题目要求:1T大小的文件,按行存储,文件所有行中,只有两行是重复的,选出重复的行;提高的设备为一台计算机,内存可以选择128M,64M或256G
输入:1T文件
输出:重复的行
第一种方案:
思路:
分堆,缩小范围查找
加载一部分到内存中,按行读取,每一行取对应的hashcode,根据 (行hashcode)%2000 的值,,存放在对应的位置(0-1999),重复的行肯定在同一个值中,遍历这2000个数组,找到重复的行。
共有两次读取I/O操作
第二种方案:
如果文件中存放的是乱序的数字,每一行一个数字,将所有的数字进行排序
思路:
按数值范围分组,组内快速排序,再追加
划分多个区间小文件,加载一部分到内存中,读取每一行,遍历文件,将读取的数字存放在对应的区间文件中,这些区间小文件是小文件区间有序,区间内无序,将这些文件一次读入内存,先快速排序,再追加到上一个文件末尾,这样,完成了全排序
共有两次I/O操作,比较次数繁琐
第三种方案:
如果文件中存放的是乱序的数字,每一行一个数字,将所有的数字进行排序
思路:按文件大小划分成多个块,在块内快速排序,然后归并实现全排序
先选取50M文件,加载到内存中,读取文件,进行快速排序,然后再加载50M文件,同样进行快速排序,这样,多个文件块就形成了块内有序,块间无序,然后再对这多个文件块进行归并排序,从而实现全排序
以上三种方案的简单示意图,如图所示:
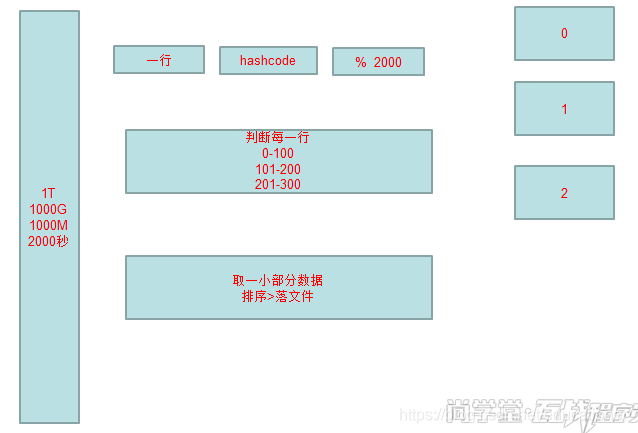
单机处理1T文件的计算方案
猜你喜欢
转载自blog.csdn.net/educationer/article/details/89682518
今日推荐
周排行