Meta-SR
论文摘要
2019年CVPR的新文章,主要解决了之前的超分辨率中需要固定缩放因子,而本文提出meta-Upscale模块,使得单个模型便可以实现任意缩放因子(包含非整数)情况下的超分辨率。
论文重点
整体框架

主要包含两部分:feature learning module和meta-upscale module,前者提取低分辨率图像的特征,后者根据缩放因子和坐标偏移量因子求出相应映射参数,通过卷积便可获得最终的超分辨率图像。
meta-Upscale module
这里meta在于滤波器的参数不是直接从训练数据集中学习到的,而是通过另外的网络预测出来的,本文中是通过给定尺度使网络预测出相关的参数,实现该模块。该模块包含三个部分,对于SR的某个像素点,先找出其在LR中的对应点( 的红箭头指向的位置),然后根据缩放因子预测对应位置的滤波器的权重(weights部分),然后再将LR对应点与相应权重卷积得到SR中该像素点的值。
Location Projection
对于在高分辨率的像素(i,j),其对应在LR的特征位置:
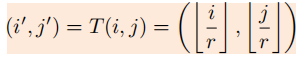
其中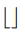 表示floor函数,相对应的位置选择如下图示例:上排图表示
的映射位置,下排图表示floor函数后的对应位置,当r为非整数时,不同的LR像素对应的SR像素的个数可能不同。对于映射到同一位置的两个SR像素,区分点就在于预测的权重值不同。
表示floor函数,相对应的位置选择如下图示例:上排图表示
的映射位置,下排图表示floor函数后的对应位置,当r为非整数时,不同的LR像素对应的SR像素的个数可能不同。对于映射到同一位置的两个SR像素,区分点就在于预测的权重值不同。

Weight Prediction
传统的upscale module会根据每个缩放因子决定滤波器的数量,并通过训练数据集学习权重W,而本文中的权重是通过单独的网络训练出来的。
对于每个像素点,用来输入到权重预测网络的相关向量为:
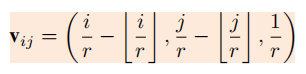
前两项是相对偏移量,后一项是缩放因子,这样可以避免不同缩放因子中
相同的位置产生相同的参数。
网络是由全连接层和激活层组成,每个像素点有个三维的输入
,对应的输出维度为(inC,outC,k,k),其中C表示channel,也即给定像素位置后,相关的参数全部一次性给出,共有HW个像素点,所以权重网络最终的大小为
。
Feature Mapping
获取到LR中对应像素和相关参数,就可以通过矩阵点积映射到SR像素,获取最终的对应点。
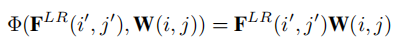
对应的位置是图中的蓝色部分,W则是weights向量。
算法

feature learning module
这部分可以选择任意的SISR网络,本文中选择的是RDN。
思考
- 在给定尺寸后,有很多 一样的像素点,这里可不可以再加些区分度
- 权重预测网络的loss是什么