Work Queues
与其他Python教程一样,我们将使用Pika RabbitMQ客户机版本0.11.0。
本章的指南关注什么呢?
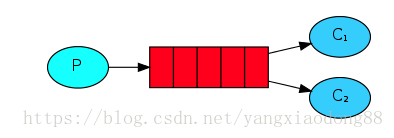
在第一个教程中,我们编写了从一个命名队列发送和接收消息的程序。在本例中,我们将创建一个工作队列,用于在多个工作者之间分配耗时的任务。
工作队列(又名:任务队列)背后的主要思想是避免立即执行占用大量资源的任务,并且必须等待它完成。相反,我们把任务安排在以后完成。我们将任务封装为消息并将其发送到队列。在后台运行的worker进程将弹出任务并最终执行作业。当您运行许多工作者时,任务将在他们之间共享。
这个概念在web应用程序中尤其有用,在web应用程序中,在短HTTP请求窗口中不可能处理复杂任务。
在本教程的前一部分中,我们发送了一条包含“Hello World!”的消息。现在我们将发送代表复杂任务的字符串。我们没有实际的任务,比如调整图片大小或者渲染pdf文件,所以让我们假装很忙——使用time.sleep()函数——来假装它。我们把弦中的点的数量作为复杂度;每个点将占“工作”的一秒钟。例如,Hello…需要三秒钟。
在本教程的前一部分中,我们发送了一条包含“Hello World!”的消息。现在我们将发送代表复杂任务的字符串。我们没有实际的任务,比如调整图片大小或者渲染pdf文件,所以让我们假装很忙——使用time.sleep()函数——来假装它。我们把弦中的点的数量作为复杂度;每个点将占“工作”的一秒钟。例如,Hello…需要三秒钟。
import sys
message = ' '.join(sys.argv[1:]) or "Hello World!"
channel.basic_publish(exchange='',
routing_key='hello',
body=message)
print(" [x] Sent %r" % message)
我们的老。py脚本还需要一些修改:它需要为消息体中的每个点伪造一秒钟的工作时间。它将从队列中弹出消息并执行任务,因此我们将其称为worker.py:
import time
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
time.sleep(body.count(b'.'))
print(" [x] Done")
循环调度
使用任务队列的优点之一是能够轻松地并行工作。如果我们正在积累积压的工作,我们可以增加更多的工人,这样就可以很容易地扩大规模。
首先,让我们试着运行两个worker。py脚本同时出现。它们都将从队列中获取消息,但具体如何呢?让我们来看看。
你需要打开三个控制台。两个将运行这个工人。py脚本。这些控制台将是我们的两个消费者——C1和C2。
# shell 1
python worker.py
# => [*] Waiting for messages. To exit press CTRL+C
# shell 2
python worker.py
# => [*] Waiting for messages. To exit press CTRL+C
默认情况下,RabbitMQ将依次向下一个使用者发送每条消息。平均而言,每个消费者都会收到相同数量的消息。这种消息分发的方式称为循环。在三个或更多的员工身上试试。
消息确认
完成一项任务可能需要几秒钟。您可能想知道,如果某个消费者开始了一项很长的任务,但只完成了部分任务,那么会发生什么情况呢?使用我们的当前代码,一旦RabbitMQ将消息传递给客户,它立即标记为删除。在这种情况下,如果您杀死一个工人,我们将失去消息,它只是处理。我们还会丢失所有发送给这个工人但尚未处理的消息。
但我们不想失去任何任务。如果一个工人死了,我们希望把任务交给另一个工人。
为了确保消息不会丢失,RabbitMQ支持消息确认。使用者返回ack(nowledgement),告诉RabbitMQ已经接收、处理了特定的消息,RabbitMQ可以随意删除它。
如果使用者在没有发送ack的情况下死亡(其通道关闭、连接关闭或TCP连接丢失),RabbitMQ将理解消息没有完全处理,并将重新排队。如果在同一时间有其他消费者在线,它会迅速将其重新发送给另一个消费者。这样你就可以确保没有信息丢失,即使工人偶尔会死去。
没有任何消息超时;当使用者死亡时,RabbitMQ将重新传递消息。即使处理一条消息需要非常非常长的时间,也没有问题。
手动消息确认在默认情况下是打开的。在前面的示例中,我们通过no_ack=True标志显式地关闭了它们。当我们完成一项任务时,是时候移除此标志并从工作人员发送适当的确认信息了。
def callback(ch, method, properties, body):
print " [x] Received %r" % (body,)
time.sleep( body.count('.') )
print " [x] Done"
ch.basic_ack(delivery_tag = method.delivery_tag)
channel.basic_consume(callback,
queue='hello')
使用这段代码,我们可以确保即使您在处理消息时使用CTRL+C杀死了一个工人,也不会丢失任何东西。在工人死后不久,所有未确认的信息将被重新发送。
确认必须通过相同的通道发送,这是为了在同一通道上接收。尝试承认使用不同的通道将导致通道级别的协议异常。要了解更多信息,请参阅《doc指南》。
被遗忘的确认
错过basic_ack是一个常见的错误。这是一个容易犯的错误,但后果是严重的。当您的客户端退出时,消息将被重新传递(这可能看起来像随机的重新传递),但是RabbitMQ将占用越来越多的内存,因为它不能释放任何未被添加的消息。
