---恢复内容开始---
一、IO操作
1.定义:在内存中存在数据交换的操作认为是IO操作,具体可分为三大类:
1>和终端交互:如input、output等
2>和磁盘交互:将内存中的数据永久的存储在磁盘(硬盘、U盘等)中
3>和网络交互:将内存中的数据发送到网络中
2.程序分类:根据IO操作量的大小分类
1>IO密集型程序:在程序执行中有大量IO操作,而cpu运算较少。消耗cpu较少,耗时长。
注:IO操作有一个共同的特点:耗时长,效率低(影响计算机的运行速度主要是硬盘----硬盘读写到内存的速度慢,即IO操作慢),此外,阻塞在IO操作中随处可见
固态硬盘(SSD)和机械硬盘(HDD):
固态硬盘的读取速度普遍可以达到400M/s,在开机和数据的载入中,速度得到了有效的提升,大幅度的提高了电脑的运行能力。写入速度也可以达到130M/s以上,
在写入大数据时,更加高效的储存能力大大缩短了办公时间。其读写速度是普通机械硬盘的3-5倍。
2>计算密集型程序:程序运行中计算较多,IO操作相对较少。cpu消耗多,执行速度快,几乎没有阻塞。
1.定义:在内存中存在数据交换的操作认为是IO操作,具体可分为三大类:
1>和终端交互:如input、output等
2>和磁盘交互:将内存中的数据永久的存储在磁盘(硬盘、U盘等)中
3>和网络交互:将内存中的数据发送到网络中
2.程序分类:根据IO操作量的大小分类
1>IO密集型程序:在程序执行中有大量IO操作,而cpu运算较少。消耗cpu较少,耗时长。
注:IO操作有一个共同的特点:耗时长,效率低(影响计算机的运行速度主要是硬盘----硬盘读写到内存的速度慢,即IO操作慢),此外,阻塞在IO操作中随处可见
固态硬盘(SSD)和机械硬盘(HDD):
固态硬盘的读取速度普遍可以达到400M/s,在开机和数据的载入中,速度得到了有效的提升,大幅度的提高了电脑的运行能力。写入速度也可以达到130M/s以上,
在写入大数据时,更加高效的储存能力大大缩短了办公时间。其读写速度是普通机械硬盘的3-5倍。
2>计算密集型程序:程序运行中计算较多,IO操作相对较少。cpu消耗多,执行速度快,几乎没有阻塞。
二、文件
1.定义:文件是保存在持久化存储设备(硬盘、U盘、光盘..)上的一段数据。从功能角度分为文本文件(打开后会自动解码为字符)、二进制文件(视频、音频等)。
在Python里把文件视作一种类型的对象,类似之前学习过的其它类型。
2.字节串(bytes):在python3中引入了字节串的概念(用字节的方式表达字符串),与str不同,字节串以字节序列值表达数据,更方便用来处理二进程数据。因此在python3中字节串是常见的二进制数据展现方式。
1>普通的ascii编码字符串可以在前面加b转换为字节串,例如:b'hello' 程序代码为:print("bytes",b'hello')
2>字符串转换为字节串方法 :encode() 程序代码为: s="dahdjd大家好" print("bytes:",s.encode())
3>字节串转换为字符串方法 : decode(); 注只有utf-8编码形式的字节串可以转化为字符串 s="dahdjd大家好" b = s.encode() print("str:",b.decode())
注:
1>字节串是python表达二进制编码的一种形式
2>字符串转换为字节串用encode()或者ascii码字符串前加b或者通过bytes()函数将字符串强转为字节串(如bytes(25))
3>字节串转换为字符串用decode()
4>通常情况下,只用utf-8的编码才可以用encode和decode相互转换
补充:
1>二进制(应用程序以字节为单位)
1G = 1024M 1M = 1024KB 1K = 1024bytes(应用层最小的存储单元为字节) 1byte = 8bit
2>bytes()内建函数
1>功能:将数据转换为字节串
2>参数: 整数n时,初始化一个长度为n的列表序列
字符串时, 将字符串转化为字节串
0-255整数列表时, 将列表整数转换为bytes字节串
1.定义:文件是保存在持久化存储设备(硬盘、U盘、光盘..)上的一段数据。从功能角度分为文本文件(打开后会自动解码为字符)、二进制文件(视频、音频等)。
在Python里把文件视作一种类型的对象,类似之前学习过的其它类型。
2.字节串(bytes):在python3中引入了字节串的概念(用字节的方式表达字符串),与str不同,字节串以字节序列值表达数据,更方便用来处理二进程数据。因此在python3中字节串是常见的二进制数据展现方式。
1>普通的ascii编码字符串可以在前面加b转换为字节串,例如:b'hello' 程序代码为:print("bytes",b'hello')
2>字符串转换为字节串方法 :encode() 程序代码为: s="dahdjd大家好" print("bytes:",s.encode())
3>字节串转换为字符串方法 : decode(); 注只有utf-8编码形式的字节串可以转化为字符串 s="dahdjd大家好" b = s.encode() print("str:",b.decode())
注:
1>字节串是python表达二进制编码的一种形式
2>字符串转换为字节串用encode()或者ascii码字符串前加b或者通过bytes()函数将字符串强转为字节串(如bytes(25))
3>字节串转换为字符串用decode()
4>通常情况下,只用utf-8的编码才可以用encode和decode相互转换
补充:
1>二进制(应用程序以字节为单位)
1G = 1024M 1M = 1024KB 1K = 1024bytes(应用层最小的存储单元为字节) 1byte = 8bit
2>bytes()内建函数
1>功能:将数据转换为字节串
2>参数: 整数n时,初始化一个长度为n的列表序列
字符串时, 将字符串转化为字节串
0-255整数列表时, 将列表整数转换为bytes字节串
3.文件读写-----三步(打开文件,读写文件,关闭文件)内建函数实现三步
1>打开文件:
file_object = open(file_name, access_mode='r', buffering=-1)
功能:打开一个文件,返回一个文件对象。
参数:file_name————文件名(可包含路径);
access_mode————打开文件的方式,如果不写默认为‘r’
buffering————参数0表示无缓冲(即边读编写),1表示有行缓冲(遇到换行时与磁盘交互一次),如果是大于1表示直接指明缓冲区大小。如果不写或为负数则采用系统默认的缓冲行为, 返回值:成功返回文件流对象。失败得到IOError。
注:
1>缓冲:系统自动的在内存中为每一个正在使用的文件开辟一个缓冲区,从内存向磁盘输出数据必须先送到内存缓冲区,装满缓冲区在一起送到磁盘中去。从磁盘中读数据,
则一次从磁盘文件将一批数据读入到内存缓冲区中,然后再从缓冲区逐个的将数据送到程序的数据区。这样减少了内存与磁盘的交互次数,提高磁盘读写效率,
也保护了磁盘的使用寿命。(如:word工作时突然断电,重新开启时可以加载就是利用了缓冲)

2>buffering = 1时表示行缓存,在写入数据时遇到\n时,自动刷新缓冲区,即将缓冲区的内容写入磁盘
