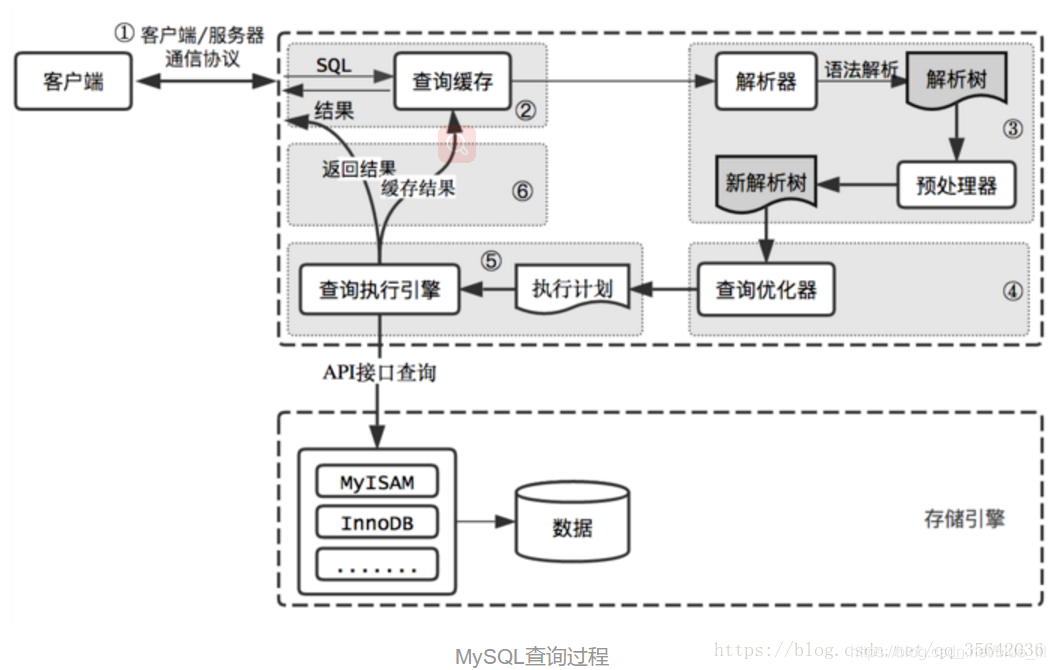
在开始介绍如何优化sql前,先附上mysql内部逻辑图让大家有所了解
① SQL语句及索引的优化
SQL语句的优化:
1、尽量避免使用子查询
2、避免函数索引
3、用IN来替换OR
另外,MySQL对于IN做了相应的优化,即将IN中的常量全部存储在一个数组里面,而且这个数组是排好序的。但是如果数值较多,产生的消耗也是比较大的。再例如:select id from table_name where num in(1,2,3) 对于连续的数值,能用 between 就不要用 in 了;再或者使用连接来替换。
4、LIKE前缀%号、双百分号、_下划线查询非索引列或*无法使用到索引,如果查询的是索引列则可以
5、读取适当的记录LIMIT M,N,而不要读多余的记录
select id,name
from table_name limit 866613, 20
使用上述sql语句做分页的时候,可能有人会发现,随着表数据量的增加,直接使用limit分页查询会越来越慢。
优化的方法如下:可以取前一页的最大行数的id,然后根据这个最大的id来限制下一页的起点。比如此列中,上一页最大的id是866612。sql可以采用如下的写法:
select id,name from table_name
where id> 866612 limit 20
6、避免数据类型不一致
7、分组统计可以禁止排序sort,总和查询可以禁止排重用union all
union和union all的差异主要是前者需要将结果集合并后再进行唯一性过滤操作,这就会涉及到排序,增加大量的CPU运算,加大资源消耗及延迟。当然,union all的前提条件是两个结果集没有重复数据。所以一般是我们明确知道不会出现重复数据的时候才建议使用 union all 提高速度。
另外,如果排序字段没有用到索引,就尽量少排序;
8、避免随机取记录
9、禁止不必要的ORDER BY排序
10、批量INSERT插入
11、不要使用NOT等负向查询条件
你可以想象一下,对于一棵B+树,根节点是40,如果你的条件是等于20,就去左面查,你的条件等于50,就去右面查,但是你的条件是不等于66,索引应该咋办?还不是遍历一遍才知道。
12、尽量不用select *
SELECT *增加很多不必要的消耗(cpu、io、内存、网络带宽);增加了使用覆盖索引的可能性;当表结构发生改变时,前者也需要经常更新。所以要求直接在select后面接上字段名。
13、区分in和exists
select * from 表A
where id in (select id from 表B)
上面sql语句相当于
select * from 表A
where exists(select * from 表B where 表B.id=表A.id)
区分in和exists主要是造成了驱动顺序的改变(这是性能变化的关键),如果是exists,那么以外层表为驱动表,先被访问,如果是IN,那么先执行子查询。所以IN适合于外表大而内表小的情况;EXISTS适合于外表小而内表大的情况。
索引的优化:
1、Join语句的优化:
尽可能减少Join语句中的NestedLoop的循环次数:“永远用小结果集驱动大的结果集”
用小结果集驱动大结果集,将筛选结果小的表首先连接,再去连接结果集比较大的表,尽量减少join语句中的Nested Loop的循环总次数
优先优化Nested Loop的内层循环(也就是最外层的Join连接),因为内层循环是循环中执行次数最多的,每次循环提升很小的性能都能在整个循环中提升很大的性能;
对被驱动表的join字段上建立索引;
当被驱动表的join字段上无法建立索引的时候,设置足够的Join Buffer Size。
尽量用inner join(因为其会自动选择小表去驱动大表).避免 LEFT JOIN (一般我们使用Left Join的场景是大表驱动小表)和NULL,那么如何优化Left Join呢?
