一:什么是GPU
很久以前,大概2000年那时候,显卡还被叫做图形加速卡。一般叫做加速卡的都不是什么核心组件,和现在苹果使用的M7协处理器地位差不多。这种东西就是有了更好,没有也不是不行,只要有个基本的图形输出就可以接显示器了。在那之前,只有一些高端工作站和家用游戏机上才能见到这种单独的图形处理器。后来随着PC的普及,游戏的发展和Windows这样的市场霸主出现,简化了图形硬件厂商的工作量,图形处理器,或者说显卡才逐渐普及起来。
GPU有非常多的厂商都生产,和CPU一样,生产的厂商比较多,但大家熟悉的却只有3个,以至于大家以为GPU只有AMD、NVIDIA、Intel3个生产厂商。

二:GPU与CPU的区别
想要理解GPU与CPU的区别,需要先明白GPU被设计用来做什么。现代的GPU功能涵盖了图形显示的方方面面,我们只取一个最简单的方向作为例子。

大家可能都见过上面这张图,这是老版本Direct X带的一项测试,就是一个旋转的立方体。显示出一个这样的立方体要经过好多步骤,我们先考虑简单的,想象一下他是个线框,没有侧面的“X”图像。再简化一点,连线都没有,就是八个点(立方体有八个顶点的)。那么问题就简化成如何让这八个点转起来。首先,你在创造这个立方体的时候,肯定有八个顶点的坐标,坐标都是用向量表示的,因而至少也是个三维向量。然后“旋转”这个变换,在线性代数里面是用一个矩阵来表示的。向量旋转,是用向量乘以这个矩阵。把这八个点转一下,就是进行八次向量与矩阵的乘法而已。这种计算并不复杂,拆开来看无非就是几次乘积加一起,就是计算量比较大。八个点就要算八次,2000个点就要算2000次。这就是GPU工作的一部分,顶点变换,这也是最简单的一部分。剩下还有一大堆比这更麻烦的就不说了。总而言之,CPU和GPU因为最初用来处理的任务就不同,所以设计上有不小的区别。它们分别针对了两种不同的应用场景。CPU需要很强的通用性来处理各种不同的数据类型,同时又要逻辑判断又会引入大量的分支跳转和中断的处理。这些都使得CPU的内部结构异常复杂。而GPU面对的则是类型高度统一的、相互无依赖的大规模数据和不需要被打断的纯净的计算环境。
于是CPU和GPU就呈现出非常不同的架构(示意图):
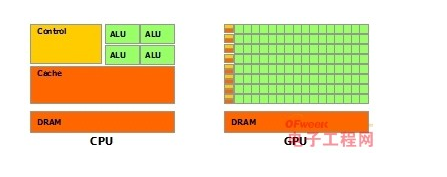
CPU与GPU区别大揭秘
图片来自nVidia CUDA文档。其中绿色的是计算单元,橙红色的是存储单元,橙黄色的是控制单元。
GPU采用了数量众多的计算单元和超长的流水线,但只有非常简单的控制逻辑并省去了Cache。而CPU不仅被Cache占据了大量空间,而且还有有复杂的控制逻辑和诸多优化电路,相比之下计算能力只是CPU很小的一部分。
而GPU的工作大部分就是这样,计算量大,但没什么技术含量,而且要重复很多很多次。就像你有个工作需要算几亿次一百以内加减乘除一样,最好的办法就是雇上几十个小学生一起算,一人算一部分,反正这些计算也没什么技术含量,纯粹体力活而已。而CPU就像老教授,积分微分都会算,就是工资高,一个老教授资顶二十个小学生,你要是富士康你雇哪个?GPU就是这样,用很多简单的计算单元去完成大量的计算任务,纯粹的人海战术。这种策略基于一个前提,就是小学生A和小学生B的工作没有什么依赖性,是互相独立的。很多涉及到大量计算的问题基本都有这种特性,比如你说的破解密码,挖矿和很多图形学的计算。这些计算可以分解为多个相同的简单小任务,每个任务就可以分给一个小学生去做。但还有一些任务涉及到“流”的问题。比如你去相亲,双方看着顺眼才能继续发展。总不能你这边还没见面呢,那边找人把证都给领了。这种比较复杂的问题都是CPU来做的。
而某些任务和GPU最初用来解决的问题比较相似,所以用GPU来算了。GPU的运算速度取决于雇了多少小学生,CPU的运算速度取决于请了多么厉害的教授。教授处理复杂任务的能力是碾压小学生的,但是对于没那么复杂的任务,还是顶不住人多。当然现在的GPU也能做一些稍微复杂的工作了,相当于升级成初中生高中生的水平。但还需要CPU来把数据喂到嘴边才能开始干活,究竟还是靠CPU来管的。
三:并行计算
首先我们说一下并行计算的概念,它是一种类型的计算,它的许多计算或执行过程是同时进行的。将大问题可以分成较小的问题,然后可以同时解决。可以同CPU或主机进行协同处理,拥有自己的内存,甚至可以同时开启1000个线程。
采用GPU进行计算时与CPU主要进行以下交互:
CPU与GPU之间的数据交换,在GPU上进行数据交换

