闭包
理解闭包:
闭包是指延伸了作用域的函数, 其中包含函数定义体中引用、但是不在定义体中定义的非全局变量。函数是不是匿名没有关系, 关键是他能访问定义体之外定义的非全局变量。
闭包基本概念:
闭包是可以包含自由(未绑定到特定对象)变量的代码块, 这个变量不在这个代码块内或者任何全局上下文中定义,而是在定义代码块的环境中定义。要执行的代码块(由于自由变量包含在代码块中, 所以这些自由变量以及他们引用的对象没有被释放)为自由变量提供绑定的计算环境(作用域)
闭包的价值:
闭包的价值在于可以作为函数对象或者匿名函数,对于类型系统而言,这意味着不仅要表示数据还要表示代码。支持闭包的多数语言都将函数作为第一级对象, 也就是说这些函数可以存储到变量中作为参数传递给其他函数, 最重要的是能够被函数动态创建和返回。
闭包注意:
go语言中的闭包同样也会引用到函数外的变量。闭包的实现确保只要闭包还被使用, 那么被闭包引用的变量会一直存在。
闭包引用的变量一直存在, 内存消耗比较大, 要注意, 不能滥用闭包
使用闭包实现斐波那契数列
package main
import "fmt"
func fib2() func() int {
a := 0
b := 1
f := func() int {
s := a
a = b
b = s + b
return s
}
return f
}
func main() { // 打印出每一个值
f := fib2()
for i := 0; i < 10; i++ {
fmt.Println(f())
}
}
使用闭包代替递归求斐波那契之和
package main
import "fmt"
// 闭包求和
func fib4() func() int {
a := 0
b := 1
sum := 0
f := func() int {
s := a
a = b
b = s + b
sum = sum + s
return sum
}
return f
}
func main() {
f := fib4()
for i := 0; i < 10; i++ {
fmt.Println(f())
}
}
一些理解可以参见这篇文章
https://www.cnblogs.com/cxying93/p/6103375.html
闭包的使用场景
- 使用闭包代替全局变量
- 函数外或在其他函数中访问某一函数内部的参数(变量)
- 包装相关功能
- 暂停执行
递归
先通过程序感性认识
递归得阶乘
package main
import "fmt"
func j(n int) int {
if n == 1 || n == 0 {
return 1
}
fmt.Println(n) // 5 4 3 2 这个数据是从前到后变化 逐渐变小
obj := n * j(n-1)
//fmt.Println(obj) // 这里打印可以看出 从小到大 回溯得到 2 6 24 120 这个就是个回溯的过程
return obj
}
// 阅读递归可以 直接 从出口进行得到结果 一直到传入参数 的初始值
func main() {
n := 5
j(n)
//fmt.Println(j(n))
}
递归得斐波那契数列中的值
func fib(n int) uint {
if n == 1 {
return 0 // 递归递到尽头
} else if n == 2 {
return 1
} else {
return fib(n-1) + fib(n-2) // 返回的都是单个具体的值 怎么看返回的到尽头看实现过程。这是归并
}
}
func main() {
n := 10
temp := fib(n)
fmt.Println(temp)
}
递归初识中的一些文章
https://www.cnblogs.com/xzxl/p/7364515.html
这个图比较好
https://www.jianshu.com/p/104187c62e15
递归优缺点:
- 优点:逻辑简单清晰
- 缺点: 使用过深会导致栈溢出
