这篇博客用一个pandas的DataFrame类型的数据为例,字段名为了不与任何第三方库混淆,我们叫他 dataframe
这篇博客没有长篇大论,就是希望能够让大家直接复制代码,然后把dataframe变量改为自己的dataframe变量后立竿见影得到预期结果。
博客大多数的用例dataframe,运行 dataframe.head() 可以看到类似这样的样子,它源于真实数据:
| tbi_value | tsi | bci | bpi | bdi | bsi | mask | |
|---|---|---|---|---|---|---|---|
| 0 | 871.38 | 806.73 | 1523 | 854 | 782 | 768 | 0 |
| 1 | 875.55 | 807.63 | 1516 | 852 | 787 | 788 | 0 |
| 2 | 874.53 | 817.04 | 1515 | 858 | 798 | 810 | 0 |
| 3 | 874.61 | 817.56 | 1506 | 873 | 812 | 841 | 1 |
| 4 | 870.45 | 817.39 | 1503 | 889 | 824 | 864 | 1 |
import numpy as np
import pandas as pd目录
1.1.2 数据的均值、标准差、分位点、最小值、最大值、方差
1.描述性统计
1.1 数据基本信息
1.1.1 数据每个维度在计算机中的存储信息
dataframe.info()
可以看到下面这个输出:
<class 'pandas.core.frame.DataFrame'> # 表示是DataFrame类
RangeIndex: 1647 entries, 0 to 1646 # 行的index的值域
Data columns (total 7 columns): # 一共有多少列
tbi_value 1647 non-null float64 # 下面是每一列的描述, 列名称 | 多少个非空的值 | 值类型
tsi 1647 non-null float64
bci 1647 non-null int64
bpi 1647 non-null int64
bdi 1647 non-null int64
bsi 1647 non-null int64
mask 1647 non-null int32
dtypes: float64(2), int32(1), int64(4) # 这是统计每个类型的总个数
memory usage: 83.7 KB # 这是内存占用,83.7k只占了非常少1.1.2 数据的均值、标准差、分位点、最小值、最大值、方差
dataframe.describe()可以看到下面这个输出:
| tbi_value | tsi | bci | bpi | bdi | bsi | mask | |
| count | 1647 | 1647 | 1647 | 1647 | 1647 | 1647 | 1647 |
| mean | 720.862125 | 645.353297 | 1683.73224 | 1022.375228 | 1016.361263 | 850.625987 | 0.477231 |
| std | 176.724807 | 129.814479 | 862.435869 | 373.262046 | 360.824353 | 220.219328 | 0.499633 |
| min | 328.8 | 391.14 | 161 | 282 | 295 | 247 | 0 |
| 25% | 571.69 | 533.895 | 1104 | 727 | 751 | 694 | 0 |
| 50% | 758.21 | 640.19 | 1544 | 984 | 966 | 873 | 0 |
| 75% | 843.475 | 750.16 | 2198 | 1307 | 1204.5 | 989 | 1 |
| max | 1251.13 | 979.47 | 4329 | 2096 | 2337 | 1562 | 1 |
其中 mean表示平均值,std为标准差,25%,50%,75%都是四分位点的值。
1.1.3 线性相关系数(皮尔森相关系数)
dataframe.corr()| tbi_value | tsi | bci | bpi | bdi | bsi | mask | |
| tbi_value | 1 | 0.852856 | 0.763435 | 0.736944 | 0.83917 | 0.841345 | -0.052892 |
| tsi | 0.852856 | 1 | 0.473282 | 0.457007 | 0.535706 | 0.696586 | -0.060913 |
| bci | 0.763435 | 0.473282 | 1 | 0.693459 | 0.91269 | 0.633547 | -0.022511 |
| bpi | 0.736944 | 0.457007 | 0.693459 | 1 | 0.887674 | 0.820403 | -0.005235 |
| bdi | 0.83917 | 0.535706 | 0.91269 | 0.887674 | 1 | 0.832272 | -0.019859 |
| bsi | 0.841345 | 0.696586 | 0.633547 | 0.820403 | 0.832272 | 1 | -0.036575 |
