0、前期准备
①安装nifi ,安装confluent ,oracle,mysql,jdk
②使用landoop使得confluent的kafka topic、kafka connect、schema registry拥有UI界面
kafka-topics-ui
schema-registry-ui
kafka-connect-ui
1、使用nifi实现oracle数据流入kafka topic
打开nifi的UI界面,新建processor,总体流程如下图:

需要的组件和设置如下
1.1 QueryDatabaseTable


创建并配置DBCPConnectionPool服务。
在QueryDatabaseTable processor的PROPERTIES界面,如图所示




在这一步,如果Database Driver Location(s)出现类似以下的警告:
'database-driver-locations' validated against 'home/user/driver-name.jar' is invalid because Not a valid URL.
解决办法为在url前加file:///前缀,注意是3个///,如下:
file:///home/user/driver-name.jar
1.2 SplitAvro


1.3 UpdateAttribute


再强调一遍,schema.name的值的格式必须为topicname-value,之前就因为不知道这个不起眼的格式,找bug找到令人崩溃。
在schema registry ui里创建schema方式如下:

我创建的schema如下:
{
"type": "record",
"name": "evolution",
"namespace": "com.landoop",
"doc": "This is a sample Avro schema to get you started. Please edit",
"fields": [
{
"name": "MATID",
"type": "int"
},
{
"name": "COEFFICIENT",
"type": "float"
},
{
"name": "NM",
"type": "string"
},
{
"name": "ENERGYTYPE",
"type": "int"
},
{
"name": "ID",
"type": "int"
},
{
"name": "ANM",
"type": "string"
}
]
}1.4 ConvertRecord



1.4.1 AvroReader配置

1.4.2 ConfluentSchemaRegistry创建与配置
在service界面,点击‘+’按钮添加ConfluentSchemaRegistry


1.4.3 AvroRecordSetWriter配置

版本号在schema registry-ui上看:
配置完后,将DBCPConnectionPool、ConfluentSchemaRegistry、AvroReader和AvroRecordSetWriter服务都依次启动。
1.5 PublishKafka


1.6 运行
上述配置完成无误后(①数据库连接正确 ②kafka topic已创建 ③schema registry里的schema命名和格式正确),右键点击空白界面,点击start:
运行后界面如下: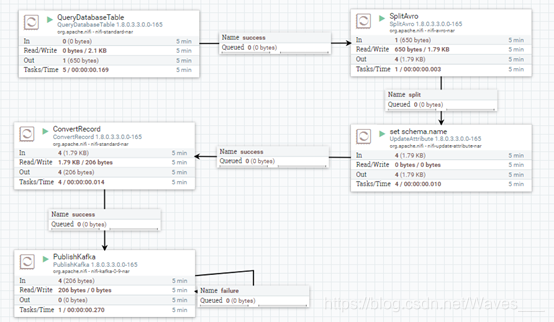
在oracle数据库中数据如下:
运行正常的话,kafka topic ui中oracleToMysql topic里的数据如下:
其中值为null的数据被过滤掉了。
注意:运行后,右键点击QueryDatabaseTable processor,选择view state,在我这里可以看到多了一项值,这个值使得kafka topic能够增量获取oracle数据。具体参考:Incremental Fetch in NiFi with QueryDatabaseTable
可以在停止processor后,点击Clear state,在重新开启后数据将再一次流入kafka topic。
2、使用kfaka connect将kafka topic的数据流入mysql
2.1 添加JdbcSinkConnector
在kafka connect-ui界面,添加jdbc sink connector。

name=test-oracleToMysql
connector.class=io.confluent.connect.jdbc.JdbcSinkConnector
topics=oracleToMysql
tasks.max=1
connection.url=jdbc:mysql://localhost:3306/test_db?user=root&password=xxx
auto.create=true
value.converter=io.confluent.connect.avro.AvroConverter
value.converter.schema.registry.url=http://39.11.11.11:8081添加完后,成功的话jdbc sink connector就直接处于运行状态了。
2.2 查看mysql

对于mysql中文显示乱码的问题,问题在于数据库和表的编码不为utf8或者utf8mb4。
例如,我的数据库名为test_db,表名为oracleToMysql,则在mysql里执行以下指令查看数据库和表的编码:
show create database test_db;
show create table oracleToMysql;如果显示的CHARSET不为utf8(或者utf8bm4),就需要重新设置一下编码了。
设置方法:
修改mysql的配置文件,在我的ubuntu上,mysql的配置目录为/etc/mysql,而我们mysql使用的配置文件为/etc/mysql/my.cnf,在my.cnf中加入下面4行:
[mysqld]
character-set-server=utf8mb4
[client]
default-character-set=utf8mb4
然后将mysql重启(/etc/init.d/mysql stop,/etc/init.d/mysql start)。
对于mysql中utf8和utf8mb4的区别,详见:浅谈MySQL中utf8和utf8mb4的区别
在mysql里输入以下指令:
show variables like "%character%";
编码都为为utf8或者utf8mb4就行了(除了中间那一个)。
注意:重新设置好编码后,最好将之前建的数据库和表删除重新建一次。例如,在我这就是删掉test_db数据库,然后重建test_db数据库,再次查看数据库和自动创建的表的编码:


参考:让MySQL支持中文