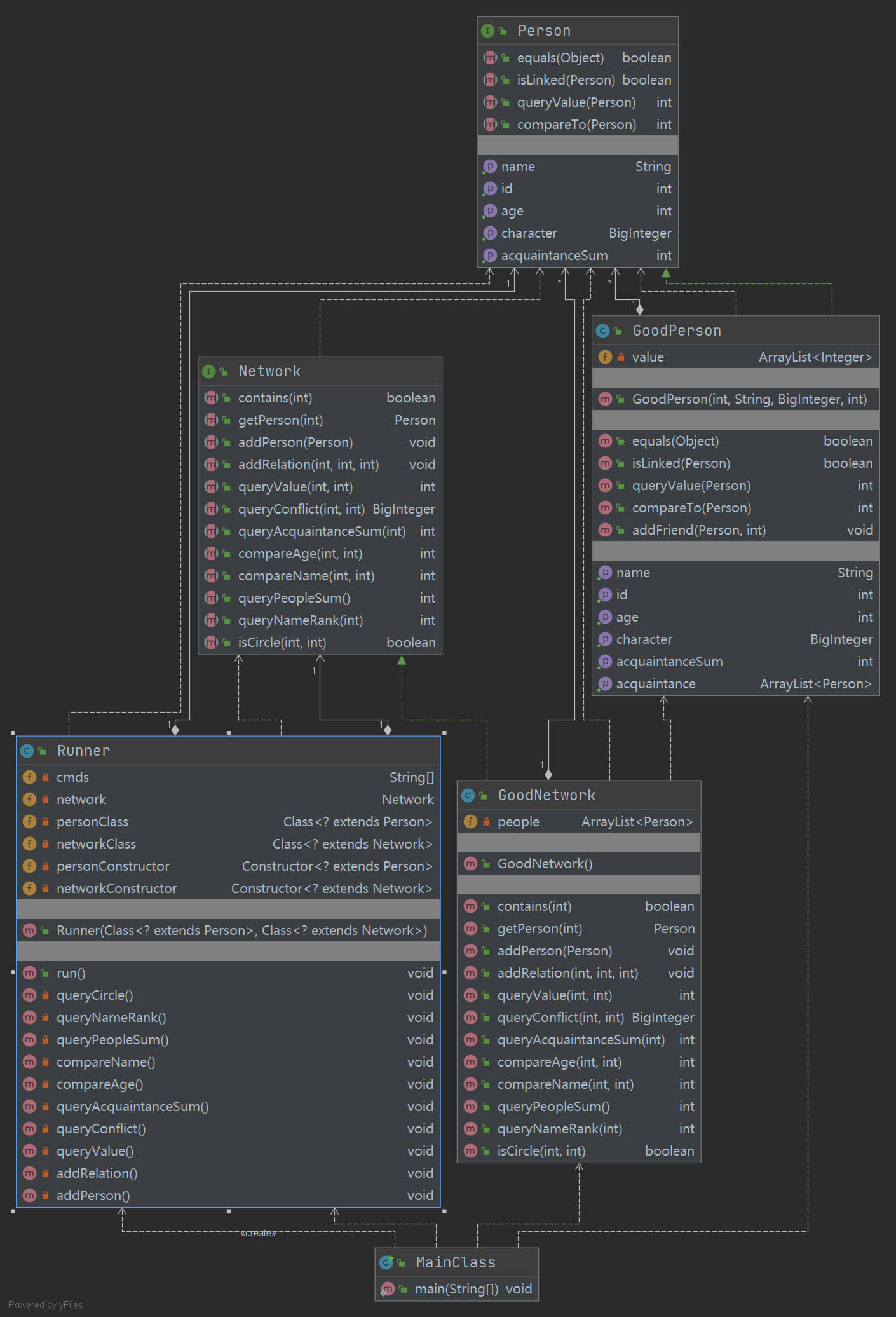
第一次作业整体架构主要来自于接口,并未做任何改进,除了主类和running类之外,就只有总的储存所有person的network类与单独的person类。
复杂度分析
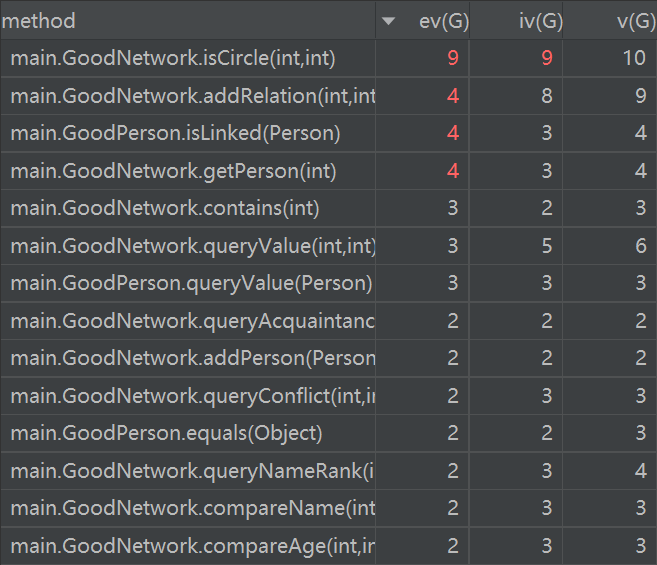
多数方法复杂度都为1,这里列出了一些复杂度较高的方法,可以看出getPerson、isLinked方法和addRelation方法由于采用了遍历,因此有着较高的复杂度,而isCircle方法则是因为采用了bfs宽度优先搜索。
3.bug分析
本单元作业在第一次作业里出现了非常严重的bug,导致isCircle方法根本都运行不了,讽刺的是竟然没有测出来。
- 在迭代过程中删除元素导致运行时报错,修改为新加remove数组记录删除元素,迭代完成后一起删除。
- 由于arraylist数组是通过指针实现的,因此赋值并非拷贝而是直接修改指向元素,导致在执行完a=b,b.clear之后,a,b两个数组全部都被清空,而原本这里应该是赋值操作。这就导致了在bfs的一个循环过后下一步传递的当前元素为空,使得bfs无法实现。
第二次作业
1.代码思路
第二次作业在第一次作业的基础上,新增了Group功能,人员可以进入小组,组内也提供了部分方法,总体代码量较第一次有所下降,但是难度有所上升。
由于对程序性能要求较高,因此第二次作业修改了许多方法,首先是将ArrayList储存person改为有序数组,每次加入person的时候都进行排序,从而将getPerson变为了较为高效的二分查找,在数据量大的时候变得十分高效。其次是将isCircle方法由bfs改为了并查集+路径压缩,极大地减小了方法复杂度。还有在计算方差和平均值的时候,通过储存数据总和与平方和,使得每次只需要一次运算而非遍历,同样极大地减小了复杂度。
2.代码度量分析
UML类图
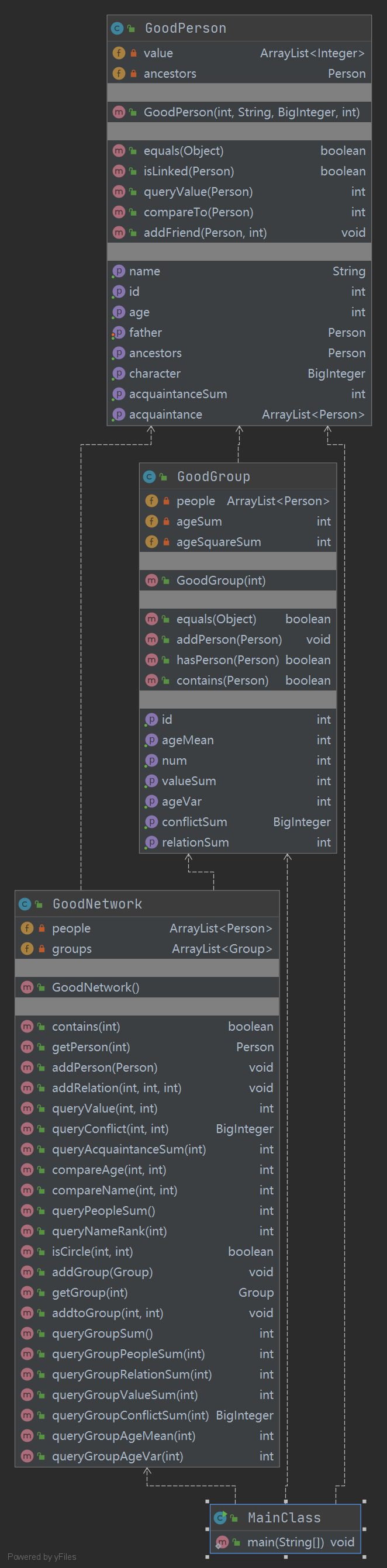
第二次作业架构与第一次相比几乎没有变动,除了增加了Group类。
复杂度分析
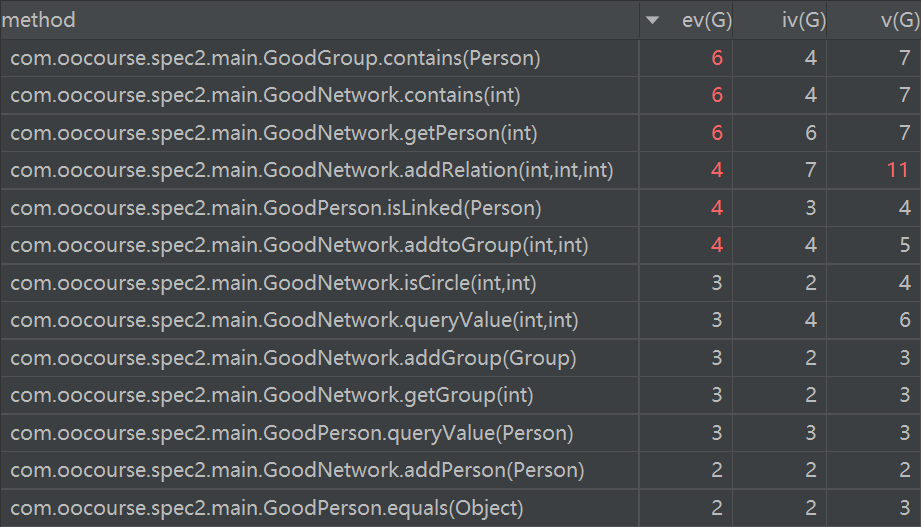
