项目实施依赖:
python,scrapy ,fiddler
scrapy安装依赖的包:
可以到https://www.lfd.uci.edu/~gohlke/pythonlibs/ 下载 pywin32,lxml,Twisted,scrapy然后pip安装
项目实施开始:
1、创建scrapy项目:cmd中cd到需创建的文件目录下
scrapy startproject guazi
2、创建爬虫:cd到创建好的项目下
scrapy genspider gz guazi.com
3、分析目标网址:
第一次我直接用的谷歌浏览器的抓包分析,取得UA和Cookies请求,返回的html数据完全缺失,分析可能是携带的Cookies
有问题,然后就用fiddler抓包才,得到Cookies与谷歌上得到Cookies多了UA,时间等参数,
4、将UA,Cookies添加到下载中间中去:
1 class Guzi1DownloaderMiddleware(object):
2 def process_request(self, request, spider):
3 # 需要对得到的cookies处理成字典类型
4 request.cookies={}
5 request.headers["User-Agent"]=""
5、在settings中将DOWNLOADER_MIDDLEWARES打开
6、在spiders目录下找到gz.py开始编写爬虫逻辑处理
import scrapy
import time
'''
想要学习Python?Python学习交流群:1004391443满足你的需求,资料都已经上传群文件,可以自行下载!
'''
class GzSpider(scrapy.Spider):
name = 'gz'
allowed_domains = ['guazi.com']
start_urls = ['https://www.guazi.com/cd/buy/0']
def parse(self, response):
# 得到页面上所有车辆的url
url_list = response.xpath('//ul[@class="carlist clearfix js-top"]//li/a/@href').extract()
url_list = [response.urljoin(url) for url in url_list]
url_list = [url.replace("cq", "cd") for url in url_list]
for url in url_list:
yield scrapy.Request(url=url, callback=self.parse1, dont_filter=True)
# 获取下一页的url
next_url = response.urljoin(response.xpath('//span[text()="下一页"]/../@href').extract_first())
if next_url:
yield scrapy.Request(url=next_url, callback=self.parse, dont_filter=True)
time.sleep(2)
def parse1(self, response):
# 判断是否有数据
if response.xpath('//h2/text()').extract_first():
print(response.xpath('//h2/text()').extract_first().strip())
item = {}
item["车型"] = response.xpath('//h2/text()').extract_first().strip()
item["选车类型"] = response.xpath('//h2/span/text()').extract_first()
item["价格/万"] = response.xpath('//div[@class="pricebox js-disprice"]/span[1]/text()').extract_first().strip()
item["新车价格"] = response.xpath('//div[@class="pricebox js-disprice"]/span[2]/text()').extract_first().strip()
item["上牌时间"] = response.xpath('//ul[@class="basic-eleven clearfix"]/li[1]/div/text()').extract_first().strip()
item["公里数"] = response.xpath('//ul[@class="basic-eleven clearfix"]/li[2]/div/text()').extract_first().strip()
item["排量"] = response.xpath('//ul[@class="basic-eleven clearfix"]/li[3]/div/text()').extract_first().strip()
item["变速箱"] = response.xpath('//ul[@class="basic-eleven clearfix"]/li[4]/div/text()').extract_first().strip()
item["配置信息"] = response.xpath('//span[@class="type-gray"]//text()').extract()
item["网址"] = response.url
yield item7、启动爬虫并保存为csv文件
scrapy crawl gz -o guanzi.csv
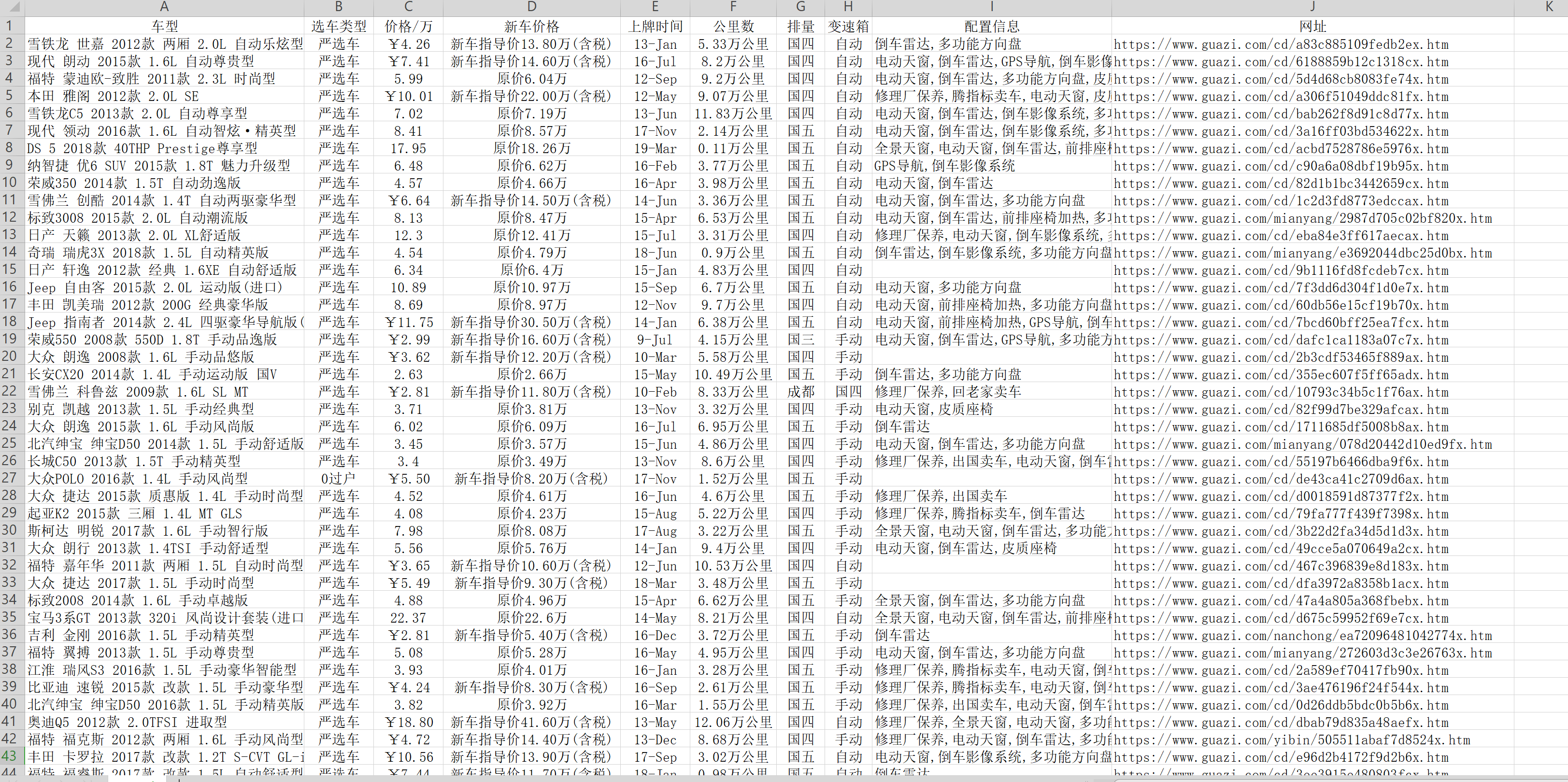
8、最后得到了想要的二手车信息,贴上部分截图