来源商业新知,原标题:行业前沿:谷歌新型PlaNet强化学习网络牛在哪里
现如今,迁移学习在机器学习领域中十分流行。
迁移学习是谷歌、Salesforce、IBM和微软Azure提供的多种自动机器学习管理服务的基础。由谷歌提出的BERT模型以及由Sebastian Ruder和Jeremy Howard共同提出的ULMFIT(通用语言模型微调文本分类)模型都重点突出了迁移学习,可见迁移学习是目前NLP(自然语言处理)的研究重点。
正如Sebastian在博文《NLP的ImageNet时代已经到来》中写道的那样:
这些作品表明预训练语言模型可应用于各种NLP任务并能取得最佳效果,因而登上了报纸的头条。这些方法预示着一个重大转折:它们对NLP的影响可能就像预训练的ImageNet模型对计算机视觉的影响一样大。
当下的主要问题是: 迁移学习能否应用于强化学习中?
与其他机器学习方法相比,深度强化学习需要大量数据,学习过程中可能存在不稳定性,而且在性能方面较为落后。强化学习主要应用于游戏或机器人领域是有原因的——这些领域能产生大量模拟数据。
与此同时,许多人认为强化学习仍然是实现通用人工智能(AGI)最可行的方法。然而,强化学习一直难以推广到多个场景中的很多任务上,而欠缺的这一点恰恰是智能的重要属性。
毕竟,学习不是件容易的事。最重要的是,它们必须将过去的经验应用于新的情况。

PlaNet背后的故事
在这个项目中,PlaNet代理的任务是“规划”一系列动作,以实现保持杆平衡、教虚拟实体(人或猎豹)走路或通过在某一特定位置击打来保持盒子旋转等目标。

对于深度规划网络(PlaNet)代理必须执行的六个任务的概述。
介绍PlaNet的Google AI博文原文提到了六项任务(以及与任务相关的挑战):
· 保持推车杆平衡:从平衡位置开始,代理必须快速反应以使推车杆一直朝上。
· 向上摇晃推车杆:摄像头被固定在某处,推车可能会离开视线。因此,代理必须掌握并记住多个帧的信息。
· 旋转手指:需要预测两个独立的对象及其互动。
· 猎豹奔跑:包括与地面的接触,这种情况难以预测准确,还需要建立可预测多种未来可能出现情况的模型。
· 接住杯子:只有球被抓住时才会提供零散的奖励信号。要规划出精确的行动序列需要准确预测未来情况。
· 让机器人走路:模拟机器人一开始躺在地上,必须先学会站起来然后再走路。
这些任务一致要求PlaNet在执行中做到以下几点:
1. 代理需要预测各种未来可能性(为了制定出可靠计划)
2. 代理需要根据最近操作的结果/奖励更新计划
3. 代理需要保留许多时间步骤的信息
那么Google AI团队是如何实现这些要求的呢?
PlaNetAI VS 其它方法
PlaNetAI与传统强化学习的不同之处体现在以下三点:
1.使用潜在动力学模型学习——PlaNet从一系列隐藏或潜在状态而不是图像中学习,以预测潜在状态发展情况。
2.基于模型制定计划——PlaNet在没有策略网络的情况下工作,基于持续的计划做出决策。
3.迁移学习——Google AI团队培养了一个单独的PlaNet代理来处理全部六个不同任务。
让我们逐一深入研究这三个特性,来看看它们如何影响模型性能。
潜在动力学模型
作者主要打算使用紧凑的潜在状态或来自环境的原始感官输入。这两者之间有个权衡利弊的问题。使用紧凑的潜在空间意味着额外提升了难度,因为代理人现在除了必须学会赢得游戏,还必须理解游戏中的视觉概念——这种图像编码和解码需要进行大量计算。
使用紧凑潜状态空间的好处是在代理中学到更多抽象表述,如对象的位置和速度,而且不必生成图像。这意味着实际规划起来会快很多,因为代理只需要预测未来获得的奖励而不用预测图像或场景。
潜在动力学模型现在更常用,因为研究人员认为"训练潜在动力学模型的同时结合提供的奖励,将会生成对与奖励信号相关的变异因素敏感的潜在嵌入,和对培训期间采用的模拟环境中含有的外来因素不敏感的潜在嵌入"。
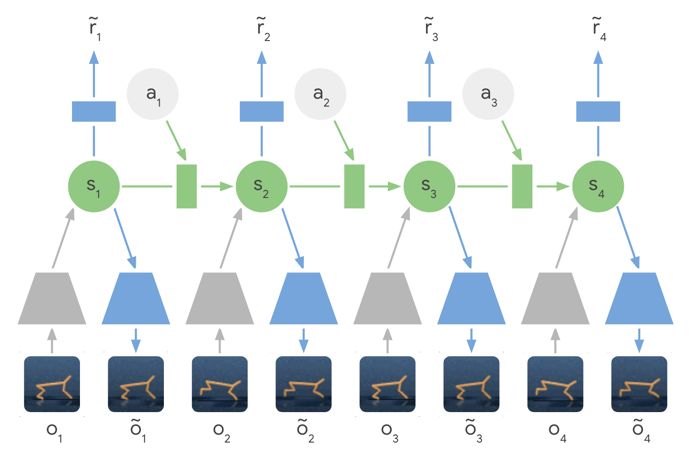
训练形成的潜在动力学模型——编码器网络(灰色梯形)不直接使用输入图像,而是将图像信息压缩为隐藏状态(绿色圆圈),然后用这些隐藏状态来预测未来图像(蓝色梯形)和奖励(蓝色矩形)。
这篇名为 《论使用深度自动编码器进行高效嵌入式强化学习》的优秀论文指出:
在自主嵌入式系统中,减少现实中采取的行动量和学习一项策略所需的能量通常至关重要。在高维图像表述中训练强化学习代理既耗资又耗时。自动编码器是用于将像素化图像等高维数据压缩成小的潜在表述的深度神经网络。
基于模型的计划与无模型

