一.什么是消息队列?什么时候使用它?
在传统的web架构中(此处特指Java SSM架构),用户在web中进行了某项需要和后台产生交互的操作后,一般都要开启一个session,从view层开始,由controller层寻找相应的模型构件,找到相应的model后,生成相应的Java bean,再由Spring将bean映射到逻辑层,找到相关业务逻辑后,调用持久层框架,由数据库进行数据操作。可以看出,实际的业务逻辑十分复杂,在业务逻辑不多时尚可接受,但由于大多数数据库更新采用的是串行的方式,所有操作都需要在上一个操作完成后才能开始,就拿最常见的注册账号操作来说,常规操作下,用户输入基本信息以后,服务器响应时间我们假设为50ms,验证验证码的正确也需要50ms,验证手机号或者邮箱同样需要50ms,那么加起来就需要150ms。可以看出,在数据库操作数量增大后,即使是一个非常简单的select操作,也需要产生不小的服务器负担,一旦业务量也同时增大,很可能会造成服务器卡顿甚至宕机,给用户带来极差的体验。而之前的解决方法,是使用cookie技术,即将数据存放到客户端的浏览器上,但cookie技术虽然简化了业务流程,随之而来的是安全性的降低。某些居心不良的用户可能会修改本地cookie,具有很大的安全隐患。(补充一句,也可以通过对SQL本身的优化,通过调整行级锁来达到最佳的锁粒性,具体可以参考《高性能mySQL》一书,本文不做赘述。)
因此,我们引入了消息中间件(Message-oriented middleware,MOM)技术。消息代理服务器通过将用户消息暂存到一个消息容器中,将一系列复杂的业务流程进行解耦,每个模块只需要完成它对应的功能,不需要关心别的模块。画一张图以便大家理解。
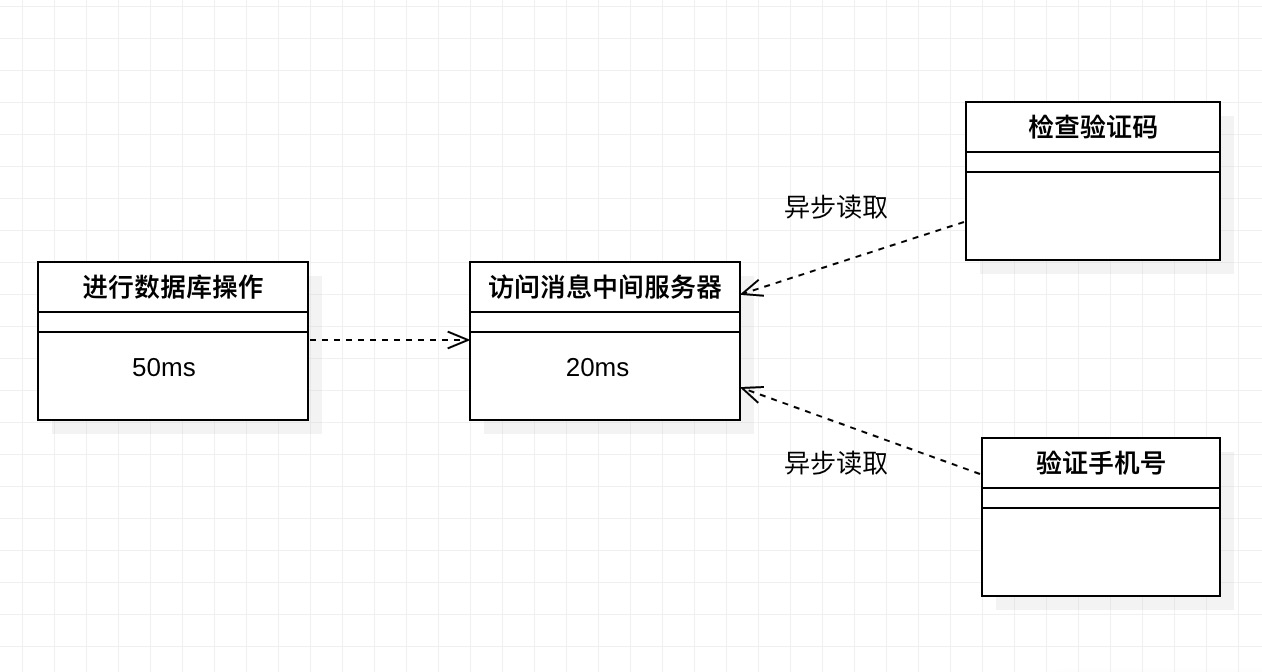
可以看到,通过使用MOM技术,我们将原本可能需要150ms的业务流程缩短到了只需要70ms(实际上优化的时间会更多,因为RabbitMQ的特色正是响应时间极短,达到了微秒级)。同时,实现了业务的解耦,验证手机号时不需要关心用户此时有没有通过验证码。当然,如果并发量太大,我们可以在超过消息队列最大吞吐量后,选择抛弃用户请求,或者直接将用户重定向至报错页面。根据采用技术的不同,最大吞吐量也有所不同,本文介绍的RabbitMQ可达到万级,如果并发量大于万级,可以采用Kafka等技术。
