这章主要描述索引,即通过什么样的数据结构可以更加快速的查询到数据
Hash Tables
hash tables可以实现O(1)的查询,设计主要考虑两点

首先用什么hash function?底下列出常用的hash function

然后怎么解决collisions?即hash schemes
首先是static hash schemes
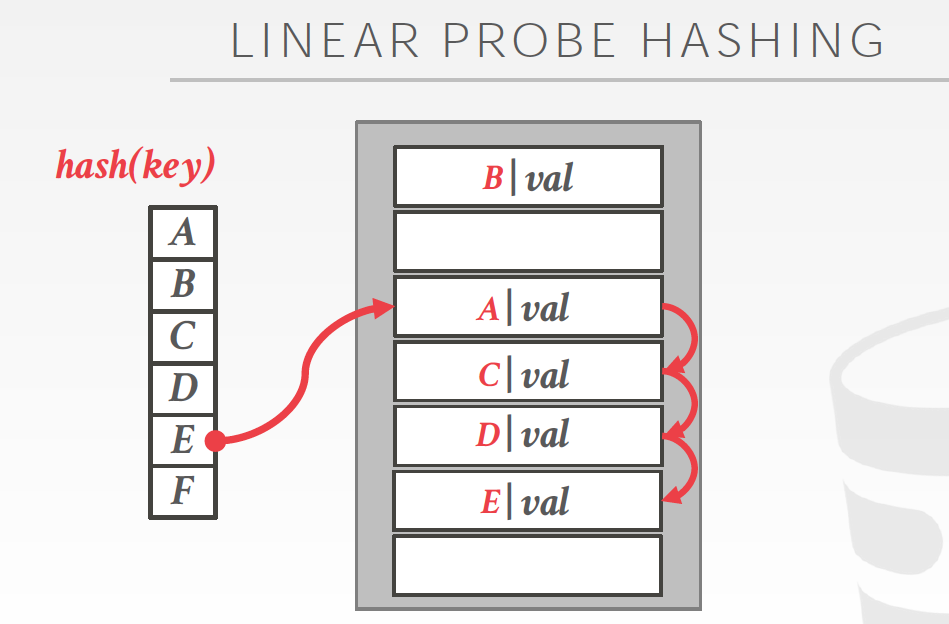
第一个方法是Linear probe hashing
方法,如果发现冲突,就往后找,直到找到一个free的slot,所以要同时记录下key和value,这样才好去比对每个key是不是要找的
问题如图,会出现bad case,比如对于E,需要跳很多步才能找到,这样查询就从O(1)变成O(n)了
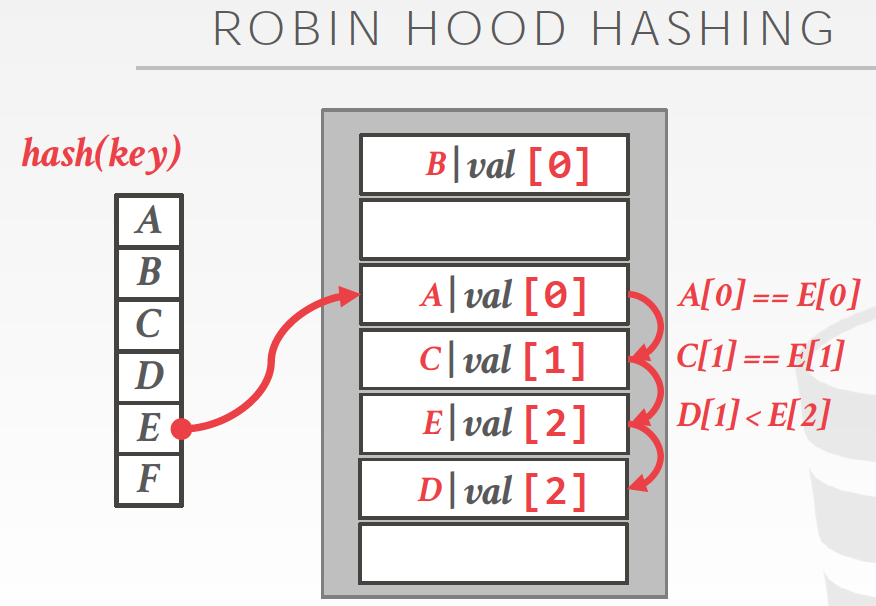
Robin Hood Hashing
像名字一样,罗宾汉,劫富济贫,解决badcase
首先存储到时候,要加上跳数,jump几次;然后根据jump数比较,来判断是否要做平均
左图,如果不用robin hood方式,D为1跳,E为3跳
右图,用robin hood后,D和E都变成2跳

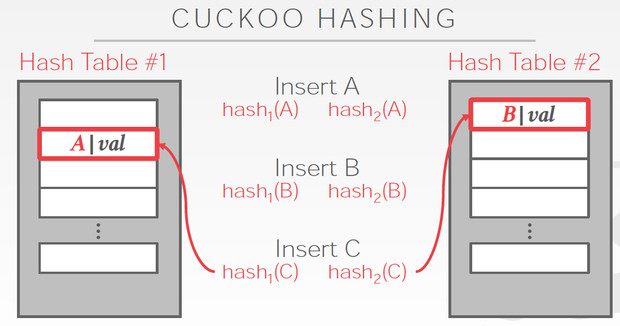
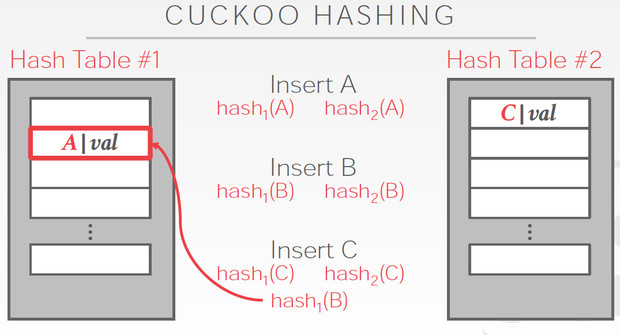
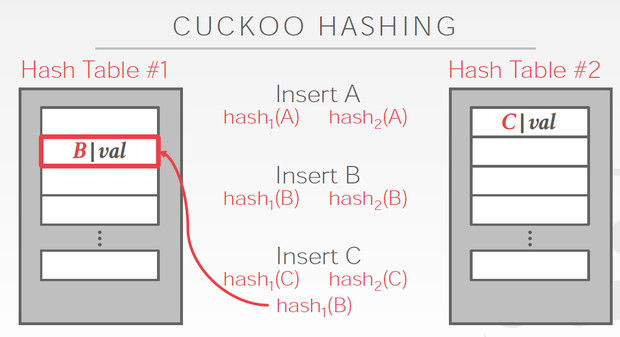
