目录
1.1、加载nyc_census_sociodata.sql
在上一节中,我们看到了ST_Centroid(geometry)和ST_Union([geometry])函数,以及一些简单的示例。在本节中,我们将用它们做一些更详细的事情。
一、创建人口普查区域图表
在workshop的\data\目录中,有一个文件nyc_census_sociodata.sql包含属性数据,但不包含几何图形数据。该表包含有关纽约的、有趣的社会经济数据:通勤时间、收入和教育程度。然而有一个问题:数据按"普查区域(census tract)"汇总,而我们没有普查区域的几何图形数据!
在本节中,我们将:
- 加载nyc_census_sociodata.sql表
- 创建普查区域空间表
- 将属性数据连接到几何图形数据
- 然后利用我们的新数据进行一些分析
1.1、加载nyc_census_sociodata.sql
- 在PgAdmin中打开SQL查询窗口
- 从菜单中选择File->Open,并浏览到nyc_census_sociodata.sql文件
- 按"Run Query"按钮
- 如果你在PgAdmin中按下"Refresh"按钮,那数据表的列表现在应该包含nyc_census_sociodata表。
1.2、创建普查区域空间表
正如我们在上一节中所看到的,我们可用通过对blkid键的子串进行汇总,从人口普查块(census block)中构建更高级别地理区划的几何图形。为了得到普查区域(census tract),我们需要对blkid的前11个字符进行汇总分组。
-
360610001001001 = 36 061 000100 1 001 -
36 = State of New York -
061 = New York County (Manhattan) -
000100 = Census Tract -
1 = Census Block Group -
001 = Census Block
使用ST-Union创建新表:
-
-- Make the tracts table -
CREATE TABLE nyc_census_tract_geoms AS -
SELECT -
ST_Union(geom) AS geom, -
SubStr(blkid,1,11) AS tractid -
FROM nyc_census_blocks -
GROUP BY tractid; -
-- Index the tractid -
CREATE INDEX nyc_census_tract_geoms_tractid_idx -
ON nyc_census_tract_geoms (tractid);

1.3、将属性数据连接到空间数据
使用标准属性连接将普查区域(census tract)几何图形表和普查区域属性表连接起来:
-
-- Make the tracts table -
CREATE TABLE nyc_census_tracts AS -
SELECT -
g.geom, -
a.* -
FROM nyc_census_tract_geoms g -
JOIN nyc_census_sociodata a -
ON g.tractid = a.tractid; -
-- Index the geometries -
CREATE INDEX nyc_census_tract_gidx -
ON nyc_census_tracts USING GIST (geom);

1.4、回答一个有趣的问题
回答一个有趣的问题!"列出纽约拥有研究生学位的人所占比例排名前十的社区"。
-
SELECT -
100.0 * Sum(t.edu_graduate_dipl) / Sum(t.edu_total) AS graduate_pct, -
n.name, n.boroname -
FROM nyc_neighborhoods n -
JOIN nyc_census_tracts t -
ON ST_Intersects(n.geom, t.geom) -
WHERE t.edu_total > 0 -
GROUP BY n.name, n.boroname -
ORDER BY graduate_pct DESC -
LIMIT 10;

我们求和出我们感兴趣的统计数字,然后将它们相除。为了避免被零除的错误,我们不引入人口计数为零的区域。

注意:纽约地理学家将会对这份受过教育的社区名单中的"Flatbush"感到惊讶。为什么呢?答案将在下一节讨论。
二、多边形 / 多边形连接
在我们上面的感兴趣查询中,我们使用ST_Intersects(geometry_a, geometry_b)函数来确定每个社区(neighborhood)包含哪些普查区域(census tract)多边形。这就引出了一个问题:如果一块区域落在两个社区之间的边界上,该怎么办?这块区域和这两个社区相交,因此都将会包含在这两个社区的汇总统计数据中。
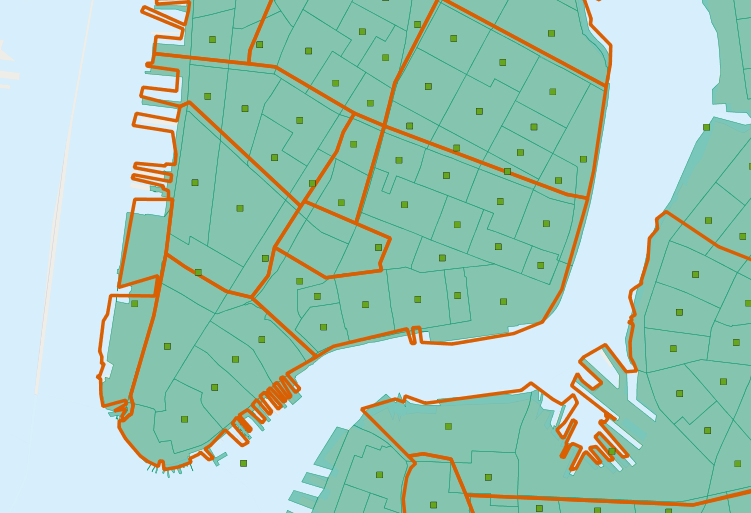
为了避免这种重复计算,有两种方法:
- 简单的方法是确保每个区域只落在一个社区(使用ST_Centroid(geometry))
- 复杂的方法是在两个社区的边界处将相交的人口普查区域(census tracts)分割(使用ST_Intersection(geometry, geometry))
以下是在我们上面的研究生教育查询中使用简单方法避免人口普查区域重复计算的示例:
-
SELECT -
100.0 * Sum(t.edu_graduate_dipl) / Sum(t.edu_total) AS graduate_pct, -
n.name, n.boroname -
FROM nyc_neighborhoods n -
JOIN nyc_census_tracts t -
ON ST_Contains(n.geom, ST_Centroid(t.geom)) -
WHERE t.edu_total > 0 -
GROUP BY n.name, n.boroname -
ORDER BY graduate_pct DESC -
LIMIT 10;

请注意,现在运行查询需要更长的时间,因为ST_Centroid函数必须在每个普查区域上运行。

避免人口普查区域的重复计算改变了查询结果!
2.1、那Flatbush呢?
特别的是,Flatbush社区已经从名单上消失了。在我们的数据表中,我们可以更仔细地看一看Flatbush社区的地图,就能看出原因所在。
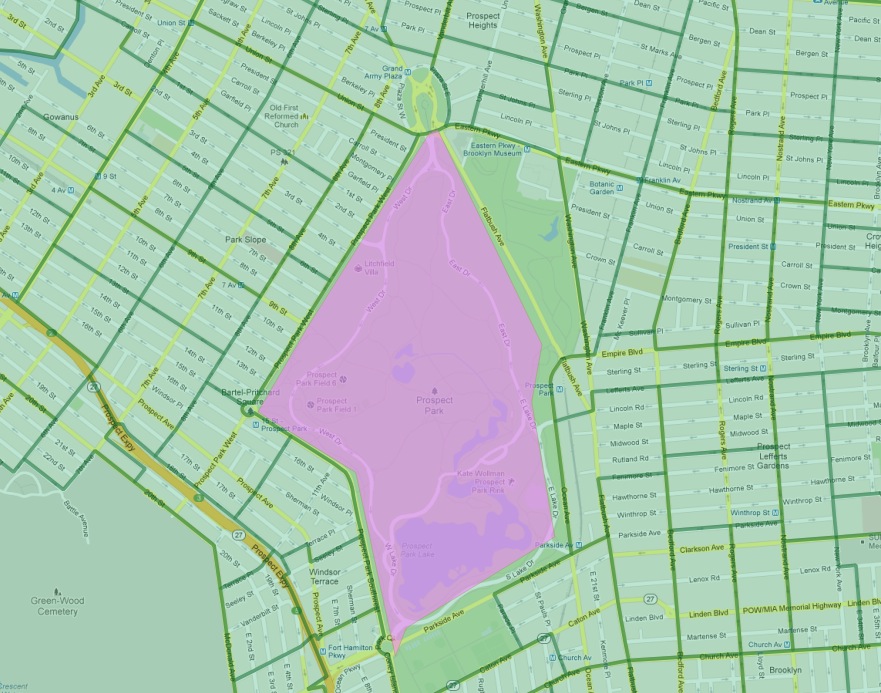
正如我们的数据源所定义的那样,Flatbush并不是传统意义上的社区,因为它只覆盖了Prospect Park(展望公园)的面积。该地区的人口普查记录自然为零居民。然而,Flatbush社区确实"刮去"了公园北侧的一块"昂贵"的人口普查区域(位于贵族化的Park Slope社区)。使用多边形 / 多边形测试时,这个人口普查区域被添加到Flatbush中,导致该查询的结果比例非常高。
三、大的半径距离的连接
一个有趣的问题是:"地铁站附近(500米以内)的居民的通勤时间与远离地铁站的居民的通勤时间有什么不同?"
然而,这个问题涉及到了重复计算的一些问题:许多人周围500米范围内有多个地铁站!
纽约市的总人口:
-
SELECT Sum(popn_total) -
FROM nyc_census_blocks;

![]()
纽约市距离地铁站周围500米范围内的人口:
-
SELECT Sum(popn_total) -
FROM nyc_census_blocks census -
JOIN nyc_subway_stations subway -
ON ST_DWithin(census.geom, subway.geom, 500);

![]()
查询结果比纽约市的总人口还要多!显然,我们的简单SQL语句正在产生一个很大的重复计算的错误。你可以在地铁的缓冲区图片上看到这个问题。
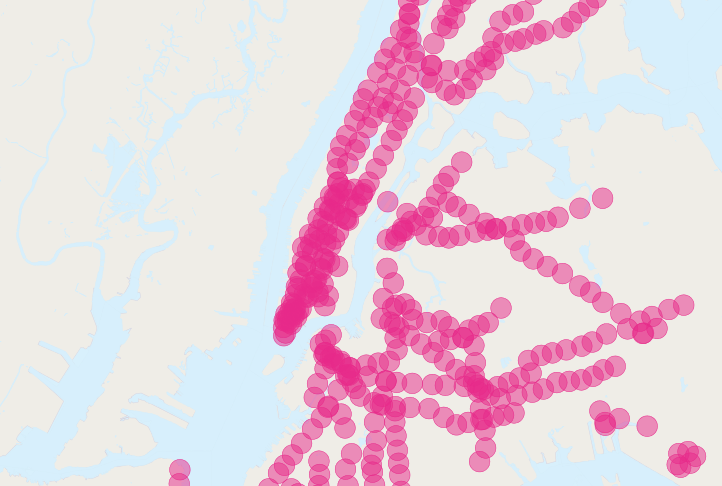
解决方案是在将不同的人口普查块数据传递到查询操作之前,确保只有不同的普查数据块。我们可以通过将查询分解为查找不同普查块的子查询来实现这一点:
-
WITH distinct_blocks AS ( -
SELECT DISTINCT ON (blkid) popn_total -
FROM nyc_census_blocks census -
JOIN nyc_subway_stations subway -
ON ST_DWithin(census.geom, subway.geom, 500) -
) -
SELECT Sum(popn_total) -
FROM distinct_blocks;

![]()
好多了!因此,纽约一半以上的人口离地铁站不到500m(步行约5-7分钟)。