一:直播的基本种类和架构

泛娱乐化直播
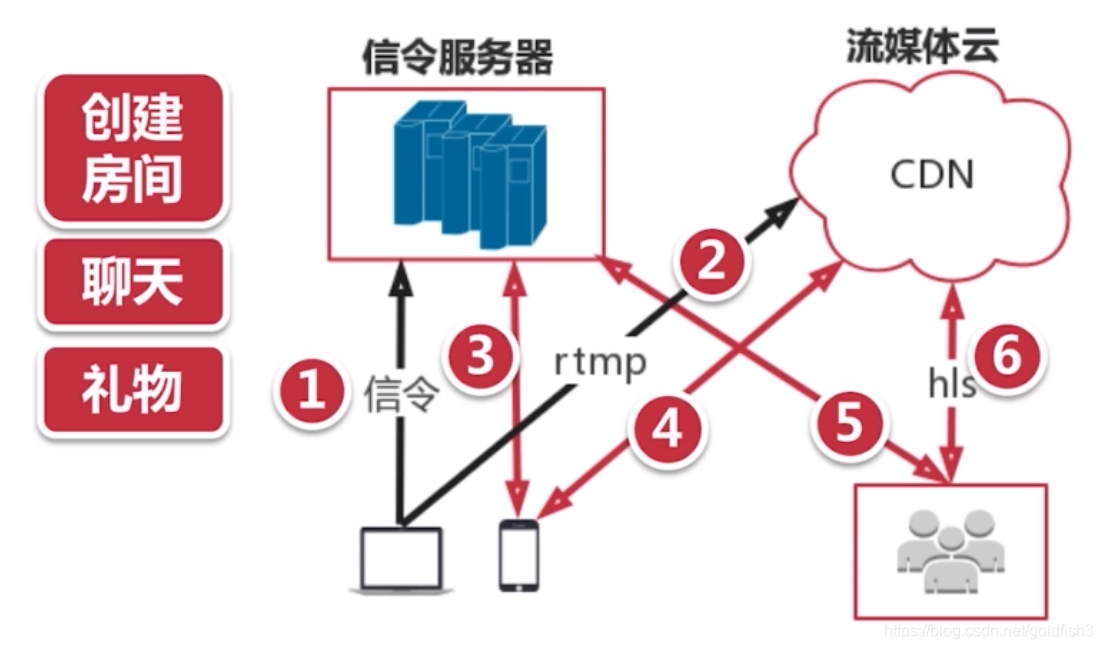
- 主播向信令服务器发起请求,创建一个房间
- 将视频信息上传到流媒体云
- 观众向信令服务器发起请求,进入一个房间
- 观众从流媒体云获取视频数据
实时互动直播架构
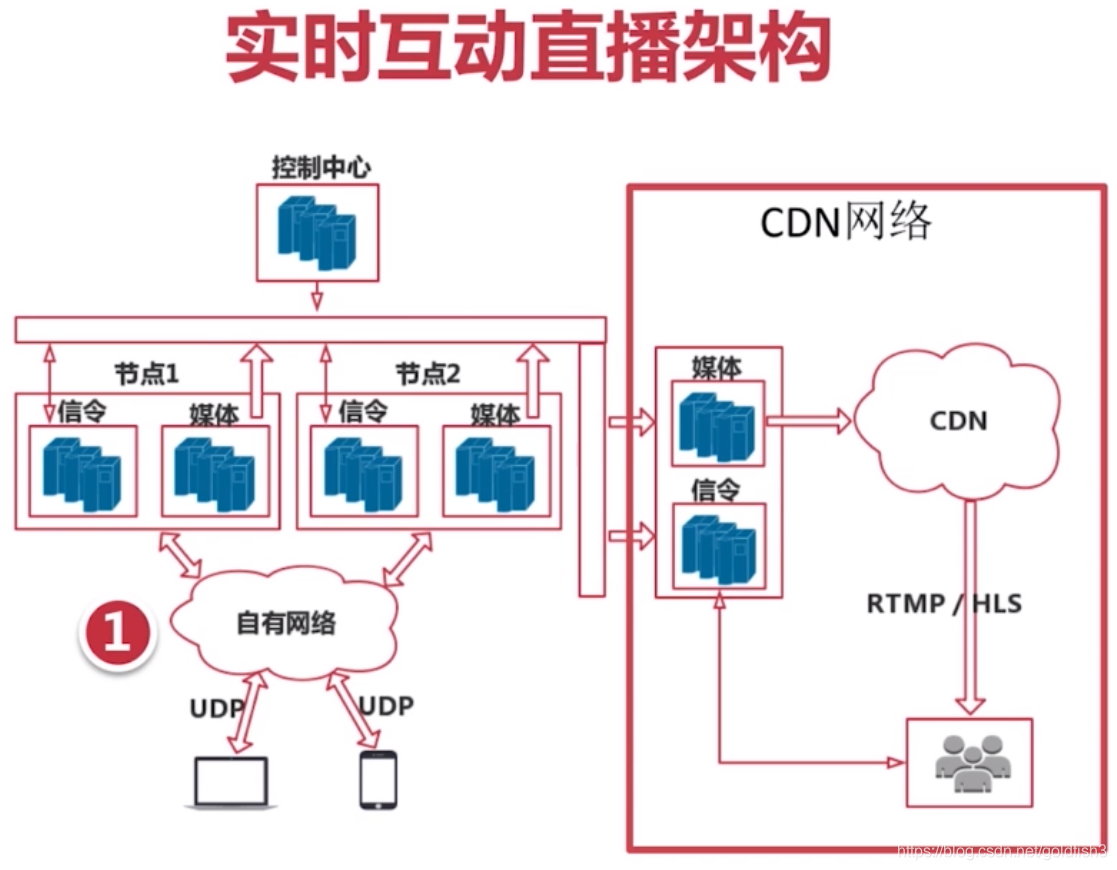
tcp:发送 确认 超时 重发
udp:只管发,不管收不收到
但是由于实时互动直播中,强调实时性,不一定所有的包都要受到,所以会使用udp传输协议。
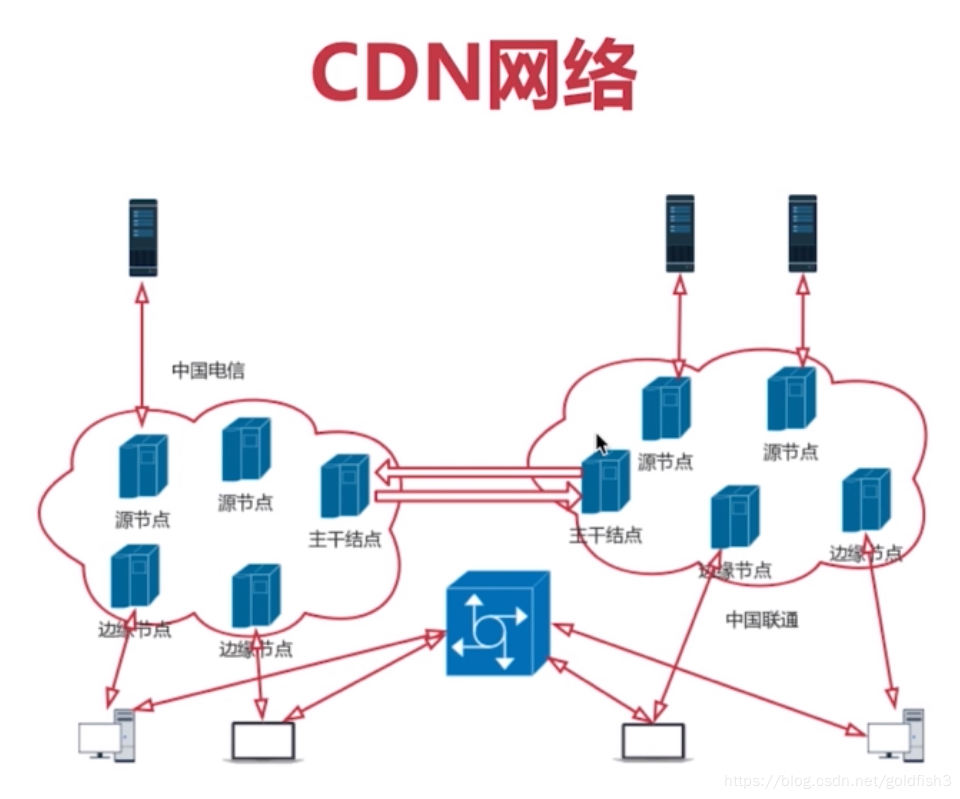
二:CDN网络
解决用户访问网络资源慢而出现的
边缘节点:用户从边缘节点上获取数据
二级节点:主干网节点,主要用于缓存,减轻源站压力
源站:CP(内容提供方)将内容放到源站
{kind=link}
三:音视频基本概念介绍
数字音频概念介绍
将模拟信号数字化,需要三个步骤:
- 采样:在时间轴上对信号进行数字化。
- 量化:在幅度上对每个采样进行数字化,如使用16bit的二进制信号来表示声音的一个采样,16bit所表示的范围是 [-32768,32767],共有65536个可能取值。
- 编码:对采样结果进行储存。
音频裸数据格式——脉冲编码调制数据PCM,描述一段PCM数据一般需要以下几个概念:
量化格式:如在CD中,为16bit
采样率:在CD中,为44100
声道数:在CD中为2
还有一个概念用于描述它的大小 —— 数据比特率,即1秒时间内的比特数目,按之前的数字,数据比特率计算为:
4410 * 16 * 2 = 1378.125 kbps
这样算下来,一分钟里,这类CD音质的数据需要占 10.09MB,太大了。
如果在网络上,传输这段音频,就需要进行压缩
压缩算法分为有损压缩和无损压缩
- 有损压缩:解压缩后数据可以完全复原
- 无损压缩:解压缩后数据不能完全复原,压缩比越小,丢失的越多。
常见的:PCM、WAV、AAC、MP3、Ogg都是压缩算法。
压缩主要去除人耳听觉范围之外的信号和因为掩蔽效应被掩蔽掉的信号。
下面介绍几种编码格式:
- WAV: 一种无损格式,在PCM数据格式前面加上44字节,分别用来描述采样率、声道数、数据格式等信息。
- MP3: 使用LAME编码的中高码率的MAP3文件,听感上非常接近WAV文件,一般来说在128kbit/s以上表现都还不错。
- AAC: 小于128kbit/s的码率下表现优异,多用于视频中的音频编码。
- Ogg: 用更小的码率达到更好的音质,但缺乏媒体服务软件的支持,适合语言聊天的音频消息场景。
视频和图像介绍:
图像的表示方法:
1:RGB表示
对于每个像素,一般使用8比特表示一个子像素,32比特表示一个像素。一副 1280*720的图像的大小为 1280 * 720 * 4=3.516MB
这也是位图在内存中所占的大小,如此大的图片,在网络上直接传输也是不大可能的,于是便有了图像压缩格式,如 JPEG,一种有损压缩,在提供良好的压缩性能的同时,具有较好的重建质量。但是这种压缩不能直接用于视频压缩,视频压缩不仅仅要考虑帧内编码,还要考虑帧间编码。
2:YUV表示方式
和RGB相比,优点在于只需要占用极少的频宽
Y:亮度,也叫灰阶值
U、V:色度信号