先说明一下,一般来说同一时刻一个CPU或GPU计算核心上(就是我们通常所说的“核”)只能够进行一个运算,在超线程技术中,一个计算核心在同一时刻可能进行多个计算(比如对于双核四线程的CPU,在不发生资源冲突的情况下,每个计算核心可能同时进行两个计算),但超线程通常只是使逻辑计算核心翻倍。我们平时看到自己使用的CPU可以同时运行几十个程序,实际上,从微观角度来说,这几十个程序在一定程度上仍然是串行的,比如在四核四线程CPU上,同一时刻只能够进行4个运算,这几十个程序便只能在四个计算核心上轮换执行,只是由于切换速度很快,在宏观上表现出的就是这些程序在“同时”运行。
GPU最突出的特点就是:计算核心多。CPU的计算核心一般只有四个、八个,一般不超过两位数,而用于科学计算的GPU的计算核心可能上千个。正由于计算核心数量的巨大优势,GPU在同一时刻能够进行的计算的数量远远地把CPU比了下去。这时候,对于那些可以并行进行的计算,利用GPU的优势就能够极大地提高效率。这里解释一下任务的串行计算和并行计算。串行计算通俗来说就是先计算完一个之后再计算下一个,并行计算则是同时并行的计算若干个。比如计算实数a与向量B=[1 2 3 4]的乘积,串行计算就是先计算a*B[1],再计算a*B[2],然后计算a*B[3],最后计算a*B[4],从而得到a*B的结果,并行计算就是同时计算a*B[1]、a*B[2]、a*B[3]和a*B[4],得到a*B的结果。如果只有一个计算核心,四个计算任务是不可能并行执行的,只能够一个一个地串行计算,但如果有四个计算核心,则可以把四个独立的计算任务分到四个核上并行执行,这便是并行计算的优势所在。正因如此,GPU的计算核心多,能够进行并行计算的规模便非常大,对于一些能够通过并行计算解决的计算问题便表现出了优于CPU的性能。比如破译密码,将任务分解成可以独立执行的若干份,每一份分配在一个GPU核心上,便可以同时执行多份破译任务,从而加快破译速度。
但并行计算不是万能的,它需要一个前提:问题可以分解为能够并行执行的若干个部分。很多问题不满足这个条件,比如一个问题有两步,而第二步的计算依赖于第一步的结果,此时,这两部分便不能并行的执行,只能够串行地依次执行。实际上,我们平时的计算任务常常有复杂的依赖关系,很多重要的计算任务并不能够并行化。这是GPU的一个劣势。
关于GPU编程方面主要有以下方法:
