什么是分区、分表、分库、分片
分区
就是把一张表的数据分成N个区块,在逻辑上看最终只是一张表,但底层是由N个物理区块组成的;这些区块可以在同一个磁盘上,也可以在不同的磁盘上,盗图:
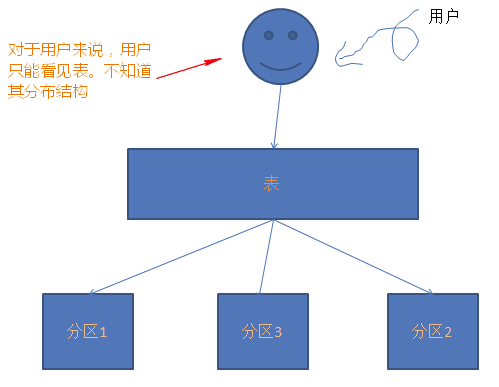
分表
就是把一张表按一定的规则分解成N个具有独立存储空间的实体表。系统读写时需要根据定义好的规则得到对应的表名,然后操作它。一旦分表,一个库中的表会越来越多;
分库
一旦分表,一个库中的表会越来越多,这时需要分成多个数据库。有三种拆分方式:
垂直拆分 |
水平拆分 |
读写分离 |
| 将系统中不存在关联关系或者需要join的表可以放在不同的数据库不同的服务器中。 按照业务垂直划分。比如:可以按照业务分为资金、会员、订单三个数据库。 需要解决的问题:跨数据库的事务、jion查询等问题。 |
例如,大部分的站点。数据都是和用户有关,那么可以根据用户,将数据按照用户水平拆分。 按照规则划分,一般水平分库是在垂直分库之后的。比如每天处理的订单数量是海量的,可以按照一定的规则水平划分。需要解决的问题:数据路由、组装。 |
对于时效性不高的数据,可以通过读写分离缓解数据库压力。需要解决的问题:在业务上区分哪些业务上是允许一定时间延迟的,以及数据同步问题。 |
分片
SqlServer好像不支持数据库分片;
当数据库数据达到上亿级别时,数据库压力会很大,存不下,可以考虑使用数据库分片。
数据库分片模式:
- 垂直切割:不同的表放到不同的数据库中 垂直切割。数据量小,查询性能会提高。 不同数据库位于不同服务器上时,会减小服务器压力。
- 水平分割:单张表数据量也很大,如用户量大产生操作量也会很大。单独查询时,压力也会很大。此时垂直分割也无济于事。可以考虑水平分割 :一张表放到不同数据库中。用户表,放到不同数据库,每个数据库存储部分数据,单表数据量不大。
什么时候使用
| 什么时候用 | 解决的问题 | 区别与联系 | |
| 分区 |
|
|
|
| 分表 |
|
|
|
| 分库 |
|
|
|
| 总结 :优先考虑分区。当分区不能满足需求时,开始考虑分表,合理的分表对效率的提升会优于分区 |
|||
数据库读写分离
场景:
XX:单库数据量太大,数据库扛不住了,我要申请一个数据库从库,读写分离。
DBA:数据量多少?
XX:5000w左右。
DBA:读写吞吐量呢?
XX:读QPS约200,写QPS约30左右。
什么是读写分离?
一主多从,读写分离,主动同步,是一种常见的数据库架构;
-
主库,提供数据库写服务
-
从库,提供数据库读服务
-
主从之间,通过某种机制同步数据
一个组从同步集群通常称为一个“分组”。
分组架构究竟解决什么问题?
大部分互联网业务读多写少,数据库的读往往最先成为性能瓶颈,如果希望:
-
线性提升数据库读性能
-
通过消除读写锁冲突提升数据库写性能
此时可以使用分组架构。
一句话,分组主要解决“数据库读性能瓶颈”问题,在数据库扛不住读的时候,通常读写分离,通过增加从库线性提升系统读性能。
为什么不喜欢读写分离?
对于互联网大数据量,高并发量,高可用要求高,一致性要求高,前端面向用户的业务场景,如果数据库读写分离:
-
数据库连接池需要区分:读连接池,写连接池
-
如果要保证读高可用,读连接池要实现故障自动转移
-
有潜在的主库从库一致性问题
-
如果面临的是“读性能瓶颈”问题,增加缓存可能来得更直接,更容易一点
-
关于成本,从库的成本比缓存高不少
-
对于云上的架构,以阿里云为例,主库提供高可用服务,从库不提供高可用服务
所以,上述业务场景下,建议使用缓存架构来加强系统读性能,替代数据库主从分离架构。
当然,使用缓存架构的潜在问题:雪崩、击穿、穿透。不过幸好,云上的缓存一般都提供高可用的服务。
总结
-
读写分离,解决“数据库读性能瓶颈”问题
-
对于互联网大数据量,高并发量,高可用要求高,一致性要求高,前端面向用户的业务场景,微服务缓存架构,可能比数据库读写分离架构更合适