collections — High-performance container datatypes
在2.4版本中新加入,源代码Lib/collections.py和Lib/_abcoll.py。该模块实现了专用的容器数据类型来替代python的通用内置容器:dict(字典),list(列表), set(集合)和tuple(元组)。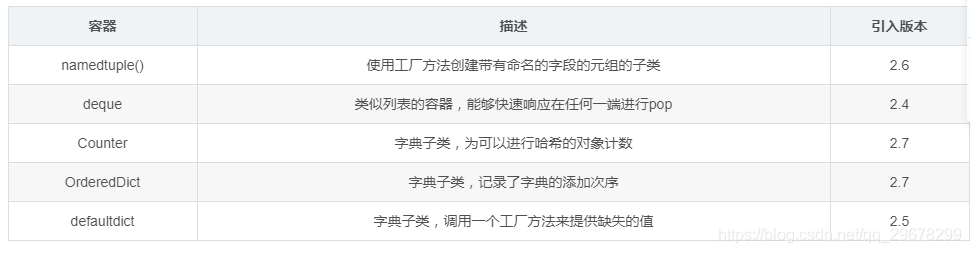
除了具体的容器类,collections模块还提供了abstract_base_classes来测试一个类是否体用了一个特定的接口,例如,这是可哈希的还是一个映射。
Counter
counter工具用于支持便捷和快速地计数,例如
from collections import Counter
cnt = Counter()
for word in ['red', 'blue', 'red', 'green', 'blue', 'blue']:
cnt[word] += 1
print cnt输出为
Counter({'blue': 3, 'red': 2, 'green': 1})Counter类介绍
class collections.Counter([iterable-or-mapping])一个Counter是dict子类,用于计数可哈希的对象。这是一个无序的容器,元素被作为字典的key存储,它们的计数作为字典的value存储。Counts允许是任何证书,包括0和负数。Counter和其它语言中的bags或者multisets类似。Counter中的元素来源如下:
>>> c = Counter() # a new, empty counter
>>> c = Counter('gallahad') # a new counter from an iterable
>>> c = Counter({'red': 4, 'blue': 2}) # a new counter from a mapping
>>> c = Counter(cats=4, dogs=8) # a new counter from keyword argsCounter对象有一个字典接口除了它们在缺失的items时候返回0而不是产生一个KeyError。设置计数为0并不会从一个counter中删除该元素,使用del来彻底删除。
>>> c = Counter(['eggs', 'ham'])
>>> c['bacon'] # count of a missing element is zero
0
>>> c['sausage'] = 0 # counter entry with a zero count
>>> del c['sausage'] # del actually removes the entry在2.7版本的python中,Counter额外支持字典中没有的三个功能

实际应用效果如下:
>>> c = Counter(a=4, b=2, c=0, d=-2)
>>> list(c.elements())
['a', 'a', 'a', 'a', 'b', 'b']
>>> Counter('abracadabra').most_common(3)
[('a', 5), ('r', 2), ('b', 2)]
>>> c = Counter(a=4, b=2, c=0, d=-2)
>>> d = Counter(a=1, b=2, c=3, d=4)
>>> c.subtract(d)
>>> c
Counter({'a': 3, 'b': 0, 'c': -3, 'd': -6})一些字典的常规方法对Counter对象有效,除了两个函数对于Counter的效用有些异常

对Counter有效的常用方法
sum(c.values()) # total of all counts
c.clear() # reset all counts
list(c) # list unique elements
set(c) # convert to a set
dict(c) # convert to a regular dictionary
c.items() # convert to a list of (elem, cnt) pairs
Counter(dict(list_of_pairs)) # convert from a list of (elem, cnt) pairs
c.most_common()[:-n-1:-1] # n least common elements
c += Counter() # remove zero and negative counts此外还为Counter提供了一些运算符来进行Counter对象的组合。加法和减法是对对应元素count的加减,与和或返回相应元素的最小/最大的count。输出的结果中会排除掉count小等于0的元素
>>> c = Counter(a=3, b=1)
>>> d = Counter(a=1, b=2)
>>> c + d # add two counters together: c[x] + d[x]
Counter({'a': 4, 'b': 3})
>>> c - d # subtract (keeping only positive counts)
Counter({'a': 2})
>>> c & d # intersection: min(c[x], d[x])
Counter({'a': 1, 'b': 1})
>>> c | d # union: max(c[x], d[x])
Counter({'a': 3, 'b': 2})
>>> c = Counter(a=3, b=1, e=1)
>>> d = Counter(a=1, b=2, f=-2)
>>> c + d # add two counters together: c[x] + d[x]
Counter({'a': 4, 'b': 3, 'e': 1})
>>> c - d # subtract (keeping only positive counts)
Counter({'a': 2, 'f': 3, 'e': 1})
>>> c & d # intersection: min(c[x], d[x])
Counter({'a': 1, 'b': 1})
>>> c | d # union: max(c[x], d[x])
Counter({'a': 3, 'b': 2, 'e': 1})注意,Counters原来设计是使用正整数来代表计数,然而,需要小心避免不必要地排除了需要其他类型或者负数值的用例。为了帮助这些用例,以下介绍了最小范围和类型的限制。
Counter类自身是一个字典子类,没有限制其key和value,value原为代表计数的数值,但是你能够存储任何东西在value字段
most_common方法需要value能够进行排次序。
对于in-place operations 例如c[key] += 1,value类型只需要支持加减,所以分数,浮点数和小数将能够正常工作,负数也能够被支持。这对于update和subtract方法也适用。
多重集的方法仅仅被设计于适用大于0的数,输入可以有0和负数,但是输出中只会产生大于0的数值的输出。对于数值类型没有限制,但是数值类型需要支持加法,减法和比较。
elements()方法需要整数的计数,将会忽略0和负数的计数。
源码分析
__init__
先来查看一下Counter中的__init__
class Counter(dict):
def __init__(*args, **kwds):
'''Create a new, empty Counter object. And if given, count elements
from an input iterable. Or, initialize the count from another mapping
of elements to their counts.
