数据准备
因为创建可以分区的数据表结构很繁琐,所以我直接使用了CDH hue自带的hive测试数据customers表
创建步骤,进入hue web 页面,在导航栏提示第二步的时候,创建hive 应用示例,几个经典hive结构表就创建好了
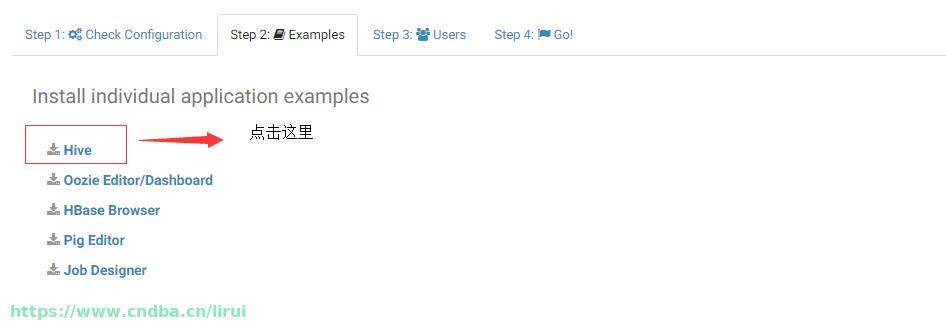
查看示例表,发现customers表结构很适合作为分区表,里面的address字段里面的state(州)很适合做分区处理,但是customers并不是分区表,我们首先新建一个测试数据库test,创建语句:
create database if not exists test
使用test表:
use test
创建分区表,按照state动态分区:
create table IF NOT EXISTS customers (
id INT,
name STRING,
email struct<email_format:string,frequency:string,categories:struct<promos:boolean,surveys:boolean>>,
address map<string,struct<street_1:string,street_2:string,city:string,state:string,zip_code:string>>
)
PARTITIONED BY (state STRING);
这里简化了一下结构删除了orders列
进入test库,执行从defualt库customers示例表获取数据动态分区插入test库customers表
insert overwrite table test.customers PARTITION (state) select id,name,email_preferences,addresses,if(addresses['shipping'].state is null,addresses['biling'].state,addresses['shipping'].state) as state from default.customers
这时候执行报错:
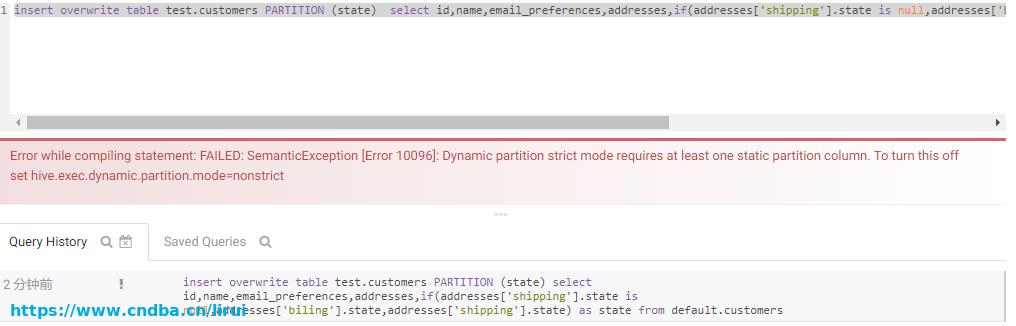
报错说动态分区严格模式至少需要一个静态分区列。 要关闭它,请设置:hive.exec.dynamic.partition.mode=nonstrict
我们设置一下
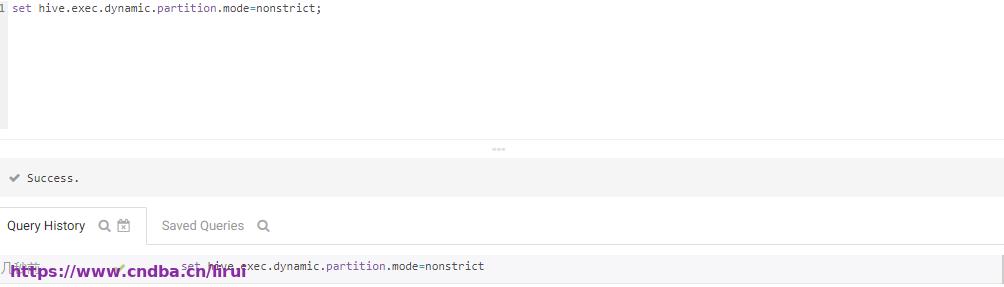
再次执行执行从defualt库customers示例表获取数据动态分区插入test库customers表,成功!