可以看出,此次作业中复杂度略微有所上升,不过由于采用了并查集,因此isCircle复杂度明显下降,取而代之的是采用二分查找的contains方法反而复杂度较高。而由于添加了缓存机制与排序机制,因此addToGroup方法复杂度略高,addRelation方法复杂度高是因为采用了并查集,因此每次添加关系都要维护。
3.bug分析
此次作业在强测和互测阶段均未发现bug。
第三次作业
1.代码思路
第三次作业与第二次作业相比,架构没有任何变化,甚至因此导致MyNetwork几乎超过500行。不过添加了一些新的方法,比如group中删除person方法,如果前一次作业实现不好,可能会耗费一定时间,但是在这里由于我大量使用了缓存机制,因此反向缓存,将个人有关的信息全部删除即可,在conflictSum中甚至利用离散数学知识,通过两次异或等于自身的性质来避免遍历。还有新加了的每个人的钱属性,不过在person中添加了money这一属性后,这部分难度十分有限。
此次作业代码较很小,但是难度上升明显,尤其侧重算法考察,如果方法实现不好是会爆炸的。因此本次作业中大量使用hashset用于contains等查询操作,甚至必要时同时使用ArrayList与hashset两容器。
本次作业难点在于新加方法,getMinPath方法采用迪杰斯特拉算法,(堆优化我也不知道有没有实现,应该是实现了,毕竟都没有超时);queryBlockSum利用前面的并查集使得一次遍历即可完成(如果不是因为一次遍历太简单粗暴还好写,我本应该可以采用更加优美的缓存机制的);最难的是queryStrongLinked方法,开始我采用了两次dfs的方法,但是被同学提出可能有巨大bug后改为了一次dfs,后来发现其时间复杂度极高,因此换成了遍历+bfs查找割点的方法,使得总体复杂度保持稳定。
2.代码度量分析
UML类图
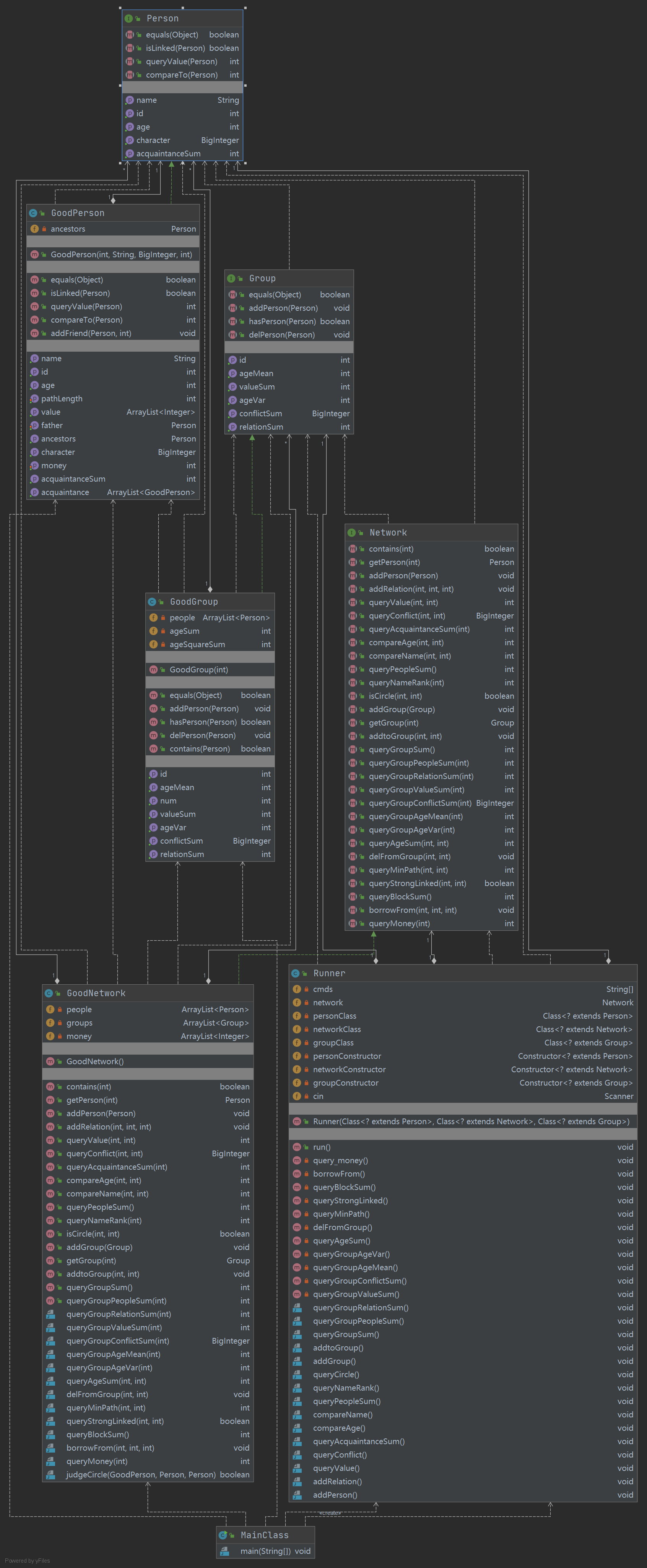
此次作业中架构并没有任何改变,这使得GoodNetwork类成为了一个巨无霸,承担了大量工作。
复杂度分析
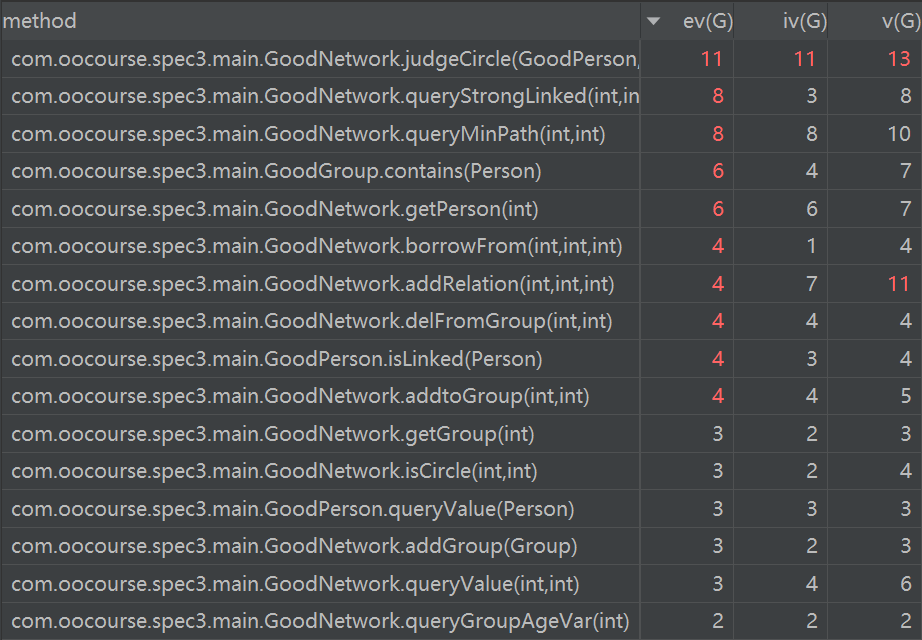
此次作业的复杂度显著上升,尤其是queryStrongLinked方法和为了判断去掉一点后的连通性而修改的采用bfs的judgeCircle方法,采用迪杰斯特拉算法的最短路径也有较高复杂度。其余的一些复杂度则大多都来自于之前的代码,除了前两个方法外,复杂度总体可接受。