3>采用系统默认缓冲时,需要缓冲区满后才能自动写入磁盘
4>无论什么缓冲,当程序中断结束或者文件被关闭的时候都会讲缓冲区的内容写入磁盘
5>flush(),该函数调用后会进行一次磁盘交互,将缓冲区里的内容写入到磁盘中
文件模式 操作
r 以读方式打开 文件必须存在
w 以写方式打开文件不存在则创建,存在清空原有内容
a 以追加模式打开
r+ 以读写模式打开 文件必须存在
w+ 以读写模式打开文件不存在则创建,存在清空原有内容
a+ 以读写模式打开 追加模式
rb 以二进制读模式打开 同r
wb 以二进制写模式打开 同w
ab 以二进制追加模式打开 同a
rb+ 以二进制读写模式打开 同r+
wb+ 以二进制读写模式打开 同w+
ab+ 以二进制读写模式打开 同a+
补充:
文件偏移量(文件指针):
1.定义:打开一个文件进行操作时系统会自动生成一个记录,记录中描述了我们对文件的一系列操作。其中包括每次操作到的文件位置。文件的读写操作都是从这个位置开始进行的(简而言之:其代表文件的当前读写操作位置,随读写操作移动)。
1>以r或者w方式打开文件时,便宜量在开头
2>以a方式打开文件时,偏移量在末尾
2.人为控制偏移量,函数为seek(offset[,whence]):
功能:移动文件偏移量位置
参数:offset代表字节数,代表相对于某个位置的偏移量(以字节数表示),负数表示向前移动,正数表示向后移动
whence代表基准位置,默认值为0,代表从文件开头算起,1代表从当前位置算起,2代表从文件末尾算起
3.tell()
功能:获取文件偏移量
返回值:相对文件开头偏移量,值为字节数
文件描述符:
1.定义:系统中每一个IO操作都会被分配一个整数作为编号,该整数即这个IO操作的文件描述符(便于操作系统识别,不会重复)。
2.获取文件描述符:
fileno():通过IO对象获取对应的文件描述符,返回值为编号数
文件管理函数:
1.获取文件大小:os.path.getsize(file)
2.查看文件列表:os.listdir(dir)
3.查看文件是否存在:os.path.exists(file)
4.判断文件类型是否为普通文件:os.path.isfile(file) 普通文件第一位“-”是普通文件,为“d”的是目录
5.删除文件:os.remove(file)
2>读写文件:
1.读取文件(三种方式):
1.read([size]):用来直接读取字节到字符串中,最多读取给定数目个字节。如果没有给定size参数(默认值为-1)或者size值为负,文件将被读取直至末尾。文件过大时候建议在non-blocking模式下使用。
2.readline([size]):读取打开文件的一行(读取下个行结束符之前的所有字节)。然后整行,包括行结束符,作为字符串返回。和 read() 相同,它也有一个可选的 size 参数,默认为 -1,代表读至行结束符。如果提供了该参数,那么在超过size个字节后会返回不完整的行。
3.readlines([sizeint]):该方法并不像其它两个输入方法一样返回一个字符串。它会读取所有(剩余的)行然后把它们作为一个字符串列表返回。它的可选参数sizeint代表返回的最大字节大小。
注:
文件对象本身也是一个迭代器,在for循环中可以迭代文件的每一行:
for line in f:
print(line)
2.写入文件(两种方式):
1.write(string):功能与 read() 和 readline() 相反。它把含有文本数据或二进制数据块的字符串写入到文件中去。
