迭代器
1.迭代器
迭代器是访问集合元素的一种方式。迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退,不过这也没什么,因为人们很少在迭代途中往后退。另外,迭代器的一大优点是不要求事先准备好整个迭代过程中所有的元素。迭代器仅仅在迭代到某个元素时才计算该元素,而在这之前或之后,元素可以不存在或者被销毁。这个特点使得它特别适合用于遍历一些巨大的或是无限的集合,比如几个G的文件
特点:
- 访问者不需要关心迭代器内部的结构,仅需通过next()方法不断去取下一个内容
- 不能随机访问集合中的某个值 ,只能从头到尾依次访问
- 访问到一半时不能往回退
- 便于循环比较大的数据集合,节省内存
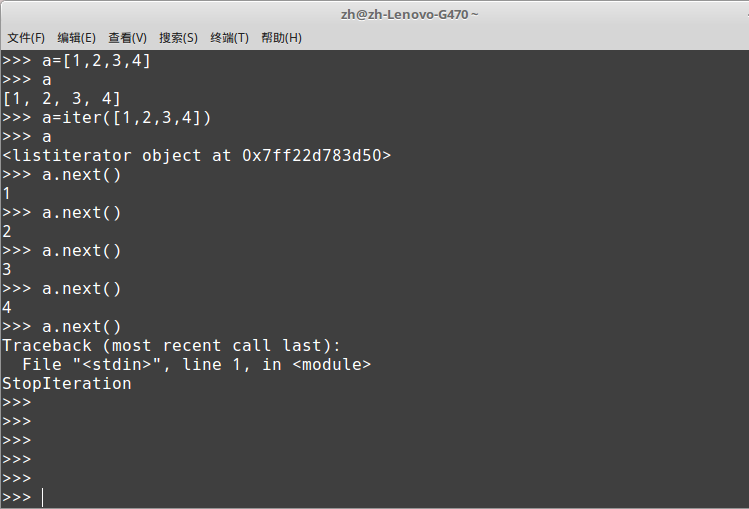
2.iterable可迭代对象, iteror迭代器
可迭代对象:
dir() 方法查看,里面有__itre__() 方法的都是可迭代的对象;可用for循环的:一类是集合数据类型list,tuple,dict,set,str,file等,一类是generator,包括生成器和带yield的generator function。
iterable不是iteror,要用iter()函数,可变成迭代器对象。
iteror迭代器:
而生成器不但可以作用于for循环,还可以被next()函数不断调用并返回下一个值,直到最后抛出StopIteration错误表示无法继续返回下一个值了。
可以被next()函数调用并不断返回下一个值的对象称为迭代器:Iterator。
可以使用isinstance()判断一个对象是否是Iterable和Iterator:
1 >>> from collections import Iterable 2 >>> isinstance([], Iterable) #列表是可迭代的 3 True 4 >>> isinstance((), Iterable) #元组是可迭代的 5 True 6 >>> isinstance({}, Iterable) #字典是可迭代的 7 True 8 >>> isinstance('zheng', Iterable) #字符串也是
这里和前面判断是否是可迭代的 hasattr(str, '__iter__') 得到False矛盾啊,其实我觉得 str 应该是可迭代的。
9 True
10 >>> isinstance({1,2,3}, Iterable) #集合也是
11 True
12 >>> isinstance((x for x in range(10)), Iterable) #生成器也是可迭代的
13 True
14 >>> isinstance(10, Iterable) #整数不是
15 False
16 ############################################
17 >>> from collections import Iterator
18 >>> isinstance([], Iterator) #列表不是迭代器
19 False
20 >>> isinstance('zheng', Iterator) #字符串也不是
21 False
22 #############################################
23 >>> isinstance(iter([]), Iterator) #iter()方法
24 True
25 >>> isinstance(iter('zheng'), Iterator)
26 True
27 >>>
3.关于列表和迭代器之间的区别,还有两个非常典型的内建函数:range() 和 xrange(),研究一下这两个的差异,会有所收获的。
1 >>> dir(range) 2 ['__call__', '__class__', '__cmp__', '__delattr__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__le__', '__lt__', '__module__', '__name__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__self__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__']
3 >>> dir(xrange) 4 ['__class__', '__delattr__', '__doc__', '__format__', '__getattribute__', '__getitem__', '__hash__', '__init__', '__iter__', '__len__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__'] 5 >>>
再查看help(range)和help(xrange)可知:
range返回的是一个列表,xrange返回的是一个对象,而且是可迭代的对象。
也就是说,通过 range() 得到的列表,会一次性被读入内存,而 xrange() 返回的对象,则是需要一个数值才返回一个数值。比如这样一个应用:
还记得 zip() 吗?