当然,一种技术不可能只有优点而没有缺点。我个人对MOM的理解是这样的,首先它确实对高并发场景有很大的帮助,比如双十一等访问量激增的时候,可以有效帮助服务器进行错峰。同时对各模块进行解耦,使系统各模块间的依赖度降低,不至于一个模块挂了整个系统全部瘫痪。最后,MOM是一种异步请求,无需服务器响应就可以发送下一个请求。但是,与之伴生的是,它对服务器压力的激增,和一系列的现实问题。我打个比方,就拿双十一抢购来说,假如采用了MOM技术,用户下的订单被存在消息队列服务器上,此时,如果后台的库存临时出现变化了,比如某个人下了很多订单突然退单了,由于数据尚未存入数据库,其可能会产生一些影响,又或者说在后续的某个部分, 比如你下了订单以后,后续的手机号填错了,此时你已经通过了下单模块,订单信息已经存入了消息队列服务器中,但后续本该异步的出现了错误,那可能就会出现脏读的情况。当然这些问题都是可以通过一 系列预案,用复杂的逻辑判断来规避的,但势必增加了系统出错的风险,因为系统的复杂性被大大地增加了。更需要注意的是,虽然系统各模块间的依赖度降低了,但这是建立在对消息队列服务器的依赖上的,如果消息队列服务器挂了呢?所以,每项技术都有其应用场景,我们应该根据实际使用情况,来具体分析要不要使用MOM技术。
二.AMQ协议
RabbitMQ基于AMQP规范,AMQP规范不仅定义了一种网络协议,也定义了服务器端的服务和行为。这就是高级消息队列(Advanced Message Queuing,AMQ)模型,其在逻辑上定义了三种抽象组件用于指定消息的路由行为:
·交换器(Exchange),消息代理服务器中用于把消息路由到队列的组件。
·队列(Queue),用来存储消息的数据结构,位于硬盘或内存中。
·绑定(Binding),一套规则,用于告诉交换器消息应该被存储到哪个队列。
一个AMQP可以有多个信道,允许服务器和客户端之间进行多次通信,这就是多路复用。需要注意的是,在尝试声明一个与现有队列同名的信道时,如果新队列的属性与现有队列不一样,那么RabbitMQ将关闭RPC请求的信道。 要正确处理错误,你的客户端应用程序应该监听来自RabbitMQ的Channel.Close命令,以便能够正确响应。有的客户端可能会通过在Channel.Close命令注册一个回调方法来自动触发。
低层AMQP帧是由五个不同的组件构成的,其分别是:
三.RabbitMQ集群
本人的第一篇技术博客就暂时到此为止,本文仅涉及到原理和应用部分,希望自己以后有空详细讲一下RabbitMQ如何实际开发(希望懒癌以后每周都能更新一篇博客啦)另外有不正之处也望各位大神能多多指教,毕竟这是我的一家之言,其肯定有不足之处。 本文系我原创,如需转载,请联系我本人,并注明出处,如有侵权,必追究其法律责任。