前言:
这篇博客主要是总结在高并发场景下应该什么时候使用缓存,怎样使用缓存。同时介绍了目前主要的三个缓存工具。
为什么需要使用缓存?
下面我们来看看浏览器请求的大致流程:
上面就是我们浏览器访问服务器的大致流程,随着用户量增多,服务器的压力和数据库的压力也会随之来临。要想使系统拥有高吞吐量我们可以在任意环节加入缓存,使得请求能够直接从缓存中获取,从而减少服务器的计算量,从而提升响应速度。其实缓存可以出现在上面4个环节的任意环节,但是作为后台开发的人员来说我们更加关心的是服务器方面和数据库方面的缓存。
缓存的特征
命中率=命中数/(命中数+没有命中数):在这里命中数就可以理解为用户请求的资源在缓存中,而没有命中就是指用户无法直接从缓存中获取资源,需要查询数据库或者由服务器计算分发资源
最大元素:也就是缓存中能存放的最大数据,可以理解为缓存的容量,当缓存中的数据超出了最大元素,那么就会触发缓存清空策略。合理设置最大元素值可以有效的帮我们提高命中率。
清空策略(部分):
FIFO:先进先出策略,最先进入缓存的数据在缓存空间不足的情况下最先清除,是主要比较资源创建的时间,在数据要求实时性的情况下,可以使用该策略,优先保障最新数据可用
LFU:最少使用策略,无论创建时间什么时候,当缓存空间不足时,清除使用次数较少的缓存,保留使用次数较多的缓存,这类策略有效的保证高命中率
LRU:最近最少使用策略,根据元素最后一次使用的时间进行排序,清除最近没有使用过的资源。在热点场景下适用,优先保证热点数据的有效性
缓存命中率影响因素
缓存适合读多写少的业务场景,如果是在写多读少的场景使用缓存的意义就不大,并且可以根据清空策略来保证缓存的命中率。实时性要求越低的场景就越适合缓存
缓存的粒度越小,命中率就越高
缓存容量和基础设施,目前的缓存工具和中间件大多采用LRU算法,并且采用分布式架构能更好的扩展缓存。
缓存应该聚焦于高频访问且时效性低的热点数据上
缓存的分类和应用场景
1、本地缓存:编程实现、Guava Cache
2、分布式缓存:Memcache、Redis
Guava Cache:架构设计灵感来源于J.U.C包中的ConcurrentHashMap。在Guava Cache中使用多个segment细粒度锁在保证线程安全的同时能够保证高并发场景的需求,Cache实际上是存取键值对的集合,与ConcurrentHashMap不同的是Cache需要处理缓存过期,动态加载等算法的问题,下面是Cache内部示意图:
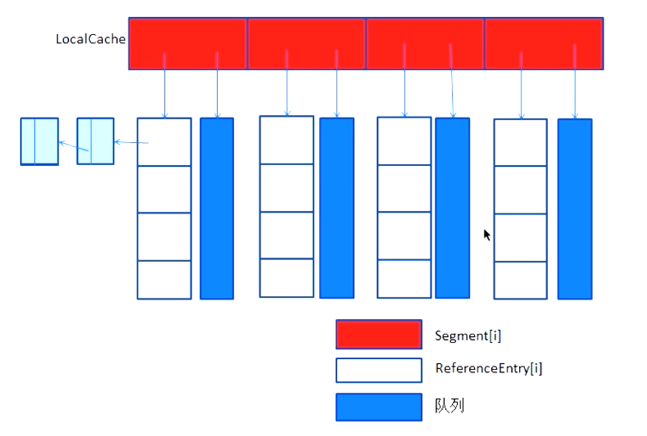
主要实现的功能有:自动将节点加载进缓存结构中,当缓存的数据超过最大值时,就通过LRU算法来移除,还可以计算出缓存的命中率,未命中数等统计数据
MemCache:应用较为广泛的开源分布式缓存之一,MemCache分布式是在客户端实现的,通过客户端的路由来处理。具体原理是:在客户端设置了key和value,并采用一致性的哈希算法作为的路由策略,MemCache除了计算key的哈希值还会计算服务器的哈希值,然后将这两个哈希值映射到有限的值域上,通过寻找服务器哈希值大于且最接近key的哈希值的服务器作为这个客户端的缓存,即通过将key映射到不同的服务器上实现分布式。
Redis:远程的非关系型数据库,性能强劲,具有复制特性等,可以存储键值对,与五种不同类型(String,hash,list,set,sorted set)值之间的映射,还可以将存储在内存的数据持久化到硬盘,使用复制特性扩展读性能,使用分片扩展写性能。支持主从数据备份。Redis底层是通过C语言编写,最高每秒可读11万次,可写8万1千次。Redis的所有操作都具有原子性,也支持对几个操作合并后的原子性执行
高并发下缓存常见问题
缓存一致性:当数据时效要求很高,就必须保证数据库中的数据和缓存中的数据一致,而且要保证缓存中的节点和副本中的节点要保持一致。这就比较依赖于缓存的过期的更新策略,一般在数据发生更改的时候主动更新缓存中的数据。也就是会出现以下4种情况:
更新数据库成功 ----> 更新缓存失败 ---->数据不一致
更新缓存成功 ----> 更新数据库失败 ---->数据不一致
更新数据库成功 ----> 删除缓存失败 ---->数据不一致
删除缓存成功 ----> 更新数据库失败 ---->数据不一致
缓存并发:当缓存过期后会尝试从数据库中获取数据。在高并发的时候可能会存在多个缓存请求获取数据库,这会对后端数据库造成极大的冲击。这时候在缓存更新或者淘汰的时候就需要加锁,然后当数据库更新完或者从数据库获取到数据时候之后再释放锁。
缓存穿透:在高并发时,如果某个key被高并发的访问,但是没有被命中,这时候请求就有可能通过缓存直接达到数据库,数据库中也不存在该数据,使得数据库执行了很多不必要的查询操作。并且会对数据库造成特别大的冲击。解决方案:接口层增加校验与缓存空对象
缓存的雪崩:缓存中数据大批量到过期时间,且查询数据量巨大,使得请求直接来到数据库,让数据库压力过大。与缓存穿透不同的是:缓存穿透是大量请求查一条数据,而缓存雪崩是多条数据。解决方案:设置过期时间为随机,防止同一时间数据大量过期,若缓存是分布式部署,应将热点数据均匀分布在不同的缓存数据库中