>>> c = Counter() # a new, empty counter
>>> c = Counter('gallahad') # a new counter from an iterable
>>> c = Counter({'a': 4, 'b': 2}) # a new counter from a mapping
>>> c = Counter(a=4, b=2) # a new counter from keyword args
'''
if not args:
raise TypeError("descriptor '__init__' of 'Counter' object "
"needs an argument")
self = args[0]
args = args[1:]
if len(args) > 1:
raise TypeError('expected at most 1 arguments, got %d' % len(args))
super(Counter, self).__init__()
self.update(*args, **kwds)可以看到,在__init__中主要是先调用父类(dict)的初始化,然后使用update函数来更新参数
update
查看一下update函数
def update(*args, **kwds):
'''Like dict.update() but add counts instead of replacing them.
Source can be an iterable, a dictionary, or another Counter instance.
>>> c = Counter('which')
>>> c.update('witch') # add elements from another iterable
>>> d = Counter('watch')
>>> c.update(d) # add elements from another counter
>>> c['h'] # four 'h' in which, witch, and watch
4
'''
# The regular dict.update() operation makes no sense here because the
# replace behavior results in the some of original untouched counts
# being mixed-in with all of the other counts for a mismash that
# doesn't have a straight-forward interpretation in most counting
# contexts. Instead, we implement straight-addition. Both the inputs
# and outputs are allowed to contain zero and negative counts.
if not args:
raise TypeError("descriptor 'update' of 'Counter' object "
"needs an argument")
self = args[0]
args = args[1:]
if len(args) > 1:
raise TypeError('expected at most 1 arguments, got %d' % len(args))
iterable = args[0] if args else None
if iterable is not None:
if isinstance(iterable, Mapping):
if self:
self_get = self.get
for elem, count in iterable.iteritems():
self[elem] = self_get(elem, 0) + count
else:
super(Counter, self).update(iterable) # fast path when counter is empty
else:
self_get = self.get
for elem in iterable:
self[elem] = self_get(elem, 0) + 1
if kwds:
self.update(kwds)可以看到,主要就是对输入中的每个元素,使用get方法获取其计数,如果没有就为0,然后增加计数器的值。如果counter为空,就直接调用dict中的update。
subtract
源码和update相似,但是是进行计数的减法运算。
__missing__
再分析其它的源代码,看到
def __missing__(self, key):
'The count of elements not in the Counter is zero.'
# Needed so that self[missing_item] does not raise KeyError
return 0看到这个方法是处理元素缺失时候返回0,那么是在什么地方调用这个函数的呢?在Counter的源代码里面没有用到这个__missing__方法,那是不是在父类dict中定义了这个方法,然后在子类中覆盖了这个方法呢?但是在__builtin__中间dict类的定义中并没有找到该方法,最后只有找实现了dict的源代码看看,发现有一段是这样写的:
ep = (mp->ma_lookup)(mp, key, hash);
if (ep == NULL)
return NULL;
v = ep->me_value;
if (v == NULL) {
if (!PyDict_CheckExact(mp)) {
/* Look up __missing__ method if we're a subclass. */
PyObject *missing, *res;
static PyObject *missing_str = NULL;
missing = _PyObject_LookupSpecial((PyObject *)mp,
"__missing__",
&missing_str);
if (missing != NULL) {
res = PyObject_CallFunctionObjArgs(missing,
key, NULL);
Py_DECREF(missing);
return res;
}
else if (PyErr_Occurred())
return NULL;
}
set_key_error(key);
return NULL;
}
else
Py_INCREF(v);看到,当当前为dict的子类的时候,就回去查找__missing__方法,如果有该方法的话就返回该方法产生的值,如果没有的话,或者不是dict的子类而是dict自身,就会产生一个KeyError。
关于__missing__总结一下就是dict本身没有这个方法,但是如果当前类为dict的子类的话,会在缺失的情况下查看有没有实现__missing__方法,如果有的话,就返回__miss__方法的值。所以Counter作为dict的子类实现了__missing__方法,在缺失的时候返回0。这也就是为什么在Counter类中,如果找不到key,会返回0而不是产生一个KeyError。
most_common
再分析其它的源代码,看到most_common方法
def most_common(self, n=None):
'''List the n most common elements and their counts from the most
common to the least. If n is None, then list all element counts.
>>> Counter('abcdeabcdabcaba').most_common(3)
[('a', 5), ('b', 4), ('c', 3)]
'''
# Emulate Bag.sortedByCount from Smalltalk
if n is None:
return sorted(self.iteritems(), key=_itemgetter(1), reverse=True)
return _heapq.nlargest(n, self.iteritems(), key=_itemgetter(1))可以看到,如果n的值没有被指定或者为None,就是返回按照计数从大到小排序的所有的元素,如果n被指定且不是None,那就调用了heapq.py中的nlargest的方法,看看这个方法的源代码:
def nlargest(n, iterable):
"""Find the n largest elements in a dataset.
Equivalent to: sorted(iterable, reverse=True)[:n]
"""
if n < 0:
return []
it = iter(iterable)
result = list(islice(it, n))
if not result:
return result
heapify(result)
_heappushpop = heappushpop
for elem in it:
_heappushpop(result, elem)
result.sort(reverse=True)
return result
_nlargest = nlargest
def nlargest(n, iterable, key=None):
"""Find the n largest elements in a dataset.
Equivalent to: sorted(iterable, key=key, reverse=True)[:n]
"""
# Short-cut for n==1 is to use max() when len(iterable)>0
if n == 1:
it = iter(iterable)
head = list(islice(it, 1))
if not head:
return []
if key is None:
return [max(chain(head, it))]
return [max(chain(head, it), key=key)]
# When n>=size, it's faster to use sorted()
try:
size = len(iterable)
except (TypeError, AttributeError):
pass
else:
if n >= size:
return sorted(iterable, key=key, reverse=True)[:n]
# When key is none, use simpler decoration
if key is None:
it = izip(iterable, count(0,-1)) # decorate
result = _nlargest(n, it)
return map(itemgetter(0), result) # undecorate
# General case, slowest method
in1, in2 = tee(iterable)
it = izip(imap(key, in1), count(0,-1), in2) # decorate
result = _nlargest(n, it)
return map(itemgetter(2), result) # undecorate上面需要注意的是,定义了两个的nlargest方法,而Python本身并没有函数重载这样的机制,所以后面的nlargest会覆盖前面的nlargest(不知道说法是不是准确,但是测试过效果是这样),由于两个方法之间使用了_nlargest=nlargest,所以_nlargest指向的是前一个的nlargest方法。也就是,我们使用heapq.py中的nlargest时候,使用的是后面一个的方法,如果使用_largest则使用的是前面的一个的方法。后面一个nlargest方法本质上就是对输入进行分析和包装,然后再调用前面一个nlargest的方法。而前面一个nlargest本质上使用的就是最大堆,然后返回前n个结果。
elements
源代码如下:
def elements(self):
'''Iterator over elements repeating each as many times as its count.
>>> c = Counter('ABCABC')
>>> sorted(c.elements())
['A', 'A', 'B', 'B', 'C', 'C']
# Knuth's example for prime factors of 1836: 2**2 * 3**3 * 17**1
>>> prime_factors = Counter({2: 2, 3: 3, 17: 1})
>>> product = 1
>>> for factor in prime_factors.elements(): # loop over factors
... product *= factor # and multiply them
>>> product
1836
Note, if an element's count has been set to zero or is a negative
number, elements() will ignore it.