>>> a = ["name", "age"] >>> b = ["qiwsir", 40] >>> zip(a,b) [('name', 'qiwsir'), ('age', 40)]
如果两个列表的个数不一样,就会以短的为准了,比如:
>>> zip(range(4), xrange(100000000))
[(0, 0), (1, 1), (2, 2), (3, 3)]
第一个 range(4) 产生的列表被读入内存;第二个是不是也太长了?但是不用担心,它根本不会产生那么长的列表,因为只需要前 4 个数值,它就提供前四个数值。如果你要修改为 range(100000000),就要花费时间了,可以尝试一下哦。
生成器
1.什么是生成器
一个函数调用时返回一个迭代器,那这个函数就叫做生成器(generator);如果函数中包含yield语法,那这个函数就会变成生成器;
2.生成器的构建
简单的生成器:生成器解析式
1 >>> lst=[x*x for x in range(5)] #列表解析式 2 >>> lst 3 [0, 1, 4, 9, 16] 4 >>> g=(x*x for x in range(5)) #把[]换成(),是创建生成器的第一种方法,很简单 5 >>> g 6 <generator object <genexpr> at 0x7fa3eefe0990>
1 >>> dir(g) 2 ['__class__', '__delattr__', '__doc__', '__format__', '__getattribute__', '__hash__', '__init__', '__iter__', '__name__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'close', 'gi_code', 'gi_frame', 'gi_running', 'next', 'send', 'throw']
从上可看出:生成器有__iter__()方法和__next__()方法,所以他是迭代器,既然是迭代器就可以用for循环
1 >>> for i in g: 2 ... print i 3 ... 4 0 5 1 6 4 7 9 8 16 9 >>> for i in g: 10 ... print i 11 ... 12 >>>
从上看出:当第一遍循环的时候,将 g 里面的值依次读出并打印,但是,当再读一次的时候,就发现没有任何结果。这种特性也正是迭代器所具有的。
1 >>> lst=[x*x for x in range(5)] #列表解析式 2 >>> lst 3 [0, 1, 4, 9, 16] 4 >>> 5 >>> for i in lst: 6 ... print i 7 ... 8 0 9 1 10 4 11 9 12 16 13 >>> 14 >>> for i in lst: 15 ... print i 16 ... 17 0 18 1 19 4 20 9 21 16 22 >>>
从以上看出:列表和迭代器的区别
通过生成器解析式得到的生成器,掩盖了生成器的一些细节,并且适用领域也有限。下面就要剖析生成器的内部,深入理解这个魔法工具。
定义和执行生成器:
yield 这个词在汉语中有“生产、出产”之意,在 Python 中,它作为一个关键词(你在变量、函数、类的名称中就不能用这个了),是生成器的标志。
1 >>> def g(): 2 ... yield 0 3 ... yield 1 4 ... yield 2 5 ... 6 >>> g 7 <function g at 0x7f51e5bcaed8> 8 >>> ge=g() 9 >>> ge 10 <generator object g at 0x7f51e5bb8be0> 11 >>> type(ge) #返回值是一个生成器 12 <type 'generator'> 13 >>> 14 >>> 15 >>> dir(ge) 16 ['__class__', '__delattr__', '__doc__', '__format__', '__getattribute__', '__hash__', '__init__', '__iter__', '__name__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'close', 'gi_code', 'gi_frame', 'gi_running', 'next', 'send', 'throw']
1 ge = g():除了返回生成器之外,什么也没有操作,任何值也没有被返回。 2 ge.next():直到这时候,生成器才开始执行,遇到了第一个 yield 语句,将值返回,并暂停执行(有的称之为挂起)。 3 ge.next():从上次暂停的位置开始,继续向下执行,遇到 yield 语句,将值返回,又暂停。 4 ge.next():重复上面的操作。 5 ge.next():从上面的挂起位置开始,但是后面没有可执行的了,于是 next() 发出异常。
ge有__iter__和next方法,是一个迭代器,所以
1 >>> ge.next() 2 0 3 >>> ge.next() 4 1 5 >>> ge.next() 6 2 7 >>> ge.next() 8 Traceback (most recent call last): 9 File "<stdin>", line 1, in <module> 10 StopIteration
综上:可以看出,那个含有 yield 关键词的函数返回值是一个生成器类型的对象,这个生成器对象就是迭代器
3.yield和return的区别:
yield跳出函数后会记录当前函数的状态当下次调用的时候,从记录的状态开始!