Cuckoo Hashing
简单的说,用多个hash table,对于一个数据,哪边空就存哪边
但是对于当前这个C,两边都冲突,他解决的思路是,
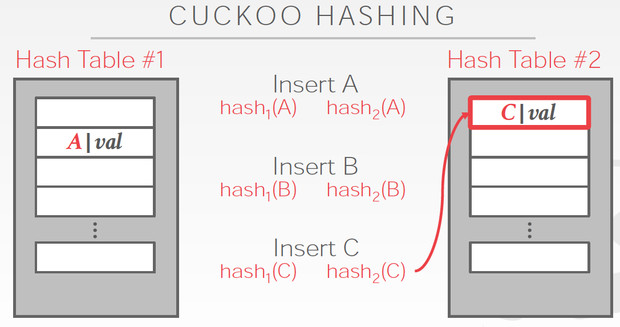
C两边都冲突那肯定是解不了,那我先把C随便存一边,这样如图,我们就要解决B的冲突
B只能去替换A,最终A可以存在另一张表里面,所以冲突解决
这个方法明显的好处是查询路径短,最多两次
问题是,插入性能容易比较差,如果冲突比较多,有可能死循环,所以如果出现这些情况,就要去降低冲突率,比如增加hash table的大小,或者增加hashtable的个数
但这样变化后,需要完全重新rebuild

static hash schemes的问题就是,容量有限,一旦超出扩容的话,就需要整个索引完全rebuild
所以就需要Dynamic hash table
最直白的想法是Chained Hashing,hash值对应的是buckets,不存在collision,因为buckets是可以无限扩展的
问题是,数据多了,就变成O(n)了
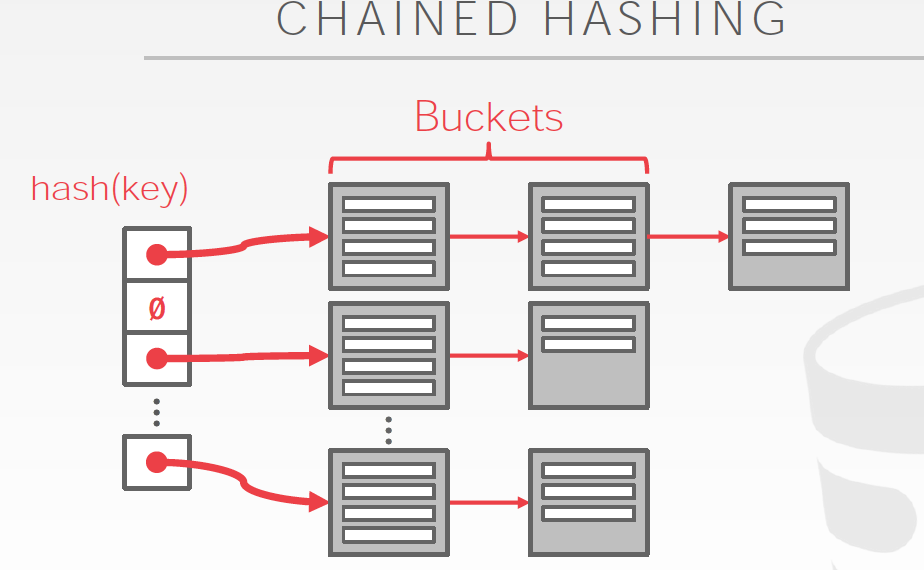
上面的方法的问题是,随着数据的增多不断的增加bucket,但是没有没有增加目录大小,最终对应到目录中一条的数据越来越多,失去了index的意义
Extendible hashing
这个方法难理解些,
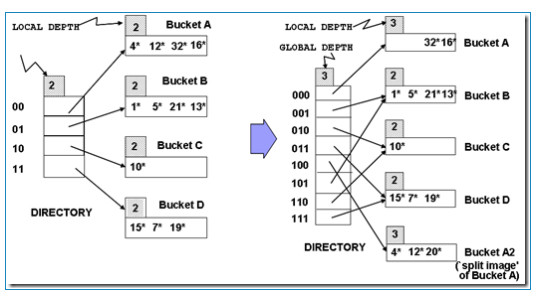