'''
# Emulate Bag.do from Smalltalk and Multiset.begin from C++.
return _chain.from_iterable(_starmap(_repeat, self.iteritems()))其中用到了itertools中的一些方法
strmap,将给定sequence中的元组作为参数传入function,例如starmap(pow, [(2,5), (3,2), (10,3)]) –> 32 9 1000
repeat(object [,times]) 则是根据输入将object重复times次,返回迭代器。没有指定则不断产生object。
chain则是将所有输入中的可迭代对象拼接起来。
fromkeys
和dict不同,必须自己实现这个方法,如果没有实现就是用,会抛出NotImplementedError
@classmethod
def fromkeys(cls, iterable, v=None):
# There is no equivalent method for counters because setting v=1
# means that no element can have a count greater than one.
raise NotImplementedError(
'Counter.fromkeys() is undefined. Use Counter(iterable) instead.')copy
返回浅拷贝
def copy(self):
'Return a shallow copy.'
return self.__class__(self)__reduce__
当pickler遇到一个其无法识别类型的对象(例如一个扩展类型)的时候,其在两个方面查找pickle的途径,一个是对象实现了__reduce__()方法,如果提供了__reduce__()方法,在pickle的时候会调用__reduce__()方法,该方法会返回一个字符串或者一个元组。
如果返回一个字符串,这是一个代表全局变量的名字,其内容会被正常pickle。__reduce__()方法返回的字符串应该是对象和其模块相关的local name。pickle模块搜索模块的命名空间来决定对象的模块。
如果返回一个元组,其必须包含二到五个元素,分别如下:
一个可调用的对象能够用于创建对象的初始化版本,元组的下一个元素将会为这次调用提供参数,后续的元素提供额外的状态信息能够在随后在pickled之后的数据上重建数据。
一个可调用对象的参数元组
(可选)对象的状态,能够被传递给对象的__setstate__()方法
(可选)一个产生被pickle的列表元素的迭代器
(可选)一个产生被pickle的字典元素的迭代器
def __reduce__(self):
return self.__class__, (dict(self),)源代码中返回了两个参数,一个是类的名字,一个是参数元组,里面将自身转换为dict。
__delitem__
__delitem__为del obj[key]所需的方法(官网说明),源码如下:
def __delitem__(self, elem):
'Like dict.__delitem__() but does not raise KeyError for missing values.'
if elem in self:
super(Counter, self).__delitem__(elem)本质上就是一个不抛出KeyError的dict类的__delitem()__
__repr__
__repr__是“Called by the repr() built-in function and by string conversions (reverse quotes) to compute the “official” string representation of an object.”
源码中对__repr__实现如下:
def __repr__(self):
if not self:
return '%s()' % self.__class__.__name__
items = ', '.join(map('%r: %r'.__mod__, self.most_common()))
return '%s({%s})' % (self.__class__.__name__, items)如果没有对象就返回类的名字,否则返回类的名字并且返回利用most_common()方法得到类中的信息。
多集合运算
主要包括:加法(__and__),减法(__sub__),交集(__and__),并集(__or__)。需要注意的是,集合运算的结果中只会出现计数count大于0的元素!在以下的代码中也能够体现出来。
其中加法和减法主要是元素数量count的加减
def __add__(self, other):
'''Add counts from two counters.
>>> Counter('abbb') + Counter('bcc')
Counter({'b': 4, 'c': 2, 'a': 1})
'''
if not isinstance(other, Counter):
return NotImplemented
result = Counter()
for elem, count in self.items():
newcount = count + other[elem]
if newcount > 0:
result[elem] = newcount
for elem, count in other.items():
if elem not in self and count > 0:
result[elem] = count
return result
def __sub__(self, other):
''' Subtract count, but keep only results with positive counts.
>>> Counter('abbbc') - Counter('bccd')
Counter({'b': 2, 'a': 1})
'''
if not isinstance(other, Counter):
return NotImplemented
result = Counter()
for elem, count in self.items():
newcount = count - other[elem]
if newcount > 0:
result[elem] = newcount
for elem, count in other.items():
if elem not in self and count < 0:
result[elem] = 0 - count
return result交集主要是选相同元素中count最小的一个
def __and__(self, other):
''' Intersection is the minimum of corresponding counts.
>>> Counter('abbb') & Counter('bcc')
Counter({'b': 1})
'''
if not isinstance(other, Counter):
return NotImplemented
result = Counter()
for elem, count in self.items():
other_count = other[elem]
newcount = count if count < other_count else other_count
if newcount > 0:
result[elem] = newcount
return result并集主要是选相同元素中count最大的一个
def __or__(self, other):
'''Union is the maximum of value in either of the input counters.
>>> Counter('abbb') | Counter('bcc')
Counter({'b': 3, 'c': 2, 'a': 1})
'''
if not isinstance(other, Counter):
return NotImplemented
result = Counter()
for elem, count in self.items():
other_count = other[elem]
newcount = other_count if count < other_count else count
if newcount > 0:
result[elem] = newcount
for elem, count in other.items():
if elem not in self and count > 0:
result[elem] = count
return result