4.bug分析
此次作业严格来说并没有出现bug,但是因为方法优化问题,只保证了正确性,但是许多地方性能并不好,导致了强测和互测各有两个queryStrongLinked的测试点超时。后续针对被疯狂调用却性能不好的judgeCircle方法采用了大量优化,使用大量hashset的群体操作来代替之前的ArrayList与双重遍历操作以降低复杂度。
三.JMLUnitNG测试
经过本人的不懈努力与大量失败,终于完成了这一几乎不可能完成的壮举。
以下为测试结果。
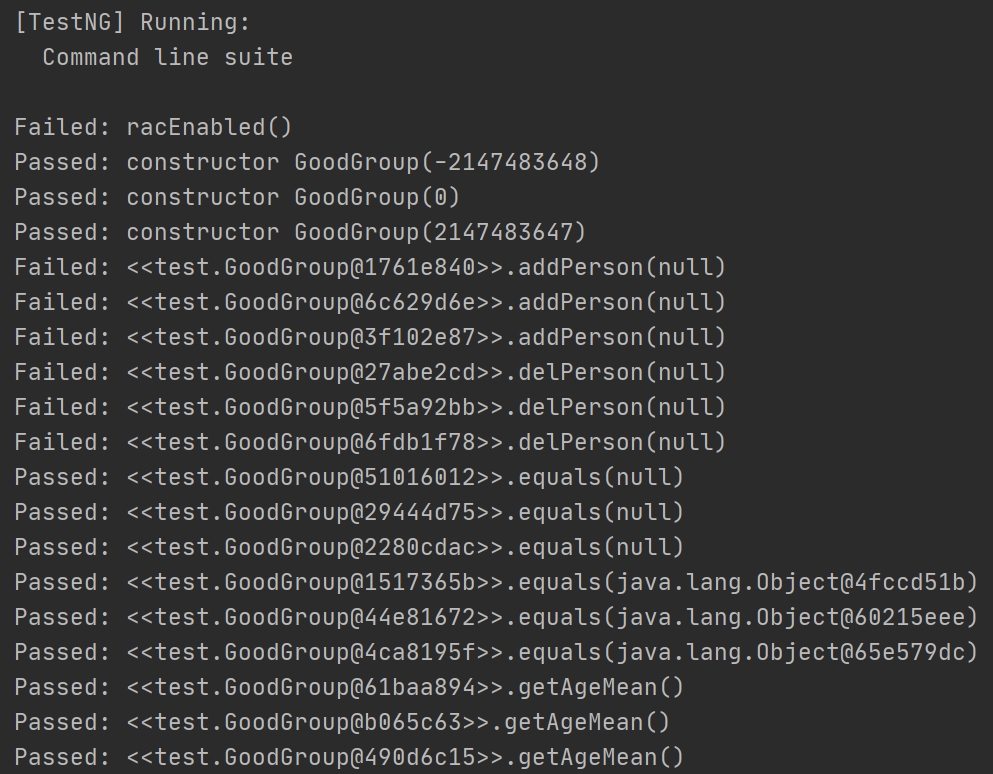
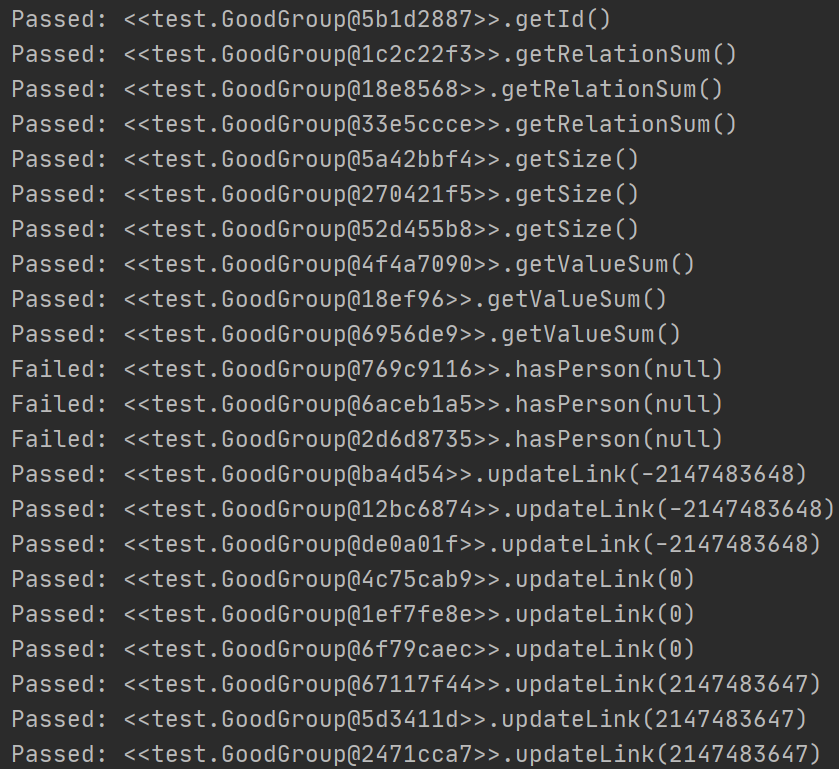
可以看出,它测试的几乎全是边界数据,大概就是想试试是不是覆盖了所有的情况,然后看看异常处理是不是能抛出来。正确的情况我怀疑它根本不会算,然后就选择不管。
作用十分有限,还是需要自行构造测试数据,不管话又说回来,我要是知道哪个数据会出错我的程序还会有bug吗?