递归基本认识
递归 将这个词语分开看 递 和 归 有去有归
递归的基本思想就是把大规模的问题转化为小规模相似的问题来解决。在函数实现时候, 因为解决大问题的方法和解决小问题的方法往往就是同一个方法, 所以就产生了函数调用自身的情况
递归理解图
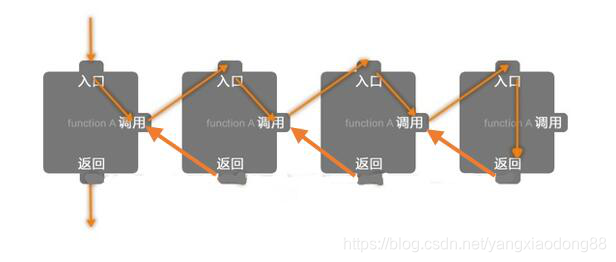
递归从代码层面上来讲 :函数调用自身
递归算法解决问题的特点:
1.递归就是方法里调用自身
2.在使用递增归策略时,必须有一个明确的递归结束条件,称为递归出口。
3.递归算法解题通常显得很简洁,但递归算法解题的运行效率较低。所以一般不提倡用递归算法设计程序。
4.在递归调用的过程当中系统为每一层的返回点、局部量等开辟了栈来存储。递归次数过多容易造成栈溢出等,所以一般不提倡用递归算法设计程序
在需要将一项工作不断分为两项较小的,类似的工作时候, 递归非常有用。递归有时候被称为分而治之策略。
一种理解
首先是思想方法上要转变,不要试图解决问题(这是常规的思考方式),而应该“鼠目寸光”地只想解决一点点,要点是,解决一点点之后,剩下来的问题还是原来的问题,但规模要比原问题小了。
思想和语言是密切相关的,所以问题的提法也很重要。一个问题这样提可能感觉很难写出递归,换种提法,可能就写出来了。
平时就要注意用递归的方式思考,譬如什么是链表?以递归来看就是一个指针,指向一个含有链表的指针。一旦你用这种方式看待链表,你会发现写链表的代码非常容易。反之,则非常容易拖泥带水。
从代码层面看,递归就是函数的循环,所以只要透彻理解函数,写递归代码没什么难的。
递归 栈帧
调用栈描述的是函数之间的调用关系。它由多个栈帧组成,每个栈帧对应着一个未运行完的函数。栈帧中保存了该函数的返回地址和局部变量,因而不仅能在函数执行完毕后找到正确的返回地址,还很自然地保证了不同函数间的局部变量互不相干(因为不同函数对应着不同的栈帧)
下面举个例子加强理解。
皇帝(拥有main函数的栈帧):大臣,你给我算一下f(3)。
大臣(拥有f(3)的栈帧):知府,你给我算一下f(2)。
知府(拥有f(2)的栈帧):县令,你给我算一下f(1)。
县令(拥有f(1)的栈帧):师爷,你给我算一下f(0)。
师爷(拥有f(0)的栈帧):回老爷,f(0)=1。
县令(心算f(1)=f(0)*1=1):回知府大人,f(1)=1。
知府(心算f(2)=f(1)*2=2):回大人,f(2)=2。
大臣(心算f(3)=f(2)*3=6):回皇上,f(3)=6。
皇帝满意了。
通过这个例子可以说明一些问题, 递归调用时候新建了一个栈帧, 并且跳转到了函数开头处执行, 就好比皇帝找大臣、大臣找知府这样的过程。尽管同一时刻可以有多个栈帧(皇帝、大臣、知府同时处于“等待下级回话”的状态),但“当前代码行”只有一个
补充
调用栈并不储存在可执行文件中,而是在运行时创建。调用栈所在的段称为堆栈段,它有自己的大小,如果调用次数多了,就会产生若干个栈帧,便会发生越界,这种情况称为栈溢出。由于局部变量也是放在堆栈段的,所以局部变量太大也会造成栈溢出,这就是为什么要把较大的数组放在main函数外的原因
递归就是有去(递去)有回(归来)
有去
这要求递归的问题需要是可以用同样的解决办法来回答除了规模大小不同其他完全一样的问题
有回
要求 这些问题不断从大到小,从近及远的过程中, 会有一个终点, 一个临界点 一个baseline, 一个你到了那个点不在往更小更远的地方去的点, 从那个点开始原路返回到原点。
递归思想:
递归思想,把规模大的问题装化为规模小的相似的子问题来解决,在函数实现时,因为解决大问题的方法和解决小问题的方法往往是同一个方法,所以就产生了函数调用它自身的情况。另外这个解决问题的函数必须有明显的结束条件,这样就不会产生无限递归的情况了。
需注意的是,规模大转化为规模小是核心思想,但递归并非是只做这步转化,而是把规模大的问题分解为规模小的子问题和可以在子问题解决的基础上剩余的可以自行解决的部分。而后者就是归的精髓所在,是在实际解决问题的过程