1.gcc/g++降级
Ubuntu18.04自带的gcc/g++是7.0版本的,但cuda不支持这么高版本,我们需要安装4.8版本。
1.下载安装4.8版本的gcc/g++
sudo apt-get install gcc-4.8
sudo apt-get install g++-4.82.让gcc软连接至4.8版本的gcc,g++软连接至4.5版本的g++
装完后进入到/usr/bin目录下
sudo mv gcc gcc.bak #备份
sudo ln -s gcc-4.8 gcc #重新链接对g++也进行同样的操作
3.再查看gcc和g++版本号
gcc -v g++ -v均显示gcc version 4.8 ,说明gcc 48.8安装成功。
2.安装GPU(针对ubuntu18.04)
安装所有推荐的驱动:
sudo ubuntu-drivers autoinstall3.cuda安装
1.下载cuda安装包,我们安装9.0版本,地址:CUDA
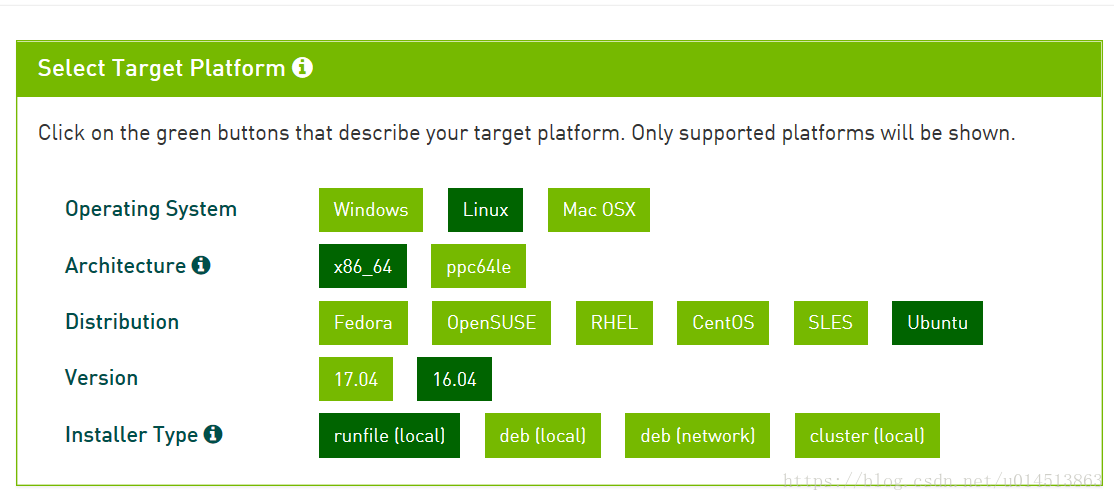
