二:自定义输出
自定义输出
需求:过滤日志文件
把包含itstaredu的放在一个文件中 d:/itstaredu.log
把不包含itstaredu的放在另外一个文件 d:/other.log
1:自定义编写FileOutputFormate
package it.dawn.YARNPra.自定义.outputformat;
import java.io.IOException;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* @author Dawn
* @date 2019年5月11日23:45:47
* @version 1.0
* 类似自定义输入,根据源码自己写一个FileOutputFormat
* 继承FileOutputFormat
*/
public class FuncFileOutputFormat extends FileOutputFormat<Text, NullWritable>{
@Override
public RecordWriter<Text, NullWritable> getRecordWriter(TaskAttemptContext job)
throws IOException, InterruptedException {
FileRecordWriter recordWriter = new FileRecordWriter(job);
return recordWriter;
}
}
2 : 自定义编写FileRecordWriter类
package it.dawn.YARNPra.自定义.outputformat;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
/**
* @author Dawn
* @date 2019年5月11日23:48:31
* @version 1.0
* 继承 RecordWriter
*/
public class FileRecordWriter extends RecordWriter<Text, NullWritable>{
Configuration conf=null;
FSDataOutputStream itstarlog=null;
FSDataOutputStream otherlog=null;
//1.定义数据输出路径
public FileRecordWriter(TaskAttemptContext job) throws IOException {
//获取配置信息
conf=job.getConfiguration();
//获取文件系统
FileSystem fs=FileSystem.get(conf);
//定义输出路径
//默认就是那个我们很熟悉的part-r-00000。这里我们把它自定义成itstar.log other.log
itstarlog=fs.create(new Path("f:/temp/outputformateSelf/fileoutSelf1/itstar.log"));
otherlog=fs.create(new Path("f:/temp/outputformateSelf/fileoutSelf2/other.log"));
}
//2.数据输出
@Override
public void write(Text key, NullWritable value) throws IOException, InterruptedException {
//判断的话根据key
if(key.toString().contains("itstar")) {
//写出到文件
itstarlog.write(key.getBytes());
}else {
otherlog.write(key.getBytes());
}
}
//3.关闭资源
@Override
public void close(TaskAttemptContext context) throws IOException, InterruptedException {
if(null != itstarlog) {
itstarlog.close();
}
if(null != otherlog) {
otherlog.close();
}
}
}
3:编写MR
mapper
package it.dawn.YARNPra.自定义.outputformat;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
/**
* @author Dawn
* @date 2019年5月11日23:58:27
* @version 1.0
* 直接代码一把梭,写出去
*/
public class FileMapper extends Mapper<LongWritable, Text, Text, NullWritable>{
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
context.write(value, NullWritable.get());
}
}
Reduce:
package it.dawn.YARNPra.自定义.outputformat;
import java.io.IOException;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class FileReducer extends Reducer<Text, NullWritable, Text, NullWritable>{
@Override
protected void reduce(Text key, Iterable<NullWritable> values,
Context context) throws IOException, InterruptedException {
//换个行吧!
String k = key.toString()+"\n";
context.write(new Text(k), NullWritable.get());
}
}
Driver类:
package it.dawn.YARNPra.自定义.outputformat;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* @author Dawn
* @date 2019年5月12日00:03:03
* @version 1.0
*
* 这里大家可能有个小疑问?
* 就是我们已近在自定义输出的时候,已经指定了输出位置。为什么我们这里还是要写输出位置?
*
* 大家可以这样想下,就是我们不进行自定义输出的时候,是不是每次任务之后,
* 会出现一大堆的文件 ._SUCCESS.crc .part-r-00000.crc _SUCCESS part-r-00000这4个的嘛。
* 而我们再自己写的自定义输出的时候,其实只是对part-r-00000文件指定了位置,而其他的什么 ._SUCCESS.crc ...这些没做处理啊!!