return后将直接跳出函数!
1 >>> def r_return(n): 2 ... print "You taked me." 3 ... while n > 0: 4 ... print "before return" 5 ... return n 6 ... n -= 1 7 ... print "after return" 8 ... 9 >>> rr = r_return(3) 10 You taked me. 11 before return 12 >>> rr 13 3
1 >>> def y_yield(n): 2 ... print "You taked me." 3 ... while n > 0: 4 ... print "before yield" 5 ... yield n 6 ... n -= 1 7 ... print "after yield" 8 ... 9 >>> yy = y_yield(3) #没有执行函数体内语句 10 >>> yy.next() #开始执行 11 You taked me. 12 before yield 13 3 #遇到 yield,返回值,并暂停 14 >>> yy.next() #从上次暂停位置开始继续执行 15 after yield 16 before yield 17 2 #又遇到 yield,返回值,并暂停 18 >>> yy.next() #重复上述过程 19 after yield 20 before yield 21 1 22 >>> yy.next() 23 after yield #没有满足条件的值,抛出异常 24 Traceback (most recent call last): 25 File "<stdin>", line 1, in <module> 26 StopIteration
4.生成器方法
http://wiki.jikexueyuan.com/project/start-learning-python/215.html
send()和 close() 和 throw()
装饰器
http://www.cnblogs.com/wupeiqi/articles/4980620.html
http://www.cnblogs.com/rhcad/archive/2011/12/21/2295507.html
一、首先来大致了解下嵌套函数:
被嵌套与一层函数中的二层函数可以记录上上一层函数作用域中的变量
1 def foo(a):
2 def subfoo(b):
3 return(b + a)
4 return(subfoo)
5
6 f = foo('content') #由于foo返回的是subfoo,所以f是对subfoo的引用
7 f('sub_') #因为subfoo记录了foo的参数变量'content',所以返回值为'sub_content'
1、必备
1 #### 第一波 #### 2 def foo(): 3 print 'foo' 4 5 foo #表示是函数 6 foo() #表示执行foo函数 7 8 #### 第二波 #### 9 def foo(): 10 print 'foo' 11 12 foo = lambda x: x + 1 13 14 foo() # 执行下面的lambda表达式,而不再是原来的foo函数,因为函数 foo 被重新定义了
2、需求来了
初创公司有N个业务部门,1个基础平台部门,基础平台负责提供底层的功能,如:数据库操作、redis调用、监控API等功能。业务部门使用基础功能时,只需调用基础平台提供的功能即可。如下:
1 ############### 基础平台提供的功能如下 ############### 2 3 def f1(): 4 print 'f1' 5 6 def f2(): 7 print 'f2' 8 9 def f3(): 10 print 'f3' 11 12 def f4(): 13 print 'f4' 14 15 ############### 业务部门A 调用基础平台提供的功能 ############### 16 17 f1() 18 f2() 19 f3() 20 f4() 21 22 ############### 业务部门B 调用基础平台提供的功能 ############### 23 24 f1() 25 f2() 26 f3() 27 f4()
目前公司有条不紊的进行着,但是,以前基础平台的开发人员在写代码时候没有关注验证相关的问题,即:基础平台的提供的功能可以被任何人使用。现在需要对基础平台的所有功能进行重构,为平台提供的所有功能添加验证机制,即:执行功能前,先进行验证。
老大把工作交给 Low B,他是这么做的:
1 跟每个业务部门交涉,每个业务部门自己写代码,调用基础平台的功能之前先验证。诶,这样一来基础平台就不需要做任何修改了。
当天Low B 被开除了...