将上面的选项框填好后,会弹出下面的选项框
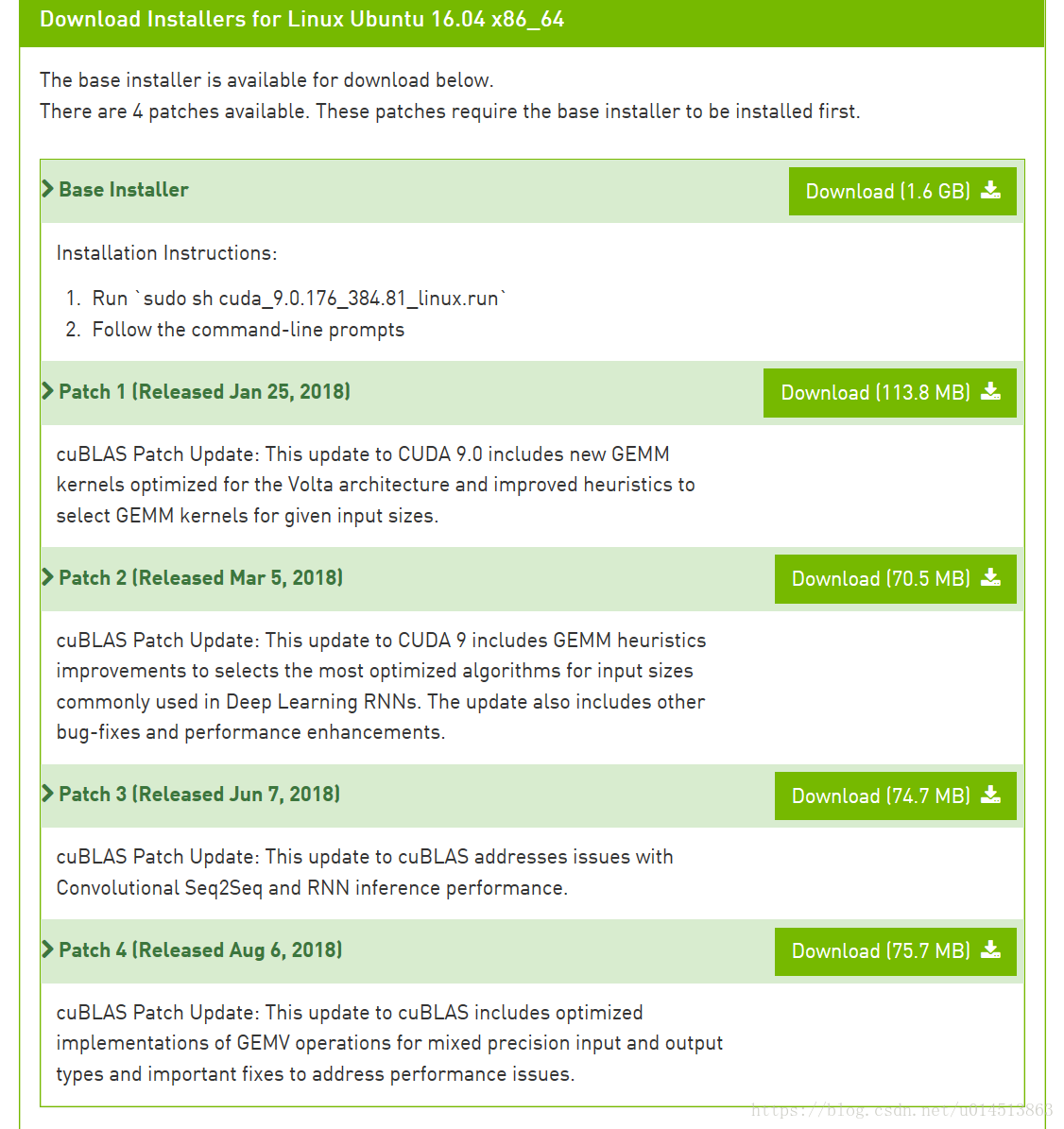
下载CUDA9.0和全部四个补丁(这几个补丁不安装的话,cuda在使用过程中可能出现各种bug),他们会被保存到该用户目录下的 Downloads 文件夹下。
2.安装cuda
进入Downloads/后,输入:
sh cuda_9.0.176_384.81_linux.run
sh cuda_9.0.176.1_linux.run
sh cuda_9.0.176.2_linux.run
sh cuda_9.0.176.3_linux.run
sh cuda_9.0.176.4_linux.run 安装这五个文件
注意:执行,如果有安装了显卡驱动的,注意在提问是否安装显卡驱动时选择no(因为在前边已经装过了),其他 选择默认路径或者yes即可。
注:我们也可以不在usr/local下安装cuda,而在用户根目录下安装:







然后就可以了
3.添加访问cuda的路径
安装完毕之后,将以下两条加入.barshrc文件中.
sudo vim ~/.barshrc
export PATH=/usr/local/cuda-9.0/bin${PATH:+:$PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda-9.0/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}下边的这两条和上边的等价(暂时没搞清楚为什么):
sudo vim ~/.barshrc
export PATH=/usr/local/cuda-9.0/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-9.0/lib64:$LD_LIBRARY_PATH4.CUDNN安装
CUDNN需要注册,我们安装7.1.3版本
注册完以后,出现下面的界面:
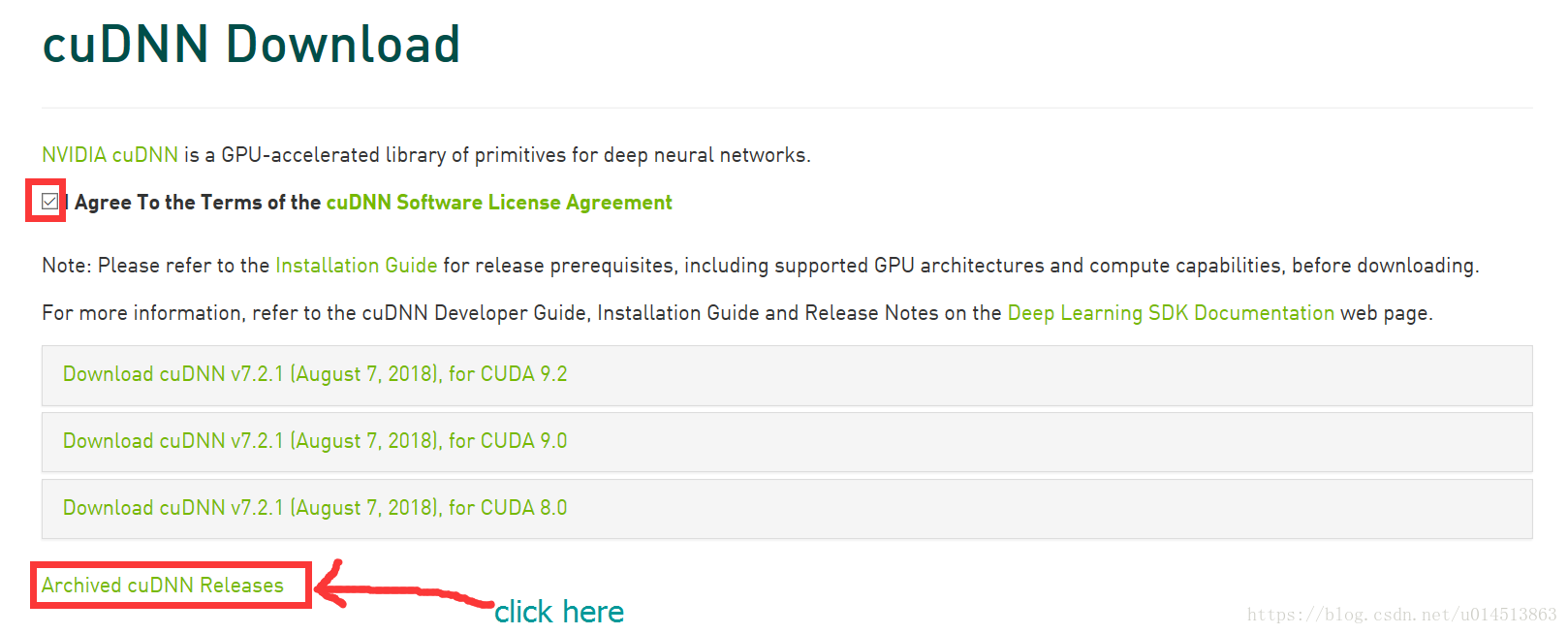
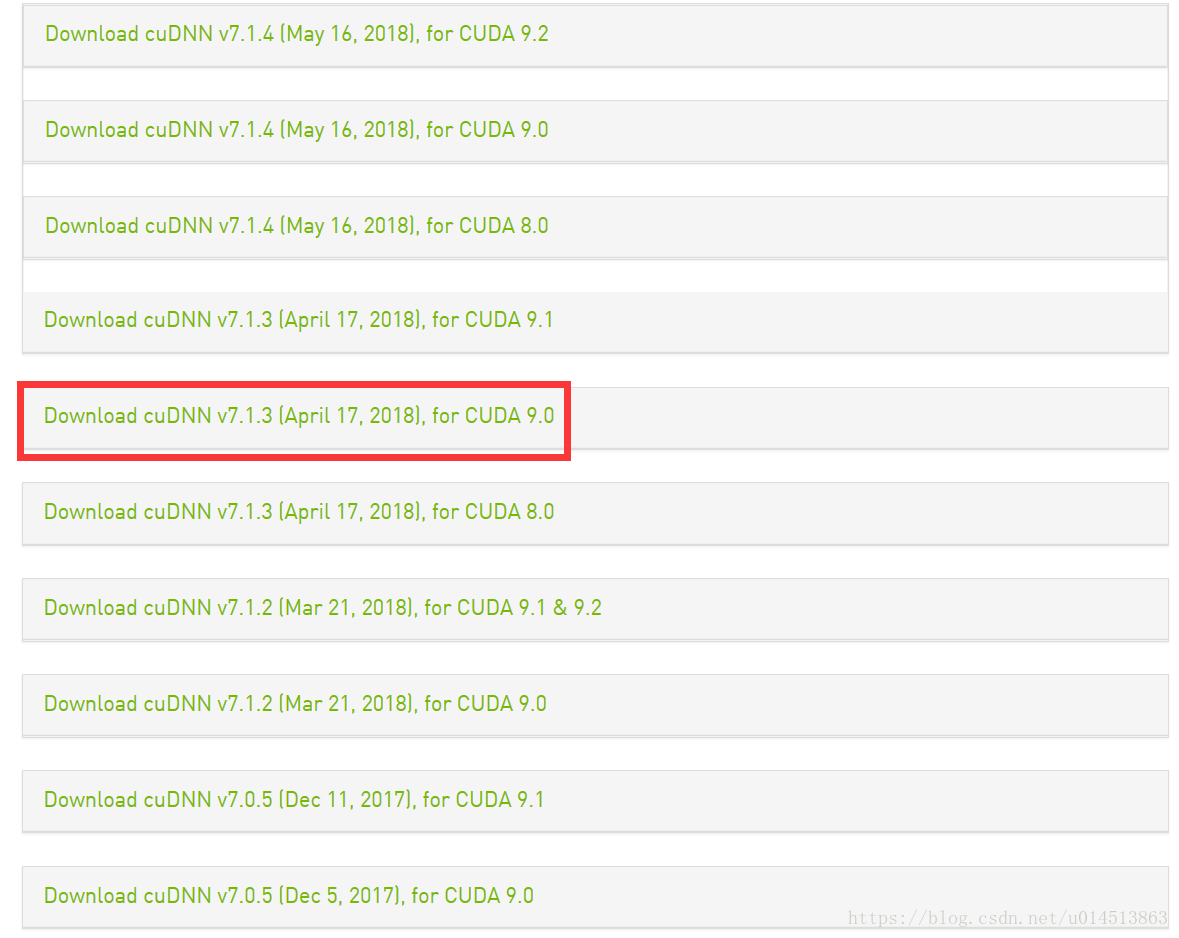
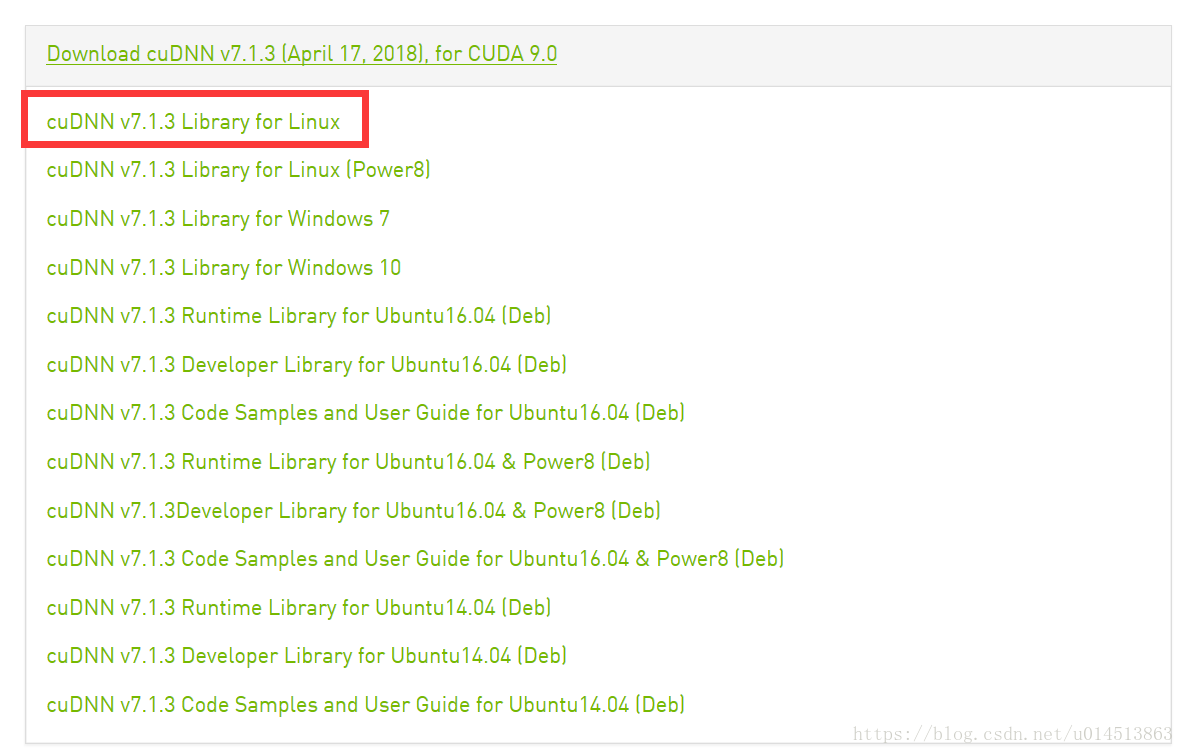
下载结束后,将压缩包进行解压缩。
然后,在Downloads/文件夹内输入如下命令,将CUDNN拷贝至CUDA的目录中(注,CUDNN无需安装):
sudo cp cuda/include/cudnn.h /usr/local/cuda/include
sudo cp cuda/lib64/libcudnn* /usr/local/cuda/lib64
sudo chmod a+r /usr/local/cuda/include/cudnn.h /usr/local/cuda/lib64/libcudnn*5.cuda测试(看cuda是否安装好)
进入samples文件夹,一般在home目录下
cd ~/NVIDIA_CUDA-9.1_Samples/
make编译完成后,进入:
cd ./bin/x86_64/linux/release 使用deviceQuery 或 bandwidthTest测试
$ ./deviceQuery
./deviceQuery Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "GeForce GTX 960M"
CUDA Driver Version / Runtime Version 9.1 / 9.1
CUDA Capability Major/Minor version number: 5.0