YUV,如YUV420P数据量大小为
1280 * 720 * 1 + 1280 * 720 * 0.5 = 1.318MB
比RGB小一些,但是以fbps 24来计算视频大小,仍然需要
1.318MB * 24fps * 90min * 60s = 166.8GB
还是太大了,所以对电影储存和流媒体播放,需要进行视频编码。
YUV和RGB的转化:
凡是渲染在屏幕上的东西,都要转化为RGB,YUV也不例外,转化公式如图
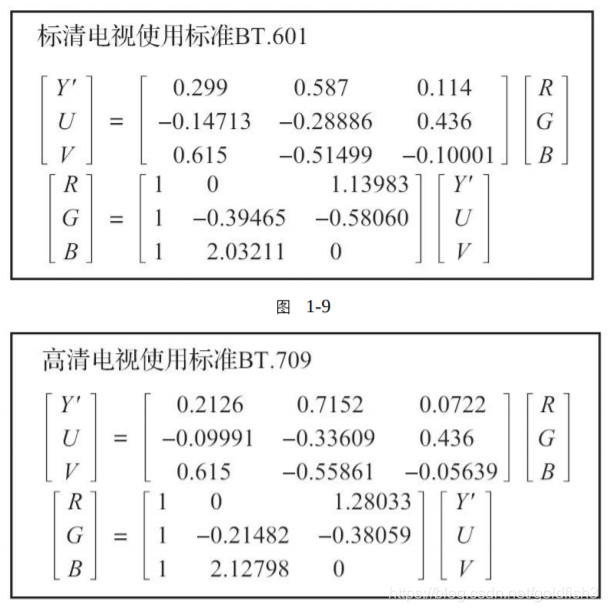
如在iOS平台中,使用摄像头采集出YUV数据之后(CMSampleBufferRef),上传显卡成为一个纹理ID(使用CVBufferGetAttachment获取YCbCrMatrix),这个时候就需要做YUV到RGB的转换。
视频编码
视频编码和音频编码一样,也是通过去除冗余信息来进行压缩的。冗余信息主要包括空间上的冗余信息和时间上的冗余信息。
使用帧间编码技术,去除时间上的冗余信息:
- 运动补偿:使用之前的局部图像来预测、补偿当前的局部图像。
- 运动表示:不同区域的图像需要使用不同的运动矢量来描述运动信息。
- 运动估计:从视频序列中抽取运动信息。
使用帧间编码技术,去除空间上的冗余信息:
ISO标准 Motion JPEG即MPEG,用于动态视频压缩算法,利用图像序列中的相关原则去除冗余,MP4指的就是Mpeg4AVC,流媒体用的最多的就是它了。
ITU-T制定的H.261…H.264是一套单独的体系,目前使用最多的就是H.264,压缩性能大大提高。
编码概念:
如前面所说,编码就是为了减少数据的容量