老大把工作交给 Low BB,他是这么做的:
1 只对基础平台的代码进行重构,让N业务部门无需做任何修改
 View Code
View Code
过了一周 Low BB 被开除了...
老大把工作交给 Low BBB,他是这么做的:
1 只对基础平台的代码进行重构,其他业务部门无需做任何修改
View Code
老大看了下Low BBB 的实现,嘴角漏出了一丝的欣慰的笑,语重心长的跟Low BBB聊了个天:
老大说:
写代码要遵循开放封闭原则,虽然在这个原则是用的面向对象开发,但是也适用于函数式编程,简单来说,它规定已经实现的功能代码不允许被修改,但可以被扩展,即:
- 封闭:已实现的功能代码块
- 开放:对扩展开发
如果将开放封闭原则应用在上述需求中,那么就不允许在函数 f1 、f2、f3、f4的内部进行修改代码,老板就给了Low BBB一个实现方案:
1 def w1(func): 2 def inner(): 3 # 验证1 4 # 验证2 5 # 验证3 6 return func() 7 return inner 8 9 @w1 10 def f1(): 11 print 'f1' 12 @w1 13 def f2(): 14 print 'f2' 15 @w1 16 def f3(): 17 print 'f3' 18 @w1 19 def f4(): 20 print 'f4'
对于上述代码,也是仅仅对基础平台的代码进行修改,就可以实现在其他人调用函数 f1 f2 f3 f4 之前都进行【验证】操作,并且其他业务部门无需做任何操作。
Low BBB心惊胆战的问了下,这段代码的内部执行原理是什么呢?
老大正要生气,突然Low BBB的手机掉到地上,恰恰屏保就是Low BBB的女友照片,老大一看一紧一抖,喜笑颜开,交定了Low BBB这个朋友。详细的开始讲解了:
单独以f1为例:
1 def w1(func): 2 def inner(): 3 # 验证1 4 # 验证2 5 # 验证3 6 return func() 7 return inner 8 9 @w1 10 def f1(): 11 print 'f1'
当写完这段代码后(函数未被执行、未被执行、未被执行),python解释器就会从上到下解释代码,步骤如下:
- def w1(func): ==>将w1函数加载到内存
- @w1
没错,从表面上看解释器仅仅会解释这两句代码,因为函数在没有被调用之前其内部代码不会被执行。
从表面上看解释器着实会执行这两句,但是 @w1 这一句代码里却有大文章,@函数名 是python的一种语法糖。
如上例@w1内部会执行一下操作:
- 执行w1函数,并将 @w1 下面的 函数 作为w1函数的参数,即:@w1 等价于 w1(f1)
所以,内部就会去执行:
def inner:
#验证
return f1() # func是参数,此时 func 等于 f1
return inner # 返回的 inner,inner代表的是函数,非执行函数
其实就是将原来的 f1 函数塞进另外一个函数中 - 将执行完的 w1 函数返回值赋值给@w1下面的函数的函数名
w1函数的返回值是:
def inner:
#验证
return 原来f1() # 此处的 f1 表示原来的f1函数
然后,将此返回值再重新赋值给 f1,即:
新f1 = def inner:
#验证
return 原来f1()
所以,以后业务部门想要执行 f1 函数时,就会执行 新f1 函数,在 新f1 函数内部先执行验证,再执行原来的f1函数,然后将 原来f1 函数的返回值 返回给了业务调用者。
如此一来, 即执行了验证的功能,又执行了原来f1函数的内容,并将原f1函数返回值 返回给业务调用着
Low BBB 你明白了吗?要是没明白的话,我晚上去你家帮你解决吧!!!
先把上述流程看懂,之后还会继续更新...
