ProGAN其实是其他模型的基础,放在GAN的第二个小节。
1.介绍
1.1 GAN
因为这一篇是我们GAN章节的起点,GAN的一些相关知识我已经整理在了【这一篇】中,可以先进行了解一下
1.2高分辨率的难点 & 解决思路
(1)难点
- 更高的分辨率使生成的图像更容易与训练图像区分开来
- 由于内存限制,大分辨率也需要使用较小的小批量
(2)解决思路
从更容易的低分辨率图像开始,逐步增加生成器和鉴别器,并随着训练的进行,添加引入更高分辨率细节的新层。
1.3 本文核心贡献
- 一种新的训练策略:从更容易的低分辨率图像开始,逐步增加生成器和鉴别器,并随着训练的进行,添加引入更高分辨率细节的新层
- 一种新的初始化机制:阻止生成器参与不健康竞争从而引发模式奔溃。
2. ProGAN
2.1 逐步增加生成器和鉴别器
我们使用生成器和鉴别器网络,它们是彼此的镜像,并且总是同步增长。在整个训练过程中,两个网络中的所有现有层都保持可训练性。当新的层被添加到网络中时,我们会平滑地将它们引入,这避免了对已经训练有素的较小分辨率层的突然冲击。
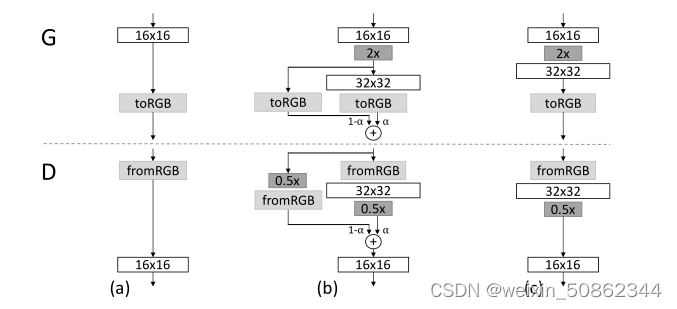
2.1.1 如何平滑的引入
说明了从16×16图像(a)到32×32图像(c)的转换。其中(b)为过渡期间

- 将在较高分辨率上操作的层视为残差块,其权重α从0线性增加到1。2×和0.5×分别指使用最近邻滤波和平均池化将图像分辨率加倍和减半。在生成器中的toRGB表示将特征向量投影到RGB颜色的层,而在鉴别器中的fromRGB则相反;两者都使用1×1卷积。
- 当训练鉴别器时,我们输入缩小后的真实图像,以匹配网络的当前分辨率。在分辨率转换期间,我们在真实图像的两个分辨率之间进行插值,类似于生成器输出如何组合两个分辨率。
2.2 生成器和鉴别器中的归一化
归一化的本质目的是限制信号幅度和竞争
2.2.1 均衡学习率
- 使用平凡的N(0,1)初始化,然后在运行时显式地缩放权重,而不是谨慎地初始化权重
之前的方法通过梯度更新的估计标准差对其进行归一化,从而使更新与参数的尺度无关,但是如果某些参数的动态范围比其他参数大,则需要更长的时间进行调整。
上述方法确保所有权重的动态范围以及学习速度相同。
2.2.2 生成器中的逐像素特征向量归一化
- 在每个卷积层之后将每个像素中的特征向量归一化为生成器中的单位长度。
- 公式:
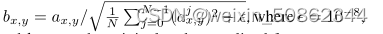
N是特征图的数量,ax,y和bx,y分别是以像素(x,y)为单位的原始特征向量和归一化特征向量。
3.代码
3.1 ProGAN模型
ProGAN模型初始化会调用getNetG和getNetD初始化生成器和鉴别器

生成器和鉴别器基本上是镜像对称的,

其中生成器中的toRGB核鉴别器中的fromRGB使用1×1卷积
3.1.1 均衡学习率
在一般情况下initBiasToZero和self.equalized都默认为true
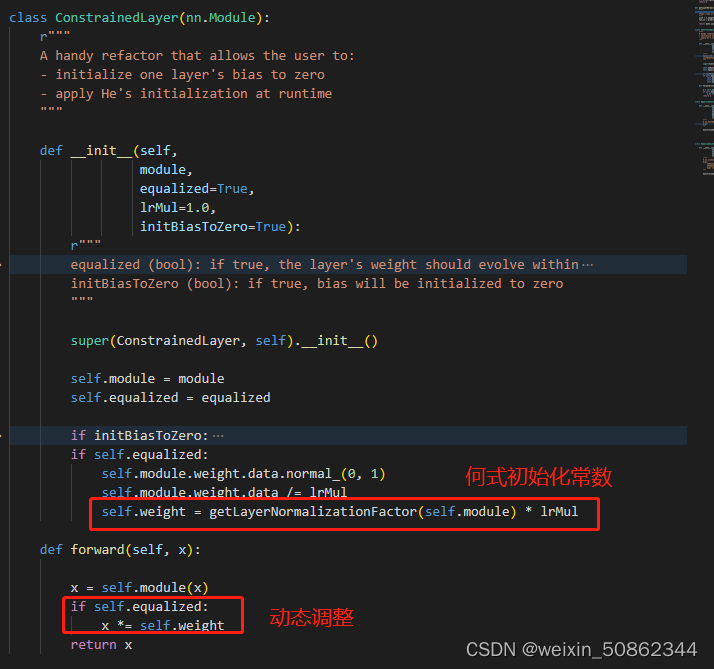
对每一个添加层中的EqualizedConv2d都会调用ConstrainedLayer来均衡学习率,从而确保所有权重的动态范围以及学习速度相同。
3.1.2 逐像素特征向量归一化
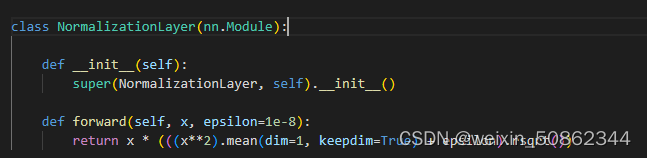
在每一次进行完卷积操作之后都会调用归一化层,将每个像素中的特征向量归一化为生成器中的单位长度。
3.1.3 前向传播
模型的前向传播过程就是可以基本上参考下图
3.2 训练
# 对于每个尺度,应更新混合因子alpha的迭代次数
_C.iterAlphaJump = [[], [0, 1000, 2000], [0, 1000, 4000, 8000, 16000],
[0, 2000, 4000, 8000]]
# 更新期间混合因子alpha的新值
_C.alphaJumpVals = [[], [1., 0.5, 0], [
1, 0.75, 0.5, 0.25, 0.], [1., 0.75, 0.5, 0.]]
# 每个尺度的卷积层的深度
_C.depthScales = [512, 512, 512, 512, 256, 128, 64, 32, 16]