| mask | -0.052892 | -0.060913 | -0.022511 | -0.005235 | -0.019859 | -0.036575 | 1 |
| max | 1251.13 | 979.47 | 4329 | 2096 | 2337 | 1562 | 1 |
值域为 【-1,1】,越靠近-1则是负相关,越靠近1则是正相关,越靠近0则越无关;
1.1.4 协方差矩阵
dataframe.cov()| tbi_value | tsi | bci | bpi | bdi | bsi | mask | |
| tbi_value | 31231.65755 | 19565.75481 | 116358.0163 | 48612.2877 | 53511.05415 | 32743.63278 | -4.670225 |
| tsi | 19565.75481 | 16851.79894 | 52987.08238 | 22144.1779 | 25092.58877 | 19913.7606 | -3.950785 |
| bci | 116358.0163 | 52987.08238 | 743795.6287 | 223234.4268 | 284017.9467 | 120326.3567 | -9.700207 |
| bpi | 48612.2877 | 22144.1779 | 223234.4268 | 139324.5554 | 119553.7344 | 67436.73277 | -0.976263 |
| bdi | 53511.05415 | 25092.58877 | 284017.9467 | 119553.7344 | 130194.2139 | 66132.73362 | -3.580166 |
| bsi | 32743.63278 | 19913.7606 | 120326.3567 | 67436.73277 | 66132.73362 | 48496.55262 | -4.024317 |
| mask | -4.670225 | -3.950785 | -9.700207 | -0.976263 | -3.580166 | -4.024317 | 0.249633 |
| max | 1251.13 | 979.47 | 4329 | 2096 | 2337 | 1562 | 1 |
这里协方差:大于0,就是正相关;小于0,就是负相关;等于0,就是完全无关;
绝对值越大,表示相关性的程度也越大(关联性越强),财务管理中有句话叫“协方差越小风险越低”,就是意味着这个变量对大局影响很小。
1.1.5 方差、中位数、众数
方差:
dataframe.var()中位数:
dataframe.median()众数:
dataframe.mode()| tbi_value | tsi | bci | bpi | bdi | bsi | mask | |
| 0 | 574.29 | 742.4 | 1613 | 727 | 598 | 899 | 0 |
| 1 | NaN | NaN | 1935 | NaN | 1090 | 944 | NaN |
这样的结果表示bci、bdi、bsi这两个指标有2个众数,而其他的都是1个众数
1.1.6 查看一列中不同数值的个数
len(dataframe['列名'].unique())这样可以直接显示dataframe这一列的不同种类的数量的个数,如果想要更详细的信息,可以直接使用:
dataframe['列名'].unique()1.2 数值计算
1.2.1 本列所有值累加、累乘
累加:
dataframe.cumsum()| tbi_value | tsi | bci | bpi | bdi | bsi | mask | |
| 0 | 871.38 | 806.73 | 1523 | 854 | 782 | 768 | 0 |
| 1 | 1746.93 | 1614.36 | 3039 | 1706 | 1569 | 1556 | 0 |
| 2 | 2621.46 | 2431.4 | 4554 | 2564 | 2367 | 2366 | 0 |
| 3 | 3496.07 | 3248.96 | 6060 | 3437 | 3179 | 3207 | 1 |
| 4 | 4366.52 | 4066.35 | 7563 | 4326 | 4003 | 4071 | 2 |
| ... | .... | ... | ... | ... | ... | ... | ... |
| 1642 | 1184476.07 | 1060500.7 | 2771523 | 1680054 | 1671110 | 1397796 | 783 |
| 1643 | 1185177.57 | 1061101.91 | 2771999 | 1680959 | 1671831 | 1398583 | 784 |
| 1644 | 1185871.16 | 1061700.62 | 2772420 | 1681881 | 1672543 | 1399372 | 785 |
| 1645 | 1186563.86 | 1062298.68 | 2772819 | 1682843 | 1673252 | 1400168 | 785 |
| 1646 | 1187259.92 | 1062896.88 | 2773107 | 1683852 | 1673947 | 1400981 | 786 |
看输出的信息,大家可以看到这是一层层累加下去,第n行的值就是原始数据 第 n + (n-1) + (n-2) + ... + 1 行的值的总和。
累乘:
dataframe.cumprod()与累加的输出类似,但累乘数值容易爆表,最后会输出 inf 表示已超出数据存储范围。
2. 数据清洗
2.1 缺失值处理
可以通过下面的代码得到缺失值的数量:
dataframe.isnull().sum()也可通过简单的 .info() 来看缺失值的情况;
下面的代码可以得到 dataframe的缺失值占比情况:为0就表示没有缺失值
dataframe.isnull().sum()/len(dataframe)缺失值在进行求和时,会被默认视为0
2.1.1 确定值填充
使用 0 填充缺失值:
dataframe.fillna(0,inplace=True)也经常用这一列的平均值填充:
dataframe.fillna(dataframe.mean(),inplace=True)2.1.2 参考当前列其他值填充
dataframe.fillna(method='pad',inplace=True) #参考前面值dataframe.fillna(method='bfill',inplace=True) #参考后面值比如dataframe矩阵长这个样子:
| 0 | 1 | 2 | |
| 0 | 1 | NaN | 2 |
| 1 | 9 | NaN | NaN |
| 2 | 3 | 4 | NaN |
| 3 | 5 | 6 | 7 |
如果使用 dataframe.fillna(method='pad') 就可以得到:可以看到每列的缺失值都根据前面出现的值进行填充
| 0 | 1 | 2 | |
| 0 | 1 | NaN | 2 |
| 1 | 9 | NaN | 2 |
| 2 | 3 | 4 | 2 |
| 3 | 5 | 6 | 7 |
如果使用 dataframe.fillna(method='bfill') 就可以得到:同理,每列缺失值都根据它之后最先出现的值填充
| 0 | 1 | 2 | |
| 0 | 1 | 4 | 2 |
| 1 | 9 | 4 | 7 |
| 2 | 3 | 4 | 7 |
| 3 | 5 | 6 | 7 |
2.1.3 删除行
dataframe.dropna(axis = 0,inplace=True)这个可以直接删除有缺失值的行。
如果把axis=1,则会删除列,不建议这样做,除非这个维度的缺失值非常严重。
如果希望整行都缺失才删除,可以使用:
dataframe.dropna(axis=0, how='all', inplace=True)2.2 异常值处理
当出现明显不合理的值时,需要剔除掉这些异常值
2.2.1 根据确定条件筛选数据
dataframe= dataframe[ (dataframe['tsi'] < 800) & (dataframe['bdi'] > 600)]上面的例子筛选出了 dataframe中 'tsi' 指标 <800 且 'bdi' 指标 >600 的数据
这个套路可以根据确定的条件无限筛选出想要的数据,注意每个独立的小条件都要有括号 '( )'
2.2.2 根据正态分布3∂原则异常值检测
如果dataframe的某一列数据应该是呈现正态分布的,那么可以有如下筛选方案:
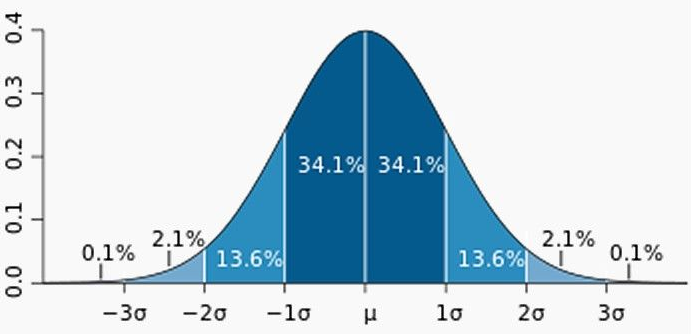
#.quantile(threshold)方法可以通过假定源数据服从正态分布,然后计算位于95%的点的值
#当 threshold = .95时:
# 95.449974的数据在平均数左右两个标准差的范围内
# 99.730020%的数据在平均数左右三个标准差的范围内
# 99.993666的数据在平均数左右三个标准差的范围内
def std_delete(dataframe,colname,threshold=.95):
se = dataframe[colname]
return dataframe[se < se.quantile(threshold)]
#剔除掉'tsi'中存在异常值的那一行
dataframe = std_delete(dataframe , colname='tsi')如果threshold = .95筛选条件感觉不太合适,也可以使 threshold = .97 或是 .99 ,但如果.99还不行,那么就不能主观的认为是正态分布,应该做假设检验了,看看是不是其他分布。
2.2.3 Z-score 异常值检测
zscore和3∂原则的计算思路相同,计算公式是:
其中 xi 是一个数据点,μ 是所有点 xi 的平均值,δ 是所有点 xi 的标准偏差。
def zscore_check(dataframe,colname,threshold=3):
se = dataframe[colname]
zscore = (se - se.mean()) / (se.std())
return dataframe[zscore.abs() < threshold]
dataframe = zscore_check(dataframe,'tsi')threshold 一般为 2.5 ,3.0 ,3.5
2.2.4 基于MAD的Z-score 异常值检测
MAD为(Mean Absolute Deviation,中位数绝对偏差),是单变量数据集中样本差异性的统计量,比标准差更有弹性,它的计算公式是:

在维基百科中有细致的推理过程:https://en.wikipedia.org/wiki/Median_absolute_deviation
根据推理,我们得到一个结果:MAD 约等于 0.6745*δ ,这个结论有利于编程,因此:
def zscore_mad_check(dataframe,colname,threshold=3.5):