Jonathan Hui的精彩图表显示了强化学习方法的范围,基于模型的强化学习试图让代理了解现实世界的运转方式。这种强化学习并不是直接将观察映射到行动,而是让代理提前制定明确计划,通过“想象”它们的长期结果来更仔细地选择行动。采用基于模型的方法好处在于样本效率会更高——也就是说它不会从头开始学习每个新任务。
想了解无模型和基于模型的强化学习之间有何差异,可以看我们进行优化的目的,究竟是为了获得最大收益还是为了投入最低成本(无模型=最大奖励,而基于模型=最低成本)。
无模型强化学习技术如使用政策梯度算是一种强力解决方案,其中正确行为最终将会被发现并内化到策略中。实际上,政策梯度必须经历积极回报,而且还要经常经历,才能最终能缓慢地将政策参数转向能够给予高回报的重复性动作。
任务类型是怎样影响选择的方法的,这一点很有趣。安德雷在名为“Deep Reinforcement Learning:Pong fromPixels”的精彩一文中提到在一些游戏或任务中 政策梯度可以战胜人:
在很多游戏里,政策梯度都可以轻易战胜人类。特别是与需要精确操作,快速反应和做出相对短期规划的频繁奖励信号有关的游戏都可以得到理想结果,因为奖励和行动之间的这些短期相关性可以通过该方法轻松“引起注意”,并且执行时政策会进行精心完善。你可以在Pong代理中看到已经发生过的这种情况的提示:它开发了一种策略,它等待球出现,然后迅速冲过去以便在边缘捕获它,以很高的垂直速度快速启动它。代理通过重复此策略得分。在许多ATARI游戏中例如弹球、突围等,Deep Q Learning就是以这种方式战胜了人为基本操作。
迁移学习
在第一场比赛之后,PlaNet代理已经对重力和动力学有了基本的了解,并且能够在下一场比赛中利用这些知识。因此,PlaNet的效率通常比需要从头开始学的方法高50倍。这意味着代理只需查看动画的五个帧(实际上就是1/5秒的镜头)就能精确预测出后面的序列。实施起来也很便捷,这意味着团队无需分别培训六个模型就能有效完成任务。
引自论文:
PlaNet解决了各种基于图像的控制任务,在最终性能方面可与高端的无模型代理相媲美,而且平均数据效率提高了5000%......这些习得的动态可独立于任何特定的任务,因此有可能完美地迁移到环境里的其他任务中去。
下图中,与D4PG相比,PlaNet仅凭2000段就显示出的数据效率增益令人惊讶:
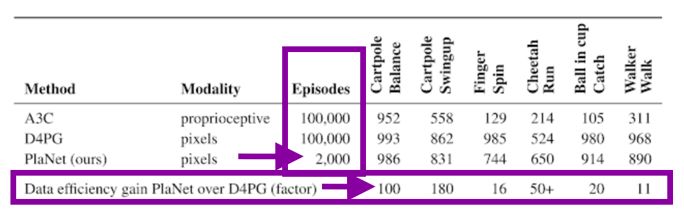
从论文中可以看出:PlaNet在所有任务上明显优于A3C,并且接近D4PG的最终性能,同时与环境的平均交互量要少5000%。
还有这些测试表现与收集的剧集数量(蓝色的是PlaNet)的对比:
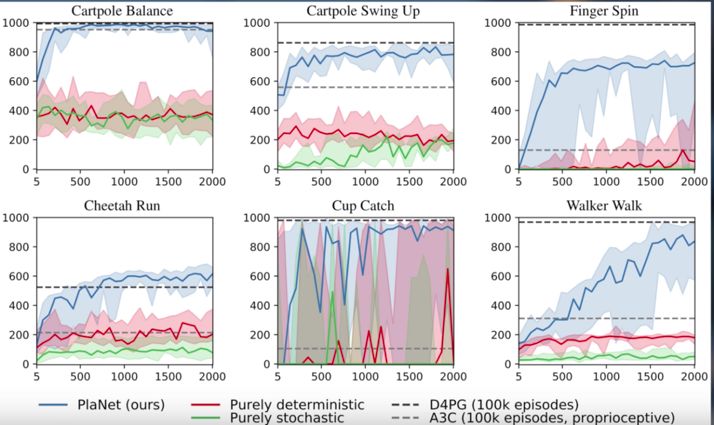
摘自介绍PlaNet的论文,文中将PlaNet与无模型算法进行了比较。
这些激动人心的结果昭示着一个数据高效和可推广强化学习新时代的到来。请密切关注这一领域!