不管好处也是有的,就是,边界数据不用自己测了……
四.JML基础与应用工具链
1. 注释结构
JML以javadoc注释的方式来表示规格,每行都以@起头。有两种注释方式,行注释和块注释。其中行注释的表示方式为`//@annotation`,块注释的方式为`/* @ annotation @*/`。按照Javadoc习惯,JML注释一般放在被注释成分的紧邻上部。
2. JML表达式
JML的表达式是对Java表达式的扩展,新增了一些操作符和原子表达式。同样JML表达式中的操作符也有优先级的概念。JML相对于Java新增的表达式成分仅用于JML中的断言(assertion)语句和其他相关的注释体。在JML断言中,不可以使用带有赋值语义的操作符,如`++,--,+=`等操作符,因为这样的操作符会对被限制的相关变量的状态进行修改,产生副作用。
2.1 原子表达式
\result表达式:表示一个非`void`类型的方法执行所获得的结果,即方法执行后的返回值。
\old(`expr`)表达式:用来表示一个表达式`expr`在相应方法执行前的取值。
\not_assigned(x,y,...)表达式:用来表示括号中的变量是否在方法执行过程中被赋值。
\not_modified(x,y,...)表达式:与上面的\not_assigned表达式类似,该表达式限制括号中的变量在方法执行期间的取值未发生变化。
\nonnullelements(`container`)表达式:表示`container`对象中存储的对象不会有`null`
\type(type)表达式:返回类型type对应的类型(Class)。
\typeof(expr)表达式:该表达式返回expr对应的准确类型。
2.2 量化表达式
\forall表达式:全称量词修饰的表达式,表示对于给定范围内的元素,每个元素都满足相应的约束。
\exists表达式:存在量词修饰的表达式,表示对于给定范围内的元素,存在某个元素满足相应的约束。
\sum表达式:返回给定范围内的表达式的和。
\product表达式:返回给定范围内的表达式的连乘结果。
\max表达式:返回给定范围内的表达式的最大值。
\min表达式:返回给定范围内的表达式的最小值。
\num_of表达式:返回指定变量中满足相应条件的取值个数。
2.3 集合表达式
集合构造表达式:可以在JML规格中构造一个局部的集合(容器),明确集合中可以包含的元素。
2.4 操作符
JML表达式中可以正常使用Java语言所定义的操作符,包括算术操作符、逻辑预算操作符等。此外,JML专门又定义了如下四类操作符。
(1) 子类型关系操作符
(2) 等价关系操作符
(3) 推理操作符
(4)变量引用操作符
3.方法规格
方法规格是JML的重要内容。方法规格的核心内容包括三个方面,前置条件、后置条件和副作用约定。其中前置条件是对方法输入参数的限制,如果不满足前置条件,方法执行结果不可预测,或者说不保证方法执行结果的正确性;后置条件是对方法执行结果的限制,如果执行结果满足后置条件,则表示方法执行正确,否则执行错误。副作用指方法在执行过程中对输入对象或this对象进行了修改(对其成员变量进行了赋值,或者调用其修改方法)。
- 前置条件(pre-condition)
前置条件通过requires子句来表示
- 后置条件(post-condition)
后置条件通过ensures子句来表示:
- 副作用范围限定(side-effects)
副作用指方法在执行过程中会修改对象的属性数据或者类的静态成员数据,从而给后续方法的执行带来影响。
4. 类型规格
类型规格指针对Java程序中定义的数据类型所设计的限制规则,一般而言,就是指针对类或接口所设计的约束规则。从面向对象角度来看,类或接口包含数据成员和方法成员的声明及或实现。不失一般性,一个类型的成员要么是静态成员(static member),要么是实例成员(instance member)。一个类的静态方法不可以访问这个类的非静态成员变量(即实例变量)。静态成员可以直接通过类型来引用,而实例成员只能通过类型的实例化对象来引用。因此,在设计和表示类型规格时需要加以区分。
JML针对类型规格定义了多种限制规则,从课程的角度,我们主要涉及两类,不变式限制(invariant)和约束限制(constraints)。无论哪一种,类型规格都是针对类型中定义的数据成员所定义的限制规则,一旦违反限制规则,就称相应的状态有错。
5.相关工具链
- OpenJML
对JML进行语法检查。
- JMLUnitNG
根据JML自动生成测试。
- Junit
单元测试工具。
五.心得体会
关于教训
这一单元的内容比起前两个单元要简单不少,无论是在代码量上还是在难度上都有一定程度的下降,反而更加侧重于算法方面的考察,然而这一单元我却在强测中出现了非常严重的bug,iscircle根本无法正常运行(讽刺的是,这个方法在弱测和中测中根本没测,但是强测中在所有的测试点中都出现了),此次出现的严重错误使得强测只有5分导致我心态直接爆炸,因为我从第一单元开始就十分依赖弱测和中测以检查问题,而这一单元与前两个单元非常大的不同就是测试点弱的离谱,导致有效作业特别简单,而且取消了性能分,超时直接判错,时间限制也非常严格,使得我前两个单元积攒下的经验全部成了我的绊脚石。
关于架构