*
*/
public class FileDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 1.获取job信息
Configuration conf = new Configuration();
Job job=Job.getInstance(conf);
// 2.获取jar包
job.setJarByClass(FileDriver.class);
// 3.获取自定义的mapper与reducer类
job.setMapperClass(FileMapper.class);
job.setReducerClass(FileReducer.class);
// 4.设置map输出的数据类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
// 5.设置reduce输出的数据类型(最终的数据类型)
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
//设置自定outputFormat
job.setOutputFormatClass(FuncFileOutputFormat.class);
// 6.设置输入存在的路径与处理后的结果路径
FileInputFormat.setInputPaths(job, new Path("f:/temp/流量日志.dat"));
FileOutputFormat.setOutputPath(job, new Path("f:/temp/outputformateSelf"));
// 7.提交任务
boolean rs = job.waitForCompletion(true);
System.out.println(rs? "成功":"失败");
}
}
运行截图:
输入:
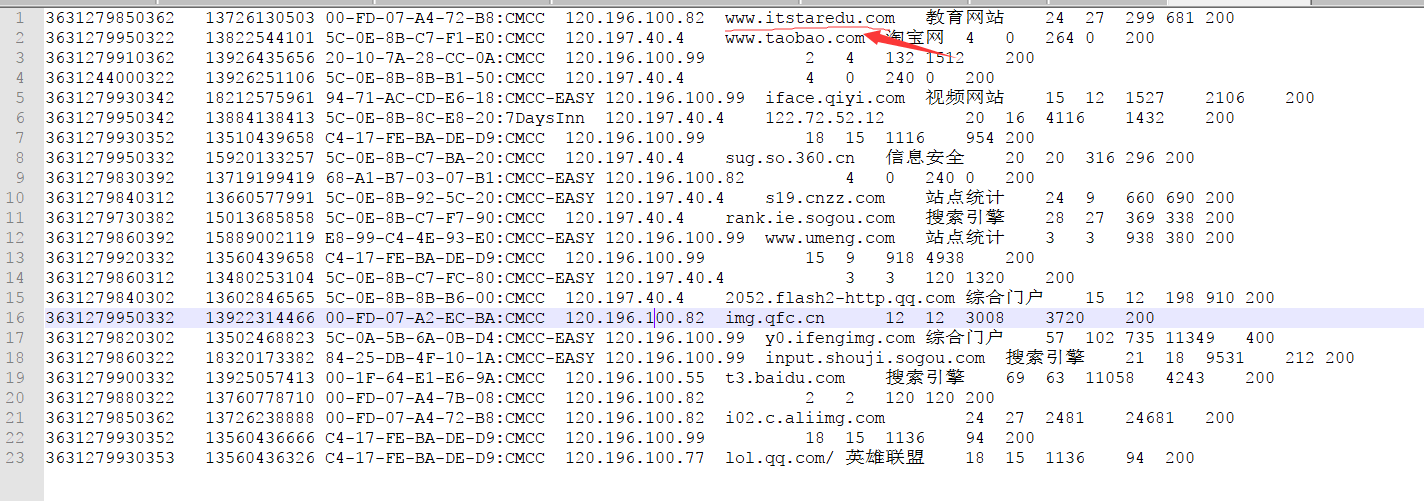
输出(看好了 路径根据 FileRecordWriter类中的一样 ):
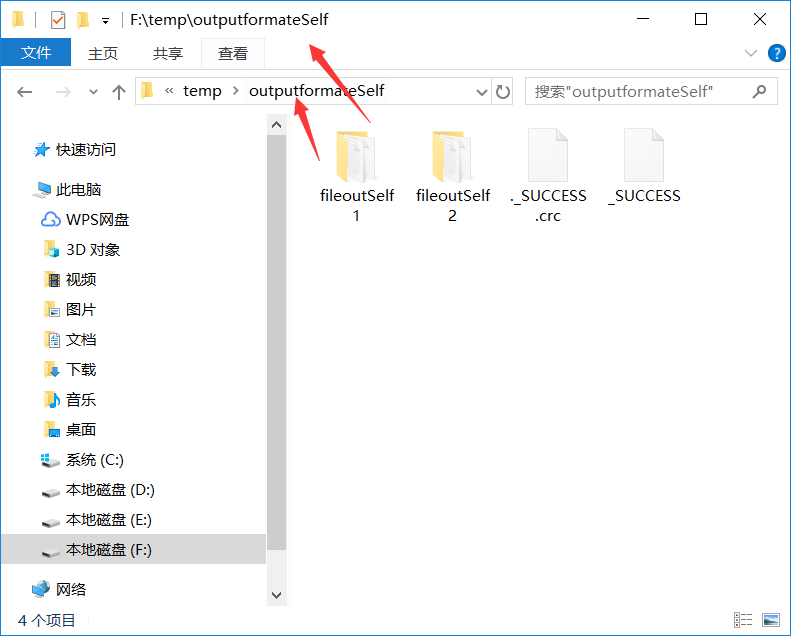
===============================================================
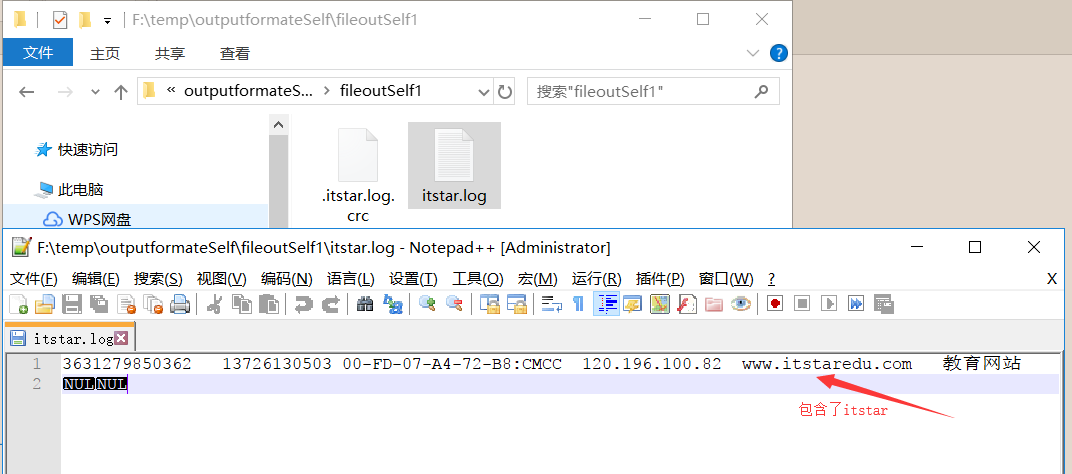
=============================================================================================