3、问答时间
问题:被装饰的函数如果有参数呢?
一个参数
两个参数
三个参数
问题:可以装饰具有处理n个参数的函数的装饰器?
View Code
问题:一个函数可以被多个装饰器装饰吗?
View Code
问题:还有什么更吊的装饰器吗?
View Code
4、functools.wraps
上述的装饰器虽然已经完成了其应有的功能,即:装饰器内的函数代指了原函数,注意其只是代指而非相等,原函数的元信息没有被赋值到装饰器函数内部。例如:函数的注释信息
无元信息
如果使用@functools.wraps装饰装饰器内的函数,那么就会代指元信息和函数。
含元信息
迭代器
1.迭代器
迭代器是访问集合元素的一种方式。迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退,不过这也没什么,因为人们很少在迭代途中往后退。另外,迭代器的一大优点是不要求事先准备好整个迭代过程中所有的元素。迭代器仅仅在迭代到某个元素时才计算该元素,而在这之前或之后,元素可以不存在或者被销毁。这个特点使得它特别适合用于遍历一些巨大的或是无限的集合,比如几个G的文件
特点:
- 访问者不需要关心迭代器内部的结构,仅需通过next()方法不断去取下一个内容
- 不能随机访问集合中的某个值 ,只能从头到尾依次访问
- 访问到一半时不能往回退
- 便于循环比较大的数据集合,节省内存
2.iterable可迭代对象, iteror迭代器
可迭代对象:
dir() 方法查看,里面有__itre__() 方法的都是可迭代的对象;可用for循环的:一类是集合数据类型list,tuple,dict,set,str,file等,一类是generator,包括生成器和带yield的generator function。
iterable不是iteror,要用iter()函数,可变成迭代器对象。
iteror迭代器:
而生成器不但可以作用于for循环,还可以被next()函数不断调用并返回下一个值,直到最后抛出StopIteration错误表示无法继续返回下一个值了。
可以被next()函数调用并不断返回下一个值的对象称为迭代器:Iterator。
可以使用isinstance()判断一个对象是否是Iterable和Iterator:
1 >>> from collections import Iterable 2 >>> isinstance([], Iterable) #列表是可迭代的 3 True 4 >>> isinstance((), Iterable) #元组是可迭代的 5 True 6 >>> isinstance({}, Iterable) #字典是可迭代的 7 True 8 >>> isinstance('zheng', Iterable) #字符串也是
这里和前面判断是否是可迭代的 hasattr(str, '__iter__') 得到False矛盾啊,其实我觉得 str 应该是可迭代的。
9 True
10 >>> isinstance({1,2,3}, Iterable) #集合也是
11 True
12 >>> isinstance((x for x in range(10)), Iterable) #生成器也是可迭代的
13 True
14 >>> isinstance(10, Iterable) #整数不是
15 False
16 ############################################
17 >>> from collections import Iterator
18 >>> isinstance([], Iterator) #列表不是迭代器
19 False
20 >>> isinstance('zheng', Iterator) #字符串也不是
21 False
22 #############################################
23 >>> isinstance(iter([]), Iterator) #iter()方法
24 True
25 >>> isinstance(iter('zheng'), Iterator)
26 True
27 >>>
3.关于列表和迭代器之间的区别,还有两个非常典型的内建函数:range() 和 xrange(),研究一下这两个的差异,会有所收获的。
1 >>> dir(range) 2 ['__call__', '__class__', '__cmp__', '__delattr__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__le__', '__lt__', '__module__', '__name__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__self__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__']
3 >>> dir(xrange) 4 ['__class__', '__delattr__', '__doc__', '__format__', '__getattribute__', '__getitem__', '__hash__', '__init__', '__iter__', '__len__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__'] 5 >>>
再查看help(range)和help(xrange)可知:
range返回的是一个列表,xrange返回的是一个对象,而且是可迭代的对象。
也就是说,通过 range() 得到的列表,会一次性被读入内存,而 xrange() 返回的对象,则是需要一个数值才返回一个数值。比如这样一个应用:
还记得 zip() 吗?
>>> a = ["name", "age"] >>> b = ["qiwsir", 40] >>> zip(a,b) [('name', 'qiwsir'), ('age', 40)]
如果两个列表的个数不一样,就会以短的为准了,比如:
>>> zip(range(4), xrange(100000000))
[(0, 0), (1, 1), (2, 2), (3, 3)]
第一个 range(4) 产生的列表被读入内存;第二个是不是也太长了?但是不用担心,它根本不会产生那么长的列表,因为只需要前 4 个数值,它就提供前四个数值。如果你要修改为 range(100000000),就要花费时间了,可以尝试一下哦。
生成器
1.什么是生成器
一个函数调用时返回一个迭代器,那这个函数就叫做生成器(generator);如果函数中包含yield语法,那这个函数就会变成生成器;
2.生成器的构建
简单的生成器:生成器解析式
1 >>> lst=[x*x for x in range(5)] #列表解析式 2 >>> lst 3 [0, 1, 4, 9, 16] 4 >>> g=(x*x for x in range(5)) #把[]换成(),是创建生成器的第一种方法,很简单 5 >>> g 6 <generator object <genexpr> at 0x7fa3eefe0990>
1 >>> dir(g) 2 ['__class__', '__delattr__', '__doc__', '__format__', '__getattribute__', '__hash__', '__init__', '__iter__', '__name__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'close', 'gi_code', 'gi_frame', 'gi_running', 'next', 'send', 'throw']
从上可看出:生成器有__iter__()方法和__next__()方法,所以他是迭代器,既然是迭代器就可以用for循环
1 >>> for i in g: 2 ... print i 3 ... 4 0 5 1 6 4 7 9 8 16 9 >>> for i in g: 10 ... print i 11 ... 12 >>>
从上看出:当第一遍循环的时候,将 g 里面的值依次读出并打印,但是,当再读一次的时候,就发现没有任何结果。这种特性也正是迭代器所具有的。
1 >>> lst=[x*x for x in range(5)] #列表解析式 2 >>> lst 3 [0, 1, 4, 9, 16] 4 >>> 5 >>> for i in lst: 6 ... print i 7 ... 8 0 9 1 10 4 11 9 12 16 13 >>> 14 >>> for i in lst: 15 ... print i 16 ... 17 0 18 1 19 4 20 9 21 16 22 >>>
从以上看出:列表和迭代器的区别
通过生成器解析式得到的生成器,掩盖了生成器的一些细节,并且适用领域也有限。下面就要剖析生成器的内部,深入理解这个魔法工具。
定义和执行生成器:
yield 这个词在汉语中有“生产、出产”之意,在 Python 中,它作为一个关键词(你在变量、函数、类的名称中就不能用这个了),是生成器的标志。
1 >>> def g(): 2 ... yield 0 3 ... yield 1 4 ... yield 2 5 ... 6 >>> g 7 <function g at 0x7f51e5bcaed8> 8 >>> ge=g() 9 >>> ge 10 <generator object g at 0x7f51e5bb8be0> 11 >>> type(ge) #返回值是一个生成器 12 <type 'generator'> 13 >>> 14 >>> 15 >>> dir(ge) 16 ['__class__', '__delattr__', '__doc__', '__format__', '__getattribute__', '__hash__', '__init__', '__iter__', '__name__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'close', 'gi_code', 'gi_frame', 'gi_running', 'next', 'send', 'throw']
1 ge = g():除了返回生成器之外,什么也没有操作,任何值也没有被返回。 2 ge.next():直到这时候,生成器才开始执行,遇到了第一个 yield 语句,将值返回,并暂停执行(有的称之为挂起)。 3 ge.next():从上次暂停的位置开始,继续向下执行,遇到 yield 语句,将值返回,又暂停。 4 ge.next():重复上面的操作。 5 ge.next():从上面的挂起位置开始,但是后面没有可执行的了,于是 next() 发出异常。
ge有__iter__和next方法,是一个迭代器,所以
1 >>> ge.next() 2 0 3 >>> ge.next() 4 1 5 >>> ge.next() 6 2 7 >>> ge.next() 8 Traceback (most recent call last): 9 File "<stdin>", line 1, in <module> 10 StopIteration
综上:可以看出,那个含有 yield 关键词的函数返回值是一个生成器类型的对象,这个生成器对象就是迭代器
3.yield和return的区别:
yield跳出函数后会记录当前函数的状态当下次调用的时候,从记录的状态开始!
return后将直接跳出函数!