Total amount of global memory: 2004 MBytes (2101870592 bytes)
( 5) Multiprocessors, (128) CUDA Cores/MP: 640 CUDA Cores
GPU Max Clock rate: 1176 MHz (1.18 GHz)
Memory Clock rate: 2505 Mhz
Memory Bus Width: 128-bit
L2 Cache Size: 2097152 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(65536), 2D=(65536, 65536), 3D=(4096, 4096, 4096)
Maximum Layered 1D Texture Size, (num) layers 1D=(16384), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(16384, 16384), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 2048
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 1 copy engine(s)
Run time limit on kernels: Yes
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
Device supports Unified Addressing (UVA): Yes
Supports Cooperative Kernel Launch: No
Supports MultiDevice Co-op Kernel Launch: No
Device PCI Domain ID / Bus ID / location ID: 0 / 1 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 9.1, CUDA Runtime Version = 9.1, NumDevs = 1
Result = PASS$ ./bandwidthTest
[CUDA Bandwidth Test] - Starting...
Running on...
Device 0: GeForce GTX 960M
Quick Mode
Host to Device Bandwidth, 1 Device(s)
PINNED Memory Transfers
Transfer Size (Bytes) Bandwidth(MB/s)
33554432 12339.9
Device to Host Bandwidth, 1 Device(s)
PINNED Memory Transfers
Transfer Size (Bytes) Bandwidth(MB/s)
33554432 11720.0
Device to Device Bandwidth, 1 Device(s)
PINNED Memory Transfers
Transfer Size (Bytes) Bandwidth(MB/s)
33554432 65699.6
Result = PASS
NOTE: The CUDA Samples are not meant for performance measurements. Results may vary when GPU Boost is enabled.在usr/local/cuda-9.0中输入nvcc -V
会出现:
yhao@yhao-X550VB:~$ nvcc -V
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2016 NVIDIA Corporation
Built on Tue_Jan_10_13:22:03_CST_2017
Cuda compilation tools, release 9.0, V8.0.616.tensorflow-gpu安装
在anaconda官网上下载anaconda并安装好后,输入:
pip install tensorflow-gpu==1.5.0可以看到pip更新后,anaconda里边的库也会更新(如果是conda install 会出现问题,原因暂时没有搞清楚)
安装好后,可以在spyder-python中使用
import tensorflow as tf有可能tensorflow在anaconda上不好使,这时候可以安装一个pycharm来运行tensorflow
7.cuda/cudnn版本与tensorflow版本对应关系
cuda/cudnn需要安装对应版本的tensorflow,不然会出现各种bug:
cuda8/cudnn5 --> tensorflow1.2及以下
cuda8/cudnn6 --> tensorflow1.3以及1.4
cuda9/cudnn7 --> tensorflow1.5及以上