面向对象的方法关键就在于可以模拟生活中的一些场景,使得编程可以更加贴近生活而不是造一些反人类的操作。也正是因此,可以利用面向对象来对架构进行梳理。在此次作业中,我完全照搬了接口的架构,其实这就有些死板,实际上可以模拟生活中的一些社交圈,对整个network进行进一步的划分,从而使得其更加条理。
关于复杂度
在之前的作业中,复杂度从来都不是需要考虑的问题,只要能保证正确性,而且程序可以在固定时间之内运行出来即可。也正是因此,很多时候都放弃了一些优美的算法转而采取较为暴力的解决方案。诚然,在每周一项少则数百行多则上千行代码量的作业面前,时间变得非常宝贵,并没有时间与义务去进行优化。但是真正到了这次作业中,不难发现,许多方法的实现比起定义,有着更多优美的解决方案。如果不能跳出定义的限制,充分发挥自己的聪明才智,那么可能将会失去许多收获。
关于规格
本单元学习的重点是JML,以及从中体会契约式编程的思想,
根据我的理解,规格在本质上是一种注释,之所以产生规格,是为了不同任务的人在对接的时候,为了能让对方相互理解,而开发出的一种公认的、没有二义性的语言规范。对于契约式编程,每一个方法的要求往往都非常复杂,使用规格可以极大地减轻负担,防止自然语言在某些方面说不明白或者过于啰嗦而带来的种种问题。
但同时,过度依赖规格也容易出现问题,比如对于本单元作业中的iscircle方法与minpath方法,乃至于stronglinked方法,明明几句话就可以说明白的内容,写成规格描述后会显得非常冗余,尤其是我在刚看到的时候不明就里,等到翻译过来后才恍然大悟,如果用通俗的语言文字告诉我,我可能早就明白了。绝大多数情况下,JML是用逻辑运算符号表示的,因此往往不能将JML中的内容照搬出来当做算法。也就是说,完成一个方法,首先要将JML读懂,翻译为自己能明白的语言,然后再将自己理解的内容写成程序。在这里,JML起的作用就是一个桥梁,在牺牲了一部分简洁性后,让所有的人都可以忽略个人语言体系的不同,而使用同一种严谨认真的JML语言进行交流,因此,作为一种通用语言,它的前景是十分广阔的。但是同样也要看出,因为其某些程度上过于死板教条,在目前较为简单的编程水平上,有时候其都显得臃肿且晦涩难懂,尤其是对于初学者而言,可能还不如几句话说得明白,读完之后恍然大悟的成就感可能远不如看到一长串JML带来的恐惧要多,而且在现阶段的括号套括号很多时候就已经容易看花眼了,如果用到大规模工程问题上,底层技术人员在不知道自己要干什么的情况下用火眼金睛去看JML,并不是什么好主意。作为一种语言,其发展的趋势应该是简单便捷,如果不能方便大众,反而增加额外的负担,那么其终将被历史的车轮所碾过。从这一角度看,JML还有很长的路要走。
关于JMLUnitNG测试的吐槽
由于网络上的教程良莠不齐(根本没有),所以在这里要感谢许多同学的博客,在其中或多或少透露了一部分使用方法,使得我经过若干次盲人摸象之后也可以大体了解这个东东如何使用。
然后就看到了下面这种场景……

实际内容更多,大概有上百行错误提示,在此仅仅用两张图做示范。
莫生气,莫生气,气出病来无人替。就连JML里的东西都给我挑毛病,那是我的错吗?那课程组发下来的东西可能有错吗?
这就是所谓的自动生成测试样例吗?i了i了。终于找到比我还制杖的玩意了。
终于,经过若干次失败与心态爆炸后,在它的族谱里面我已经找不到没有被我问候过的亲人之后,我终于弄完了这个测试。
然后你就测个边界数据就完了?
就 这 ?
最后的最后,关于用到的其他工具链也是一样,有很多连几个像样的教程都没有,报错的解决方案更不用说了,以至于对于我这种学生来说实际体验是如此的糟糕。而且运行状况又是如此的制杖,以至于我怀疑这东西根本没人用,甚至怀疑造那些工具链的公司是不是都倒闭了。
第三单元的主题为社交网络,即构建一个由众多人(Person类)组成的社交网络,并且在后续作业中加入了分组功能和众多查询方法。
整体架构一直延续,三次作业的不同在于后续的两次作业相比第一次添加了许多新方法,其中有许多还是有一定难度的。
本次作业侧重于对JML与契约式编程的理解,考察十分偏重于算法和优化策略,本单元呈现出的新特点是中测和弱测约等于不测,强测十分强悍,而且取消了性能分,超时直接判错。
另外,为了保证每一单元总结格式的一致性,此博客并未严格按照给出的顺序来,附目录对照:
- (1)梳理JML语言的理论基础、应用工具链情况……………………………………………………………………第四部分
- (2) (选做,能较为完善完成的酌情加分) 部署SMT Solver,至少选择3个主要方法来尝试进行验证,报告结果,有可能要补充JML规格……………………………………………………我不想看满屏的报错,所以就不浪费时间了。
- (3)部署JMLUnitNG/JMLUnit,针对Group接口的实现自动生成测试用例,并结合规格对生成的测试用例和数据进行简要分析………………………………第三部分
- (4)按照作业梳理自己的架构设计,特别分析自己的模型构建策略……………………………………………………第二部分
- (5)按照作业分析代码实现的bug和修复情况……………………………………………………第二部分
- (6)阐述对规格撰写和理解上的心得体会……………………………………………………第五部分
二.作业与BUG分析
第一次作业
1.代码思路
第一次作业较简单,但是也较繁琐,因为第一次作业是需要补充的方法最多的一次,不过好在除了iscircle方法之外,其他方法难度普遍较低。只要读懂了JML,基本就可以轻松完成。
大多数方法采用了直接和JML相同的方法,不过值得注意的是person类直接采用的ArrayList存储,虽然简单好用但是制杖,每次通过id来getPerson还要进行一次遍历,简直就是憨憨操作。不过由于此次作业较为简单,并未在此出现问题(取而代之的是更为严重的问题)。
唯一有难度的isCircle方法采用了bfs的方法查找路径。
2.代码度量分析
UML类图
第一次作业整体架构主要来自于接口,并未做任何改进,除了主类和running类之外,就只有总的储存所有person的network类与单独的person类。
复杂度分析
多数方法复杂度都为1,这里列出了一些复杂度较高的方法,可以看出getPerson、isLinked方法和addRelation方法由于采用了遍历,因此有着较高的复杂度,而isCircle方法则是因为采用了bfs宽度优先搜索。
3.bug分析
本单元作业在第一次作业里出现了非常严重的bug,导致isCircle方法根本都运行不了,讽刺的是竟然没有测出来。
- 在迭代过程中删除元素导致运行时报错,修改为新加remove数组记录删除元素,迭代完成后一起删除。
- 由于arraylist数组是通过指针实现的,因此赋值并非拷贝而是直接修改指向元素,导致在执行完a=b,b.clear之后,a,b两个数组全部都被清空,而原本这里应该是赋值操作。这就导致了在bfs的一个循环过后下一步传递的当前元素为空,使得bfs无法实现。
第二次作业
1.代码思路
第二次作业在第一次作业的基础上,新增了Group功能,人员可以进入小组,组内也提供了部分方法,总体代码量较第一次有所下降,但是难度有所上升。
由于对程序性能要求较高,因此第二次作业修改了许多方法,首先是将ArrayList储存person改为有序数组,每次加入person的时候都进行排序,从而将getPerson变为了较为高效的二分查找,在数据量大的时候变得十分高效。其次是将isCircle方法由bfs改为了并查集+路径压缩,极大地减小了方法复杂度。还有在计算方差和平均值的时候,通过储存数据总和与平方和,使得每次只需要一次运算而非遍历,同样极大地减小了复杂度。
2.代码度量分析
UML类图
第二次作业架构与第一次相比几乎没有变动,除了增加了Group类。
复杂度分析
可以看出,此次作业中复杂度略微有所上升,不过由于采用了并查集,因此isCircle复杂度明显下降,取而代之的是采用二分查找的contains方法反而复杂度较高。而由于添加了缓存机制与排序机制,因此addToGroup方法复杂度略高,addRelation方法复杂度高是因为采用了并查集,因此每次添加关系都要维护。
3.bug分析
此次作业在强测和互测阶段均未发现bug。
第三次作业
1.代码思路
第三次作业与第二次作业相比,架构没有任何变化,甚至因此导致MyNetwork几乎超过500行。不过添加了一些新的方法,比如group中删除person方法,如果前一次作业实现不好,可能会耗费一定时间,但是在这里由于我大量使用了缓存机制,因此反向缓存,将个人有关的信息全部删除即可,在conflictSum中甚至利用离散数学知识,通过两次异或等于自身的性质来避免遍历。还有新加了的每个人的钱属性,不过在person中添加了money这一属性后,这部分难度十分有限。
此次作业代码较很小,但是难度上升明显,尤其侧重算法考察,如果方法实现不好是会爆炸的。因此本次作业中大量使用hashset用于contains等查询操作,甚至必要时同时使用ArrayList与hashset两容器。
本次作业难点在于新加方法,getMinPath方法采用迪杰斯特拉算法,(堆优化我也不知道有没有实现,应该是实现了,毕竟都没有超时);queryBlockSum利用前面的并查集使得一次遍历即可完成(如果不是因为一次遍历太简单粗暴还好写,我本应该可以采用更加优美的缓存机制的);最难的是queryStrongLinked方法,开始我采用了两次dfs的方法,但是被同学提出可能有巨大bug后改为了一次dfs,后来发现其时间复杂度极高,因此换成了遍历+bfs查找割点的方法,使得总体复杂度保持稳定。
2.代码度量分析
UML类图
此次作业中架构并没有任何改变,这使得GoodNetwork类成为了一个巨无霸,承担了大量工作。
复杂度分析
此次作业的复杂度显著上升,尤其是queryStrongLinked方法和为了判断去掉一点后的连通性而修改的采用bfs的judgeCircle方法,采用迪杰斯特拉算法的最短路径也有较高复杂度。其余的一些复杂度则大多都来自于之前的代码,除了前两个方法外,复杂度总体可接受。
4.bug分析
此次作业严格来说并没有出现bug,但是因为方法优化问题,只保证了正确性,但是许多地方性能并不好,导致了强测和互测各有两个queryStrongLinked的测试点超时。后续针对被疯狂调用却性能不好的judgeCircle方法采用了大量优化,使用大量hashset的群体操作来代替之前的ArrayList与双重遍历操作以降低复杂度。
三.JMLUnitNG测试
经过本人的不懈努力与大量失败,终于完成了这一几乎不可能完成的壮举。
以下为测试结果。
可以看出,它测试的几乎全是边界数据,大概就是想试试是不是覆盖了所有的情况,然后看看异常处理是不是能抛出来。正确的情况我怀疑它根本不会算,然后就选择不管。
作用十分有限,还是需要自行构造测试数据,不管话又说回来,我要是知道哪个数据会出错我的程序还会有bug吗?
不管好处也是有的,就是,边界数据不用自己测了……