2.writelines(str_list):和 readlines() 一样,writelines()方法是针对列表的操作,它接受一个字符串列表作为参数,将它们写入文件。行结束符并不会被自动加入,所以如果需要的话,你必须在调用writelines()前给每行结尾加上行结束符。
3>关闭文件:
file_object.close()
打开一个文件后我们就可以通过文件对象对文件进行操作了,当操作结束后使用close()关闭这个对象可以防止一些误操作,也可以节省资源。
4>with操作:
python中的with语句使用于对资源进行访问的场合,保证不管处理过程中是否发生错误或者异常都会执行规定的“清理”操作,释放被访问的资源,比如有文件读写后自动关闭、线程中锁的自动获取和释放等。
with语句的语法格式如下:
with context_expression [as target(s)]:
with-body
通过with方法可以不用close(),因为with生成的对象在语句块结束后会自动处理,所以也就不需要close了,但是这个文件对象只能在with语句块内使用。
with open('file','r+') as f:
f.read()
三、网络编程
网络功能:实现资源共享,实现数据信息的快速传递。
1>OSI七层模型:
制定组织: ISO(国际标准化组织)
作用:使网络通信工作流程标准化
具体为:
应用层 : 提供用户服务,具体功能有应用程序实现
表示层 : 数据的压缩优化加密
会话层 : 建立用户级的连接,选择适当的传输服务
传输层 : 提供传输服务
网络层 : 路由选择,网络互联
链路层 : 进行数据交换,控制具体数据的发送
物理层 : 提供数据传输的硬件保证,网卡接口,传输介质
优点:
1. 建立了统一的工作流程

2. 分部清晰,各司其职,每个步骤分工明确
3. 降低了各个模块之间的耦合度,便于开发
2>四层模型(TCP/IP模型):
背景 : 实际工作中工程师无法完全按照七层模型要求操作,逐渐演化为更符合实际情况的四层
数据传输过程:
1. 发送端由应用程序发送消息,逐层添加首部信息,最终在物理层发送消息包。
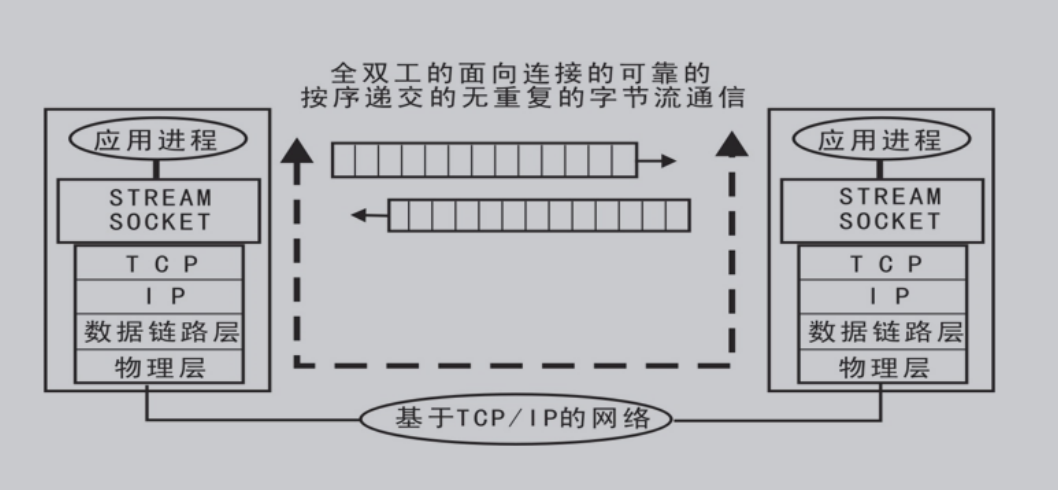
2. 发送的消息经过多个节点(交换机,路由器)传输,最终到达目标主机。
3. 目标主机由物理层逐层解析首部消息包,最终到应用程序呈现消息。
补充:
网络协议:在网络数据传输中,都遵循的规定,包括建立什么样的数据结构,什么样的特殊标志等。
3>网络基础概念
1.网络主机:
功能:标识一台主机在网络中的位置(地址)
本地地址 : 'localhost' , '127.0.0.1'
网络地址 : '172.40.91.185'
自动获取地址: '0.0.0.0'
查看本机网络地址命令: ifconfig
2.IP地址:
功能:确定一台主机的网络路由位置
结构:
IPv4 点分十进制表示 172.40.91.185 每部分取值范围0--255
IPv6 128位 扩大了地址范围
特殊IP:
127.0.0.1 本机测试IP
0.0.0.0 自动获取本机网卡地址
172.40.91.0 通常表示一个网段
172.40.91.1 通常表示一个网关
172.40.91.255 用作广播地址
3.域名:
定义: 给网络服务器地址起的名字
作用: 方便记忆,表达一定的含义
ping [ip] : 测试和某个主机是否联通
4.端口号:
作用:端口是网络地址的一部分,用于区分主机上不同的网络应用程序。
特点:一个系统中的应用监听端口不能重复
取值范围: 1 -- 65535
1--1023 系统应用或者大众程序监听端口
1024--65535 自用端口
---恢复内容结束---