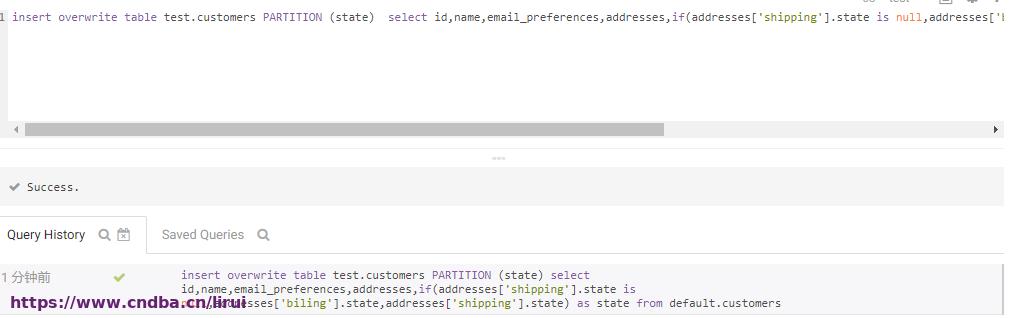
注意这里有个点:动态加载分区的时候,因为分区字段state是map字段里面的字段,map字段是hive独有的数据类型,map获取要通过key值获取,但是default.customers表里map的key只有两个值,shipping,billing,通过addresses[‘shipping’].state或者addresses[‘biling’].state取值都有可能为空值填充进来,hive没有ifnull函数,所以这里用了if(a is null,b,a)来替代,保证能正确取到state的值
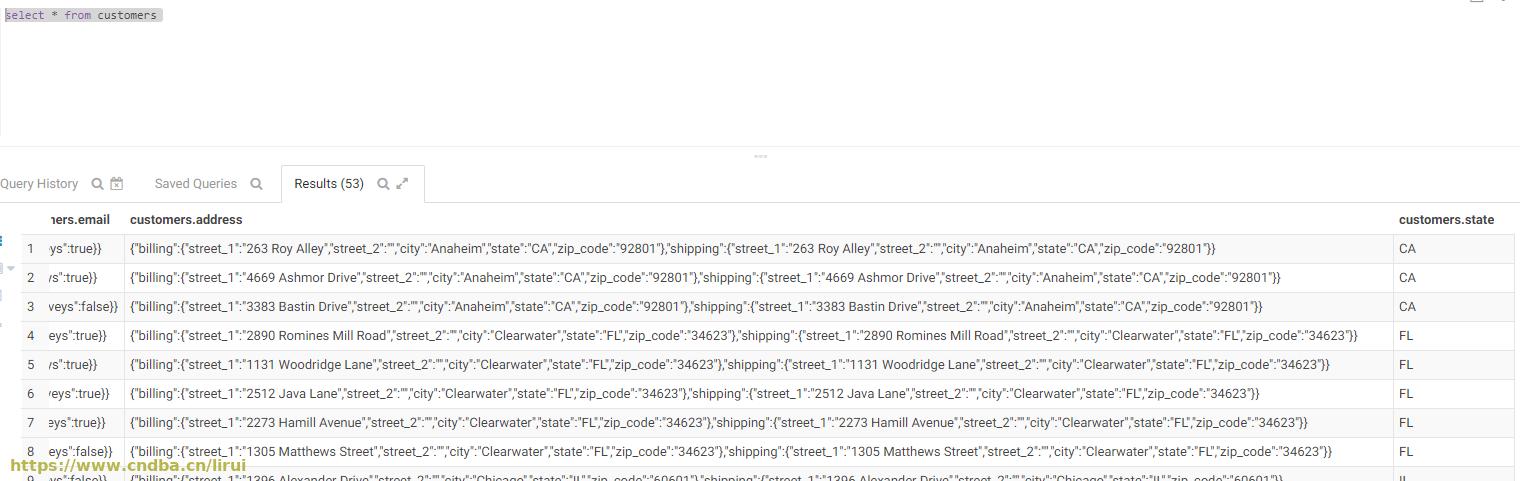
查询一下test.customers分区表
select * from test.customers
发现default.所有数据复制过来了,多了一个分区列state,并且都有值
进入分区表HDFS目录,对比一下分区前跟分区后两个表的差异:进入分区表HDFS目录,对比一下分区前跟分区后两个表的差异:
分区前default.customers目录地址/ user/ hive/ warehouse/ customers:

分区后test.customers目录地址/ user/ hive/ warehouse/ customers:
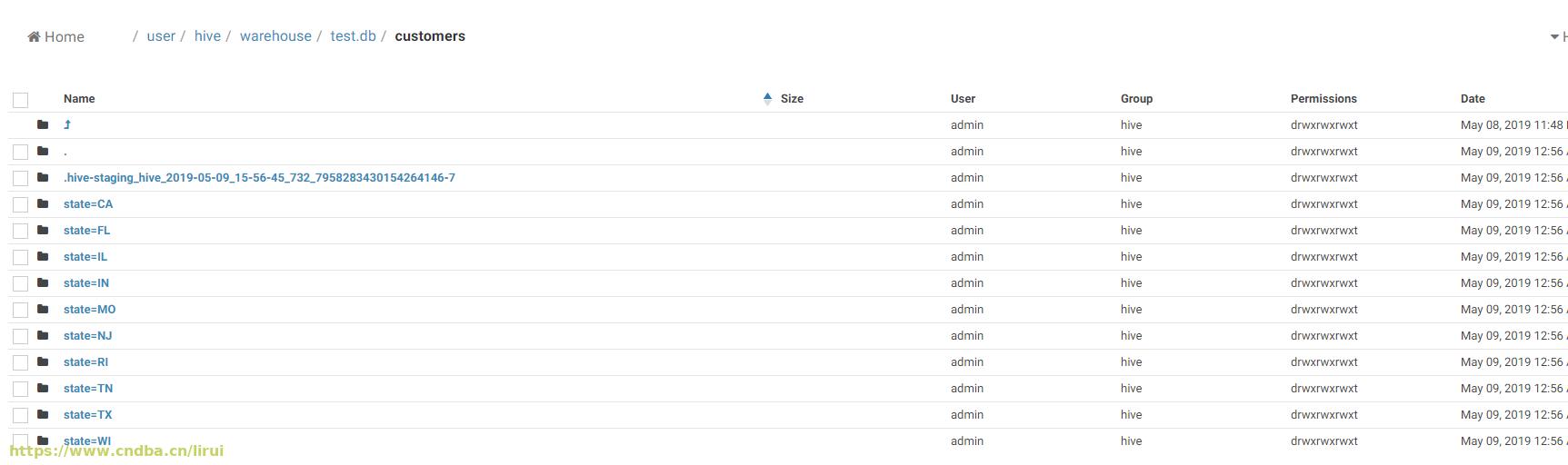
图中可以见到动态分区后,customers目录下面按照state的值分割了一块块小目录分层储存。
性能测试,对比一下分层之后的差异:
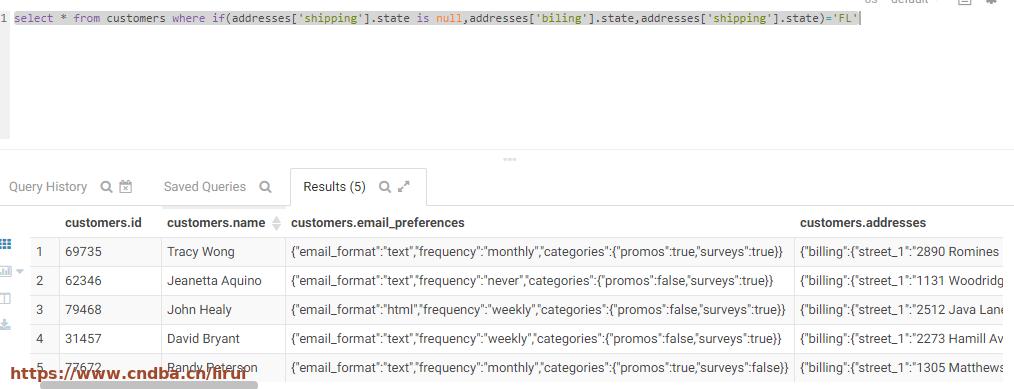
在default库执行:
select * from customers where if(addresses['shipping'].state is null,addresses['biling'].state,addresses['shipping'].state)='FL'
执行时间2.5s
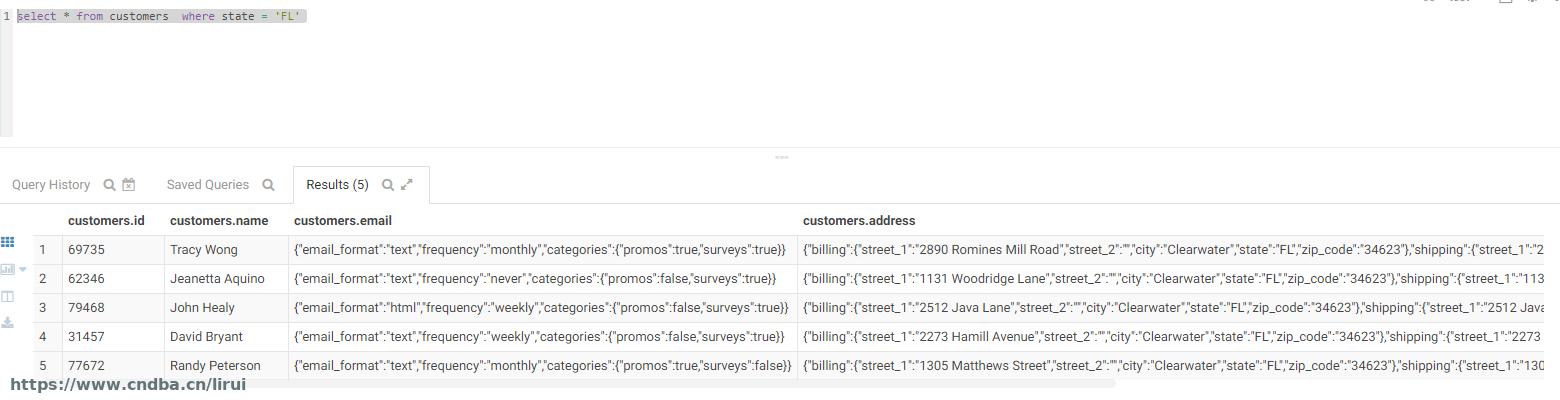
在test库执行:
select * from customers where state = 'FL'
一秒不到就出了结果,性能提升很大
通过以上的学习跟测试我认识到了动态分区在hive技术中的很重要的性能优势和应用场景