为了调试这种错误,可以使用rabbitmqctl打印messages_unrecognized字段:
sudo rabbitmqctl list_queues name messages_ready messages_unacknowledged
On Windows, drop the sudo:
rabbitmqctl.bat list_queues name messages_ready messages_unacknowledged
消息持久化存储
我们已经学会了如何确保即使用户死亡,任务也不会丢失。但是如果RabbitMQ服务器停止,我们的任务仍然会丢失。
当RabbitMQ退出或崩溃时,它将忘记队列和消息,除非您告诉它不要这样做。需要做两件事情来确保消息不会丢失:我们需要将队列和消息都标记为持久的。
首先,我们需要确保RabbitMQ永远不会丢失队列。为了做到这一点,我们需要声明它是持久化的:
channel.queue_declare(queue='hello', durable=True)
虽然这个命令本身是正确的,但是在我们的设置中它不能工作。这是因为我们已经定义了一个名为hello的队列,它不持久。RabbitMQ不允许重新定义具有不同参数的现有队列,并且会向试图这样做的任何程序返回一个错误。但是有一个快速的解决方案——让我们声明一个具有不同名称的队列,例如task_queue:
channel.queue_declare(queue='task_queue', durable=True)
这个queue_declare修改需要同时应用于生产者代码和使用者代码。
至此,我们确信即使RabbitMQ重新启动,task_queue队列也不会丢失。现在我们需要将我们的消息标记为持久化——通过提供一个值为2的delivery_mode属性。
channel.basic_publish(exchange='',
routing_key="task_queue",
body=message,
properties=pika.BasicProperties(
delivery_mode = 2, # make message persistent
))
消息持久性注意事项
将消息标记为持久性并不能完全保证消息不会丢失。虽然它告诉RabbitMQ将消息保存到磁盘,但是仍然有一个短时间窗口,当RabbitMQ接受了一条消息并且还没有保存它。此外,RabbitMQ不会对每条消息执行fsync(2)操作——它可能只是被保存为缓存,而不是真正写入磁盘。持久性保证并不强,但对于我们的简单任务队列来说已经足够了。如果您需要更强的保证,那么您可以使用publisher confirmed。
公平分发
您可能已经注意到,调度仍然不能完全按照我们的要求工作。例如,在有两个工人的情况下,当所有奇怪的信息都很重,偶数信息都很轻时,一个工人会一直很忙,而另一个几乎不做任何工作。好吧,RabbitMQ对此一无所知,它仍然会均匀地发送消息。
这是因为RabbitMQ只是在消息进入队列时发送消息。它不查看消费者未确认消息的数量。它只是盲目地将第n个消息发送给第n个消费者。
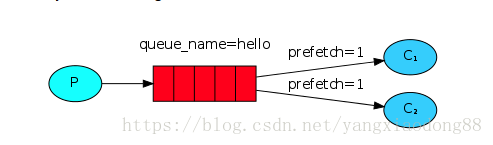
为了打败它,我们可以使用basic语言。设置了prefetch_count=1的qos方法。这告诉RabbitMQ不要一次给一个工人发送多个消息。或者,换句话说,在处理并确认前一条消息之前,不要向工作人员发送新消息。相反,它会把它发送给下一个不太忙的工人。
channel.basic_qos(prefetch_count=1)
关于队列大小的注意事项
如果所有的工人都很忙,你的队伍就会排满。您将希望关注这一点,并可能添加更多的工人,或使用消息TTL。
所有的代码
new_task.py script:
#!/usr/bin/env python
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='task_queue', durable=True)
message = ' '.join(sys.argv[1:]) or "Hello World!"
channel.basic_publish(exchange='',
routing_key='task_queue',
body=message,
properties=pika.BasicProperties(
delivery_mode = 2, # make message persistent
))
print(" [x] Sent %r" % message)
connection.close()
And our worker:
#!/usr/bin/env python
import pika
import time
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='task_queue', durable=True)
print(' [*] Waiting for messages. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
time.sleep(body.count(b'.'))
print(" [x] Done")
ch.basic_ack(delivery_tag = method.delivery_tag)
channel.basic_qos(prefetch_count=1)
channel.basic_consume(callback,
queue='task_queue')
channel.start_consuming()