1、条件中尽量能够过滤一些行将驱动表变得小一点,用小表去驱动大表
2、右表的条件列一定要加上索引(主键、唯一索引、前缀索引等),最好能够使type达到range及以上(ref,eq_ref,const,system)
性能优化,left join 是由左边决定的,左边一定都有,所以右边是我们的关键点,建立索引要建在右边。当然如果索引是在左边的,我们可以考虑使用右连接,如下
select * from atable
left join btable on atable.aid=btable.bid;//最好在bid上建索引
(Tips:Join左连接在右边建立索引;组合索引则尽量将数据量大的放在左边,在左边建立索引)
2、避免索引失效
1.最佳左前缀法则
如果索引了多列,要遵守最左前缀法则,指的是查询从索引的最左前列开始并且不跳过索引中的列。Mysql查询优化器会对查询的字段进行改进,判断查询的字段以哪种形式组合能使得查询更快,所有比如创建的是(a,b)索引,查询的是(b,a),查询优化器会修改成(a,b)后使用索引查询。
2.不在索引列上做任何操作
(计算、函数、(自动or手动)类型转换),会导致索引失效而转向全表扫描。
3.存储引擎不能使用索引中范围条件右边的列。
如这样的sql: select * from user where username='123' and age>20 and phone='1390012345',其中username, age, phone都有索引,只有username和age会生效,phone的索引没有用到。
4.尽量使用覆盖索引(只访问索引的查询(索引列和查询列一致))
如select age from user减少select *
5.mysql在使用不等于(!= 或者 <>)的时候无法使用索引会导致全表扫描。
6.is null, is not null 也无法使用索引,在实际中尽量不要使用null。
7.like 以通配符开头(‘%abc…’)mysql索引失效会变成全表扫描的操作。
所以最好用右边like 'abc%'。如果两边都要用,可以用select age from user where username like '%abc%',其中age是必须是索引列,才可让索引生效
假如index(a,b,c), where a=3 and b like 'abc%' and c=4,a能用,b能用,c不能用,类似于不能使用范围条件右边的列的索引
对于一棵B+树来讲,如果根是字符def,如果通配符在后面,例如abc%,则应该搜索左面,例如efg%,则应该搜索右面,如果通配符在前面%abc,则不知道应该走哪一面,还是都扫描一遍吧。
8.字符串不加单引号索引失效
9.少用or,用它来连接时会索引失效
10.尽量避免子查询,而用join
11、在组合索引中,将有区分度的索引放在前面
如果没有区分度,例如用性别,相当于把整个大表分成两部分,查找数据还是需要遍历半个表才能找到,使得索引失去了意义。
12、避免在 where 子句中对字段进行 null 值判断
对于null的判断会导致引擎放弃使用索引而进行全表扫描。
② 数据库表结构的优化:使得数据库结构符合三大范式与BCNF
③ 系统配置的优化
④ 硬件的优化
参考链接:
https://www.zhihu.com/question/36996520
http://liucw.cn/2018/01/07/mysql/索引优化分析/
作者:Chackca
来源:CSDN
原文:https://blog.csdn.net/qq_35642036/article/details/82820129
版权声明:本文为博主原创文章,转载请附上博文链接!