首先这里的hash函数是根据前几位去分bucket,depth的意思是几位
比如,用2位分bucket,目录大小为4,不够了就用3位去分bucket,目录大小就是8
Global depth是目录用几位,local depth其实只是个标识,表示这个bucket用的是几位,
因为只要有一个分区的bucket满了,并且如果这个分区只对应一个目录item,那么目录就需要扩展,global depth会增加
比如下图中,00指向bucketA,已经4个数满了,还要加一个,只有分离bucket,这个时候就需要扩展目录,global depth=3,其中000,001分别指向一个bucket
但是其他的bucket没满啊,所以他们的local depth还是2,并且在新的目录中,有两个item指向depth为2的bucket
但这时来个9,落在bucketB,B也满了,需要分裂,但是这个时候就不需要扩展目录,因为B本身就有两个目录item指向,正好可以分开
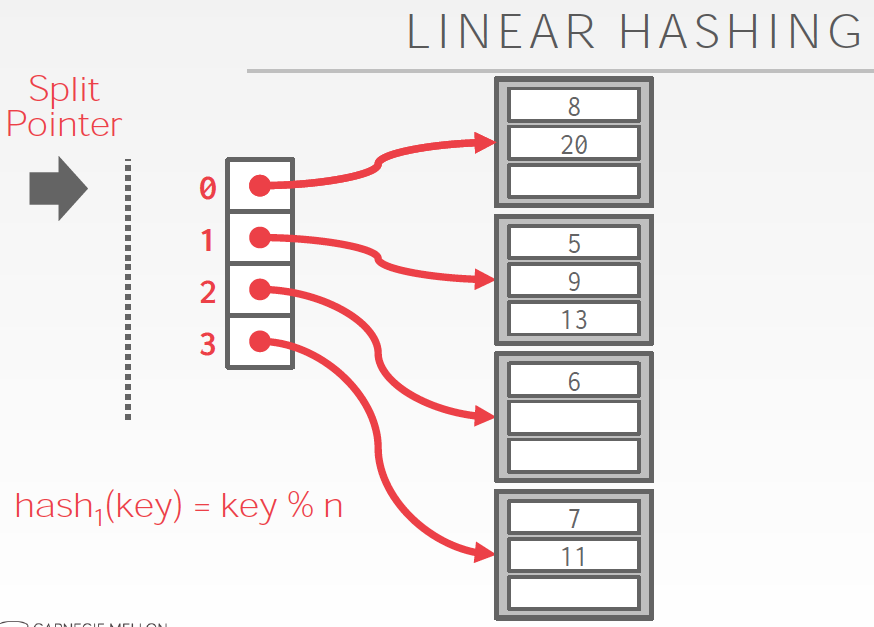
Linear Hashing
这个的思路也是逐步的分裂bucket,但他和extendible hashing相比,不需要维护这个目录
http://queper.in/drupal/blogs/dbsys/linear_hashing,这个链接里面的例子非常清楚
基本思想,
初始bucket数是4,按4取模分bucket,很容易理解
问题是,如果有某个bucket满了,怎么处理?