1 >>> def r_return(n): 2 ... print "You taked me." 3 ... while n > 0: 4 ... print "before return" 5 ... return n 6 ... n -= 1 7 ... print "after return" 8 ... 9 >>> rr = r_return(3) 10 You taked me. 11 before return 12 >>> rr 13 3
1 >>> def y_yield(n): 2 ... print "You taked me." 3 ... while n > 0: 4 ... print "before yield" 5 ... yield n 6 ... n -= 1 7 ... print "after yield" 8 ... 9 >>> yy = y_yield(3) #没有执行函数体内语句 10 >>> yy.next() #开始执行 11 You taked me. 12 before yield 13 3 #遇到 yield,返回值,并暂停 14 >>> yy.next() #从上次暂停位置开始继续执行 15 after yield 16 before yield 17 2 #又遇到 yield,返回值,并暂停 18 >>> yy.next() #重复上述过程 19 after yield 20 before yield 21 1 22 >>> yy.next() 23 after yield #没有满足条件的值,抛出异常 24 Traceback (most recent call last): 25 File "<stdin>", line 1, in <module> 26 StopIteration
4.生成器方法
http://wiki.jikexueyuan.com/project/start-learning-python/215.html
send()和 close() 和 throw()
装饰器
http://www.cnblogs.com/wupeiqi/articles/4980620.html
http://www.cnblogs.com/rhcad/archive/2011/12/21/2295507.html
一、首先来大致了解下嵌套函数:
被嵌套与一层函数中的二层函数可以记录上上一层函数作用域中的变量
1 def foo(a):
2 def subfoo(b):
3 return(b + a)
4 return(subfoo)
5
6 f = foo('content') #由于foo返回的是subfoo,所以f是对subfoo的引用
7 f('sub_') #因为subfoo记录了foo的参数变量'content',所以返回值为'sub_content'
1、必备
1 #### 第一波 #### 2 def foo(): 3 print 'foo' 4 5 foo #表示是函数 6 foo() #表示执行foo函数 7 8 #### 第二波 #### 9 def foo(): 10 print 'foo' 11 12 foo = lambda x: x + 1 13 14 foo() # 执行下面的lambda表达式,而不再是原来的foo函数,因为函数 foo 被重新定义了
2、需求来了
初创公司有N个业务部门,1个基础平台部门,基础平台负责提供底层的功能,如:数据库操作、redis调用、监控API等功能。业务部门使用基础功能时,只需调用基础平台提供的功能即可。如下:
1 ############### 基础平台提供的功能如下 ############### 2 3 def f1(): 4 print 'f1' 5 6 def f2(): 7 print 'f2' 8 9 def f3(): 10 print 'f3' 11 12 def f4(): 13 print 'f4' 14 15 ############### 业务部门A 调用基础平台提供的功能 ############### 16 17 f1() 18 f2() 19 f3() 20 f4() 21 22 ############### 业务部门B 调用基础平台提供的功能 ############### 23 24 f1() 25 f2() 26 f3() 27 f4()
目前公司有条不紊的进行着,但是,以前基础平台的开发人员在写代码时候没有关注验证相关的问题,即:基础平台的提供的功能可以被任何人使用。现在需要对基础平台的所有功能进行重构,为平台提供的所有功能添加验证机制,即:执行功能前,先进行验证。
老大把工作交给 Low B,他是这么做的:
1 跟每个业务部门交涉,每个业务部门自己写代码,调用基础平台的功能之前先验证。诶,这样一来基础平台就不需要做任何修改了。
当天Low B 被开除了...
老大把工作交给 Low BB,他是这么做的:
1 只对基础平台的代码进行重构,让N业务部门无需做任何修改
View Code
过了一周 Low BB 被开除了...
