PROGRESSIVE GROWING OF GANS FOR IMPROVED QUALITY, STABILITY, AND VARIATION(PGGAN)
论文简述
PGGAN是英伟达在2018年发表在ICLR上的文章,主要贡献是采用了渐进式生成的方式训练GAN,实现从低分辨率到高分辨率的过渡,使这种方式有落地的可能。渐进式的方法能够提升训练的稳定性,提升训练速度,最终能够提升生成图像的质量。PGGAN首次生成1024×1024的人脸图像,在此之前128×128的已经相当困难且质量无法保证。此外,作者还提出些在训练过程中用到的trick等。
论文要点
论文背景
- 生成高分辨率图像的问题
- 高分辨率放大训练分布与生成分布之间的差异,进而放大梯度问题(WGAN中有详细介绍)
- 由于内存的约束,需要使用更小批量去处理数据,会导致训练不稳定
- GAN目前遇到的问题
- 多样性问题,传统GAN倾向于捕获训练集多样性中的一种
- 模型崩塌(判别器处理过度,导致G和D之间不健康竞争,成为猫捉老鼠的游戏)

渐进式生成
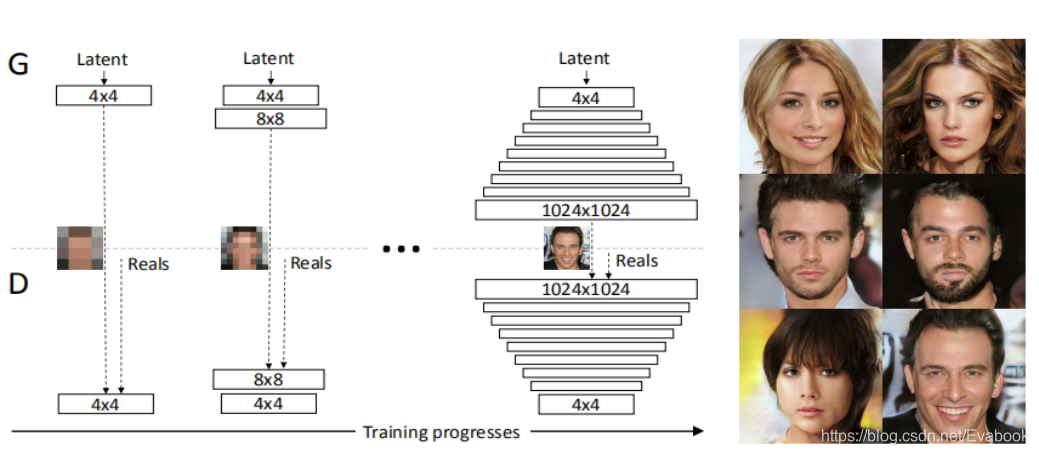
本文用到的渐进式生成的方式是先训练出低分辨率的图片,再逐步增加网络结构提升图片质量。生成器和分类器是镜像生成的,N×N是指这部分的卷积网络作用在N×N分辨率的图像上,在分辨率增长的过程中采用fade in形式的增长,早期分辨率低时学习到的是大规模结构特征,再分辨率逐渐增加的过程中,转移到细节逐步学习。
优势:增强训练稳定性,减少训练时间,提高图像质量
fade in形式
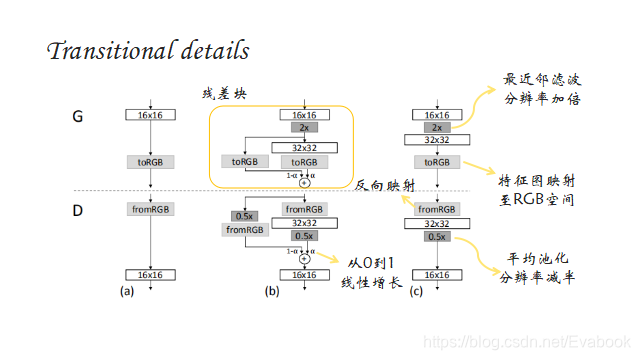
引入残差块的概念,使网络逐步适应高分辨率,直至构建成新的网络结构,这样有助于利用前期训练好的网络。在实际训练中,先将4×4的网络训练到一定程度(文中的条件是判别器判别了800k真实图片),然后再两个阶段进行交替:fade in网络,也即b;稳定网络,也即c。每个阶段均训练到一定程度后进入下一阶段。在训练阶段,真实图片也需要跟生成图片一样,根据α值融合两个分辨率的图像,然后输入到判别器中。