首先把overflow的数据用一个临时bucket存下来
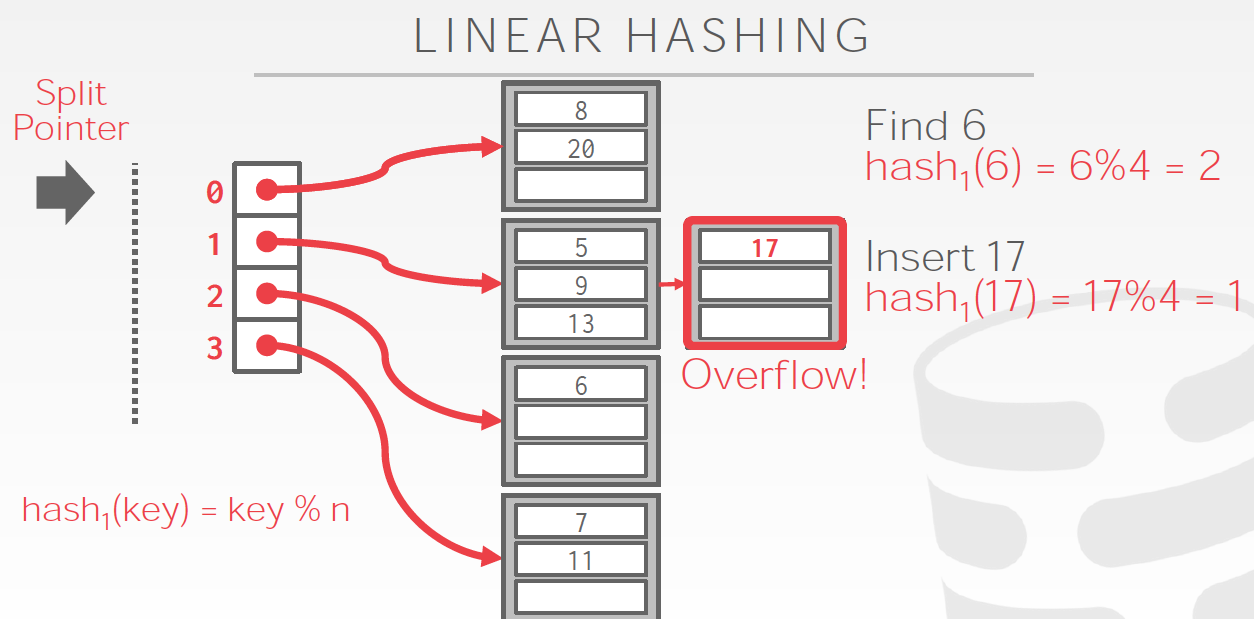
然后接着要做bucket分裂,
这里bucket分裂的过程比较trick是逐步完成的,最终达到的是bucket翻倍
因为要一个个bucket分裂,所以这里有个split point,表示当前分裂到哪个bucket了
这里很难理解的是,他不是分裂overflow的那个bucket,而且按顺序一个个分裂
如图,bucket 1 满了,但他是分裂当前split point指向的bucket 0,分成0和4,并且split point + 1
分裂的时候用的hash函数是下一轮的函数,如图的hash2
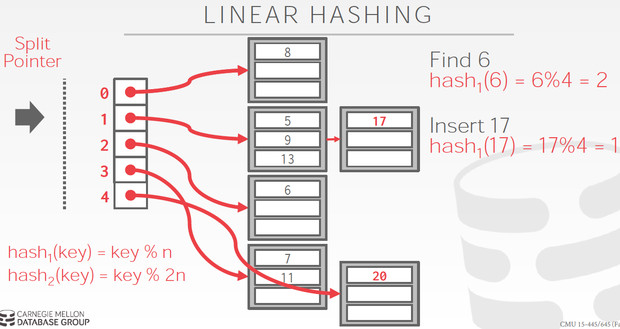
这里没overflow一次,就按顺序分裂一个bucket,当split point为4的时候,即分裂完一轮了,当前bucket=8
把split point重置成0,开始下一轮,每轮的bucket数翻倍,所以hash函数中的取余的数也要翻倍,很容易理解
这样就实现了动态扩展