老大把工作交给 Low BBB,他是这么做的:
1 只对基础平台的代码进行重构,其他业务部门无需做任何修改
View Code
老大看了下Low BBB 的实现,嘴角漏出了一丝的欣慰的笑,语重心长的跟Low BBB聊了个天:
老大说:
写代码要遵循开放封闭原则,虽然在这个原则是用的面向对象开发,但是也适用于函数式编程,简单来说,它规定已经实现的功能代码不允许被修改,但可以被扩展,即:
- 封闭:已实现的功能代码块
- 开放:对扩展开发
如果将开放封闭原则应用在上述需求中,那么就不允许在函数 f1 、f2、f3、f4的内部进行修改代码,老板就给了Low BBB一个实现方案:
1 def w1(func): 2 def inner(): 3 # 验证1 4 # 验证2 5 # 验证3 6 return func() 7 return inner 8 9 @w1 10 def f1(): 11 print 'f1' 12 @w1 13 def f2(): 14 print 'f2' 15 @w1 16 def f3(): 17 print 'f3' 18 @w1 19 def f4(): 20 print 'f4'
对于上述代码,也是仅仅对基础平台的代码进行修改,就可以实现在其他人调用函数 f1 f2 f3 f4 之前都进行【验证】操作,并且其他业务部门无需做任何操作。
Low BBB心惊胆战的问了下,这段代码的内部执行原理是什么呢?
老大正要生气,突然Low BBB的手机掉到地上,恰恰屏保就是Low BBB的女友照片,老大一看一紧一抖,喜笑颜开,交定了Low BBB这个朋友。详细的开始讲解了:
单独以f1为例:
1 def w1(func): 2 def inner(): 3 # 验证1 4 # 验证2 5 # 验证3 6 return func() 7 return inner 8 9 @w1 10 def f1(): 11 print 'f1'
当写完这段代码后(函数未被执行、未被执行、未被执行),python解释器就会从上到下解释代码,步骤如下:
- def w1(func): ==>将w1函数加载到内存
- @w1
没错,从表面上看解释器仅仅会解释这两句代码,因为函数在没有被调用之前其内部代码不会被执行。
从表面上看解释器着实会执行这两句,但是 @w1 这一句代码里却有大文章,@函数名 是python的一种语法糖。
如上例@w1内部会执行一下操作:
- 执行w1函数,并将 @w1 下面的 函数 作为w1函数的参数,即:@w1 等价于 w1(f1)
所以,内部就会去执行:
def inner:
#验证
return f1() # func是参数,此时 func 等于 f1
return inner # 返回的 inner,inner代表的是函数,非执行函数
其实就是将原来的 f1 函数塞进另外一个函数中 - 将执行完的 w1 函数返回值赋值给@w1下面的函数的函数名
w1函数的返回值是:
def inner:
#验证
return 原来f1() # 此处的 f1 表示原来的f1函数
然后,将此返回值再重新赋值给 f1,即:
新f1 = def inner:
#验证
return 原来f1()
所以,以后业务部门想要执行 f1 函数时,就会执行 新f1 函数,在 新f1 函数内部先执行验证,再执行原来的f1函数,然后将 原来f1 函数的返回值 返回给了业务调用者。
如此一来, 即执行了验证的功能,又执行了原来f1函数的内容,并将原f1函数返回值 返回给业务调用着
Low BBB 你明白了吗?要是没明白的话,我晚上去你家帮你解决吧!!!
先把上述流程看懂,之后还会继续更新...
3、问答时间
问题:被装饰的函数如果有参数呢?
一个参数
两个参数
三个参数
问题:可以装饰具有处理n个参数的函数的装饰器?
View Code
问题:一个函数可以被多个装饰器装饰吗?
View Code
问题:还有什么更吊的装饰器吗?
View Code
4、functools.wraps
上述的装饰器虽然已经完成了其应有的功能,即:装饰器内的函数代指了原函数,注意其只是代指而非相等,原函数的元信息没有被赋值到装饰器函数内部。例如:函数的注释信息
无元信息
如果使用@functools.wraps装饰装饰器内的函数,那么就会代指元信息和函数。
含元信息