se = dataframe[colname]
MAD = (se - se.median()).abs().median()
zscore = ((se - se.median())* 0.6475 /MAD).abs()
return dataframe[zscore < threshold]
dataframe= zscore_mad_check(dataframe,'tsi')同样的, threshold 一般设置为 2.5 3.0 3.5
2.2.5 数据倾斜处理(偏度)
使用下面的代码确认数据是否倾斜:
from scipy import stats
stats.mstats.skew(dataframe['列名']).data如果值大于1,则证明存在倾斜;值越接近于0,越趋近于平缓,如果倾斜,则使用下面的代码处理:
dataframe['列名'] = np.log(dataframe['列名'])2.3 非数值类型处理
2.3.1 字符特征离散化(one-hot编码)
比如dataframe是这个样子:
| fc1 | fc2 | fc3 | |
| 0 | 1 | a | 2 |
| 1 | 9 | None | NaN |
| 2 | 3 | b | 2 |
| 3 | 5 | a | 7 |
| 4 | 5 | c | 7 |
现在 fc2 需要整理一下(离散化):
dataframe= pd.get_dummies(dataframe,dummy_na=True)| fc1 | fc3 | fc2_a | fc2_b | fc2_c | fc2_nan | |
| 0 | 1 | 2 | 1 | 0 | 0 | 0 |
| 1 | 9 | NaN | 0 | 0 | 0 | 1 |
| 2 | 3 | 2 | 0 | 1 | 0 | 0 |
| 3 | 5 | 7 | 1 | 0 | 0 | 0 |
| 4 | 5 | 7 | 0 | 0 | 1 | 0 |
原本是object类型,这样就可以很快的变成01类型加以区分,常用于有固定选项的特征中。
如果没有 “dummy_na = True”,dataframe中就不会有 “fc2_nan” 这一列;其他不变
也可以指定离散某一个数值型的特征:
# temp可以得到离散化 ‘fc1’ 这个特征的 dataframe
temp = pd.get_dummies(dataframe['fc1'],dummy_na=True)
# 把 dataframe与 temp 拼接起来并且删除已经被离散化的 ‘fc1’ 特征
dataframe= dataframe.join(temp).drop('fc1',axis = 1)可以得到把 fc1 离散化的结果:
| fc2 | fc3 | fc1_1.0 | fc1_3.0 | fc1_5.0 | fc1_9.0 | fc1_nan | |
| 0 | a | 2 | 1 | 0 | 0 | 0 | 0 |
| 1 | None | NaN | 0 | 0 | 0 | 1 | 0 |
| 2 | b | 2 | 0 | 1 | 0 | 0 | 0 |
| 3 | a | 7 | 0 | 0 | 1 | 0 | 0 |
| 4 | c | 7 | 0 | 0 | 1 | 0 |
2.4 时间序列
2.4.1 数据重采样
降采样:将时间线压缩
series.resample('M').sum()这里'M'代表将时间变为以月份来记,之后的 .sum() 是对合并的数据的操作,也可以改为 .mean() 求均值。
升采样:将时间线拉长
series.resample('D').sum()如果直接拉伸,会有很多NaN,因此升采样一般情况下需要考虑空值的填充
空值取前面的值:
series.resample('D').ffill()空值取后面的值:
series.resample('D').bfill()线性填充:
ts.resample('H').interpolate()参考链接(感谢)
pandas api:https://pandas.pydata.org/pandas-docs/stable/reference/index.html
sklearn api:https://scikit-learn.org/stable/modules/classes.html
Python数据分析之pandas统计分析:https://blog.csdn.net/A632189007/article/details/76176985
数据预处理与特征选择:https://blog.csdn.net/u010089444/article/details/70053104
总结:数据清洗的一些总结:https://blog.csdn.net/MrLevo520/article/details/77573757
异常值检测方法汇总:https://segmentfault.com/a/1190000015926584
用Python做单变量数据集的异常点分析:https://my.oschina.net/taogang/blog/279402
Minitab 18 支持:https://support.minitab.com/zh-cn/minitab/18/
更新计划
- 缺失值处理:拉格朗日插值法
- 异常值监测:基于 k-近邻的离群点检测
- 异常值处理:特征二值化
- Others
如果有 错误 or 补充 or 代码解释 or 其他需求,请留言;
因为博主正在写本科的毕业论文,所以更新进度不频繁;同时针对数据预处理之后训练模型主要使用机器学习sklearn库的“机器学习训练代码总结”已经在编写了;