常见的分类损失函数

图1. 机器学习常见损失函数
备注: 图1中很坐标表示样本x的得分score
-
0-1 loss
对于分类任务而言, 我们要衡量一个分类器的性能好坏常常采用的一个naive的策略是:直接统计其在测试集上分类正确的样本个数N_correct,其取值越大,意味着分类器的性能越好,该度量也完全符合我们的初衷.统计分类正确样本个数的策略,本质上是在优化0-1损失函数:
![]() (1)
(1)
具体地:当一个样本被分类准确时,loss为0;被分类错误时,loss为1,它对应与图1中的黑色分段函数.
-
log-loss
对于二分类问题,logistics-regression是常采用的分类器,它假设:
![]()
容易得到它的似然函数为:
![]()
log-loss则定义为:
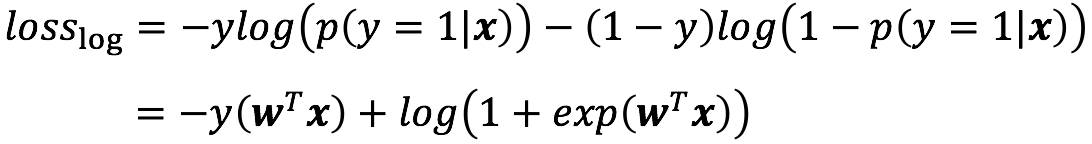 (2-a)
(2-a)
对应的函数图像为:

图2. log-loss函数曲线
可以看到(2-a)对应于y = 0和y = 1的部分完全对称,其中当score = 0时,log_loss = ln2. log-loss的函数曲线始终位于0-1loss之上,最小化log-loss本质上也是在优化0-1损失函数。在图1红色曲线即为log_loss[为了统一比较,对log-loss除以ln2使得它在y轴上的截距为1].
在多分类的情形下,有:
![]()
此时,log-loss则被拓展为softmax-loss:
![]() (2-b)
(2-b)
-
hinge-loss
对于二分类问题,svm是另一个常见的二分类器,它优化的问题为:

上述优化问题等价于
![]()
其中第一项为经验损失,即hingle-loss:
![]() (3-a)
(3-a)
与0-1 loss相比,它在0 < score < 1时loss的值仍大于0,即它不仅要求分类器在尽可能分类正确,同时也要求分类面要远离支撑向量,从而使得模型对于未知的样本具有更好的泛化能力。对于多分类的情形,相应的svm-loss为:
![]() (3-b)
(3-b)
它要求分类器在分类准确的同时拉开score_yi与score_i的差距。
-
exp-loss
熟悉Adaboost的读者对于exp-loss应该不会陌生,Adaboost算法最终产生的打分函数为:
![]()
其中, ![]() ,
, ![]()
![]() 表示第m个弱分类器,
表示第m个弱分类器,![]() 表示在第m轮的学习中,样本
表示在第m轮的学习中,样本![]() 的权重。相应的二分类器为:
的权重。相应的二分类器为:
![]()
指数损失函数为:
![]() (4)
(4)
显然有:
![]()
即指数损失函数不小于0-1 loss,一般而言,Adaboost的训练误差是以指数速率下降的。
KL散度与交叉熵
-
KL散度
假设随机变量x服从分布p(x),则该系统的信息熵定义为:
![]()
它度量了机器在编码x时需要付出的代价(注意,该代价是机器编码x时所需要付出的最小代价,前提是我们已知p(x))。通常情况下,我们一般不知道p(x),因此采用一个代理分布/逼近分布q(x)来描述随机变量x,需要付出的额外代价称为相对熵(relative entropy )或者KL-散度(Kullback-Leibler divergence):
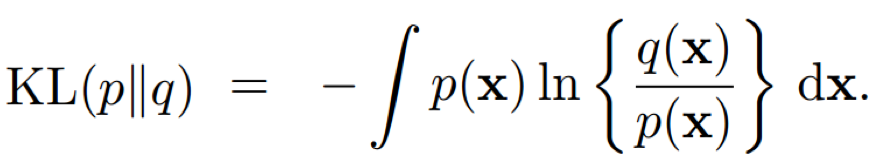
不难验证KL-散度具有如下的性质:
![]()
其中,当且仅当p(x) == q(x)时,KL(p||q) = 0。将KL-散度展开可得:
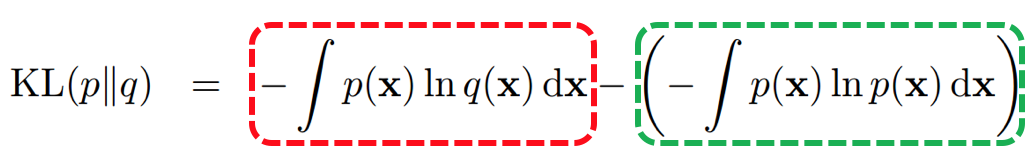
称等式右侧的第一项为交叉熵(cross-entropy),它表示当我们以分布q(x)来刻画x时,编码x所需要付出的代价;第二项则为x的固有信息熵。由KL-散度的定义可知,如果q(x)与p(x)越趋于一致,KL(p||q)越小,也就意味着在编码x的不确定性时我们需要付出的代价越小。
一般在机器学习中,当数据集给定时,KL-散度中的第二项就已经确定下来了(尽管我们不知道它是多少),因此我们能做的事情就是最小化第一项,即通过建模,优化,选择一个能能够较好地逼近数据标签分布p(y|x)的q(y|x)。