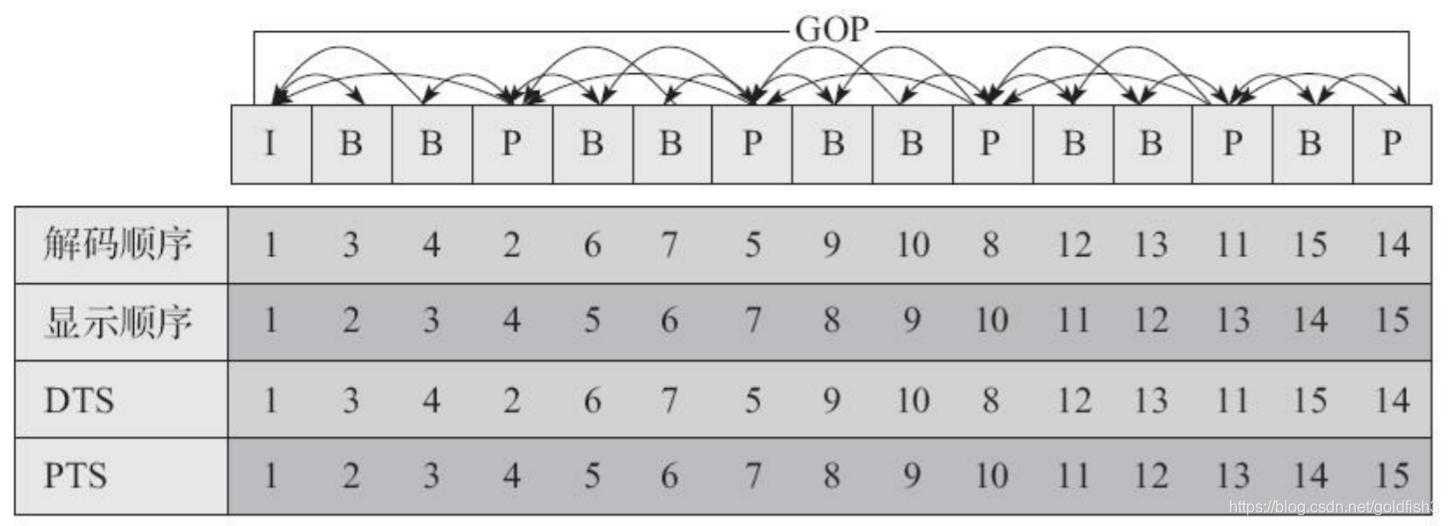
1:IPB帧
- I帧:帧内编码帧,通常是每个GOP(MPEG所使用的视频压缩技术)的第一个帧,经过压缩,成为随机访问的第一个参考点,可以当成静态图像,I帧主要去除空间上的冗余信息。
- P帧:考虑前面的I帧和P帧生成完整画面
- B帧:考虑前面的I帧、p帧、后面的p帧来生成一张完整的视频画面。
- IDR帧:一种特殊的I帧,这一帧之后所有参考帧只会参考到这个IDR帧,保证找到IDR帧之后就能解析出来。
2:PTS和DTS
DTS 主要用于视频的解码
PTS 主要用于在解码阶段进行视频的同步和输出
在没有B帧的情况下,DTS和PTS的输出顺序是完全相同的。
3:GOP的概念
两个 I 帧之间形成的一组图片,就是GOP。
gop_size:表示两个I帧之间帧的数目,通常来说,gop_size越大,这个画面质量就越好,但是解码端必须从接收到的第一个I帧开始才可以正确解码。提高视频质量的技巧中,有个技巧就是多使用B帧,一般来说I帧的压缩比为7(和JPG差不多),P是20,B可以达到50,可见B能节省大量空间。
ffmpeg

FFmpeg API的介绍与使用
一些基本术语:
- 容器/文件:特定格式的多媒体文件,如MP4、flv、mov等
- 媒体流:时间轴上的一段连续数据,如一段声音数据、一段视频数据
- 数据帧/数据包:通常一个媒体流是由大量的数据帧组成的,对于压缩数据,帧对应着编解码器的最小处理单元,分属于不同媒体流的数据帧交错储存于容器中。
- 编解码器: 以帧为单位实现压缩数据和原始数据之间的相互转换的