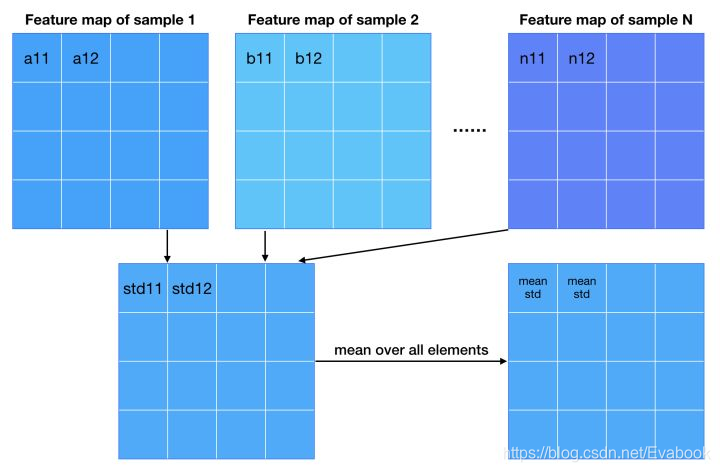
增加多样性-MSD
常见的增加多样性的两种方法:
- 优化loss让网络自己调整–WGAN
- 设计衡量多样性的度量加到判别器中–imporoved GAN-MD
文章在MD的基础上提出了MSD,引入了特征的标准差作为衡量标准,以样本为单位,求取相应特征图的相应位置的特征的标准差,最后将所有特征差求出平均值,然后生成一个mean std,并填充成特征图大小,和每个样本原有的特征图进行concat,然后将这些特征图送入到判别器中。这个特征图中包含了不同样本之间的差异性信息,送入判别器后,经过训练,生成样本的差异性也会与训练样本的相似。
图来自:https://zhuanlan.zhihu.com/p/30637133 【写的很详细,易懂】
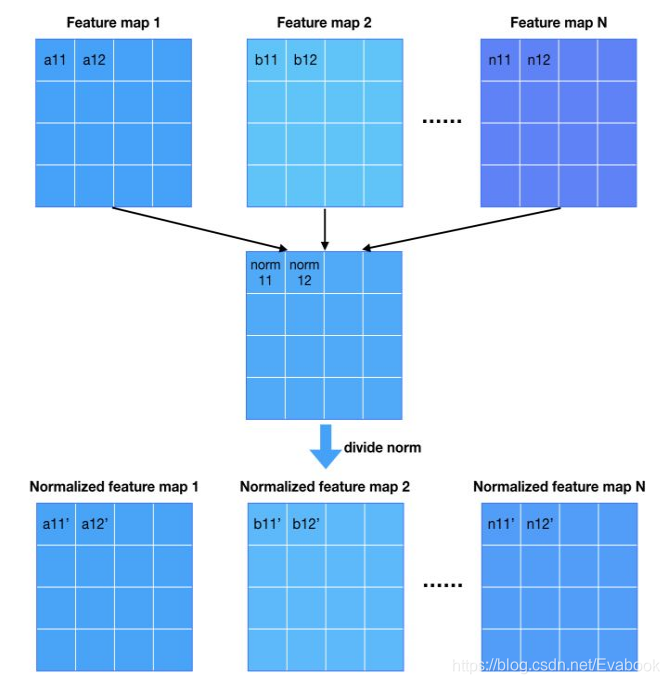
归一化-pixel norm
归一化主要是用来制约信号幅度,从而减少G与D之间的不正常竞争,沿channel维度对每个像素的特征长度归一化。
minibatch statistic layer沿着batch维度求标准差,而它沿着channel维度求norm
图源同上
代码及测试结果
代码来源:https://blog.csdn.net/u013139259/article/details/78885815
需要注意,Python 3.x中/操作是真正的除法,最终结果是float,而如果想要截断式除法,也就是说得到int型,应采用//操作
生成的是128×128的图像,应该是没有收敛,还是有些能区分的出来,边缘不够自然且出现混叠,有噪声,之后可以再优化下代码。
real
 train
train

思考
- 渐进式思想比较适用于大型网络的训练,之后可以多加考虑
- MSD为什么不只对样本的对应位置求平均,而是将所有标准差求平均,这样不能更好的去反映当前位置的差异性???-之后可以验证下
- 实际中还使用了WGAN-GP,推荐看下相关论文,会对GAN及GAN遇到的问题有更深一步的理解。