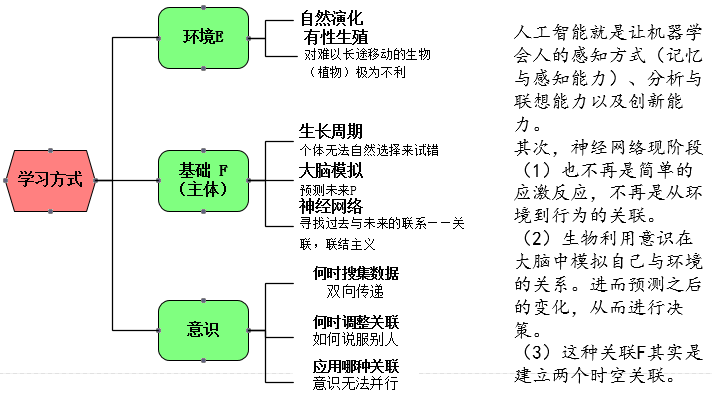
前提/背景知识:
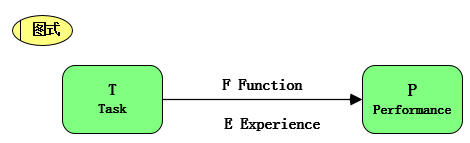
本图是所有ML和DL的切入口
黑盒应该指代T,而通过对E和F的处理(构造新的评价函数、特征工程等),来优化这个预测P
人类天生的四种能力

但在学校考试却仅仅强化了记忆与分析两方面的能力,大大弱化了联想和创新的能力。
而联想能力的高低会对记忆和分析能力训练的成本有强反馈作用,有的人举一反三,有的人死记硬背就在于此;有的人说两句就能上手,但有的人却要考题海战术、赶鸭子上架。
创新能力则是在前三者基础做出价值取向,即朝着更适应环境的方向发展,比如社会xxx,又比如瓦特改良蒸汽机。
本文思路:
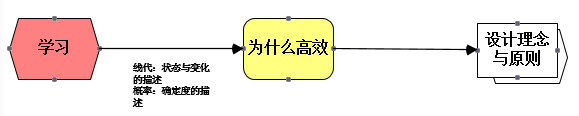
什么是学习:
智能的核心内容——关联能力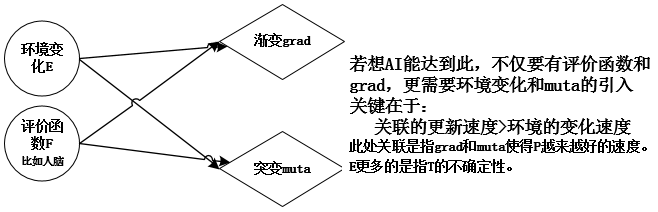
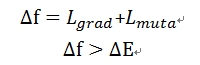
其中L是损失函数即对原有评价函数(比如,人脑现有认知)的调整。
霍金:Intelligence is the ability to adapt to change.
总结:学习就是对环境的适应和自我提升的过程!
第二步:寻找F
方向一:加入更多数据-数据驱动
方向二:加入先验知识,调整假设空间-参数驱动
方向三:不再被动获取数据而是主动适应环境-任务驱动(本文暂不涉及)
参数驱动和任务驱动的区别,参数驱动主要任务学习是学习关联f,而任务驱动是在学习f的同时也要学习E(主动适应环境)!而且现有的参数驱动都很难处理高级突变论的问题~
深度神将网络为什么比数据驱动的方法高效
1、因素(参数)共享:
表述1:新状态由若干旧状态并行组合形成。
表述2:会对变体(复杂组合)进行拆分,其低层权重(参数/因素,准确说应该是子系统)会被共用。可间接增强-关联性/先验性/并行性
2、迭代变换 :在浅层网络中只负责学习自己的关联, 而在深层网络中,那些共用相同因素的样本也会被间接的训练到。
自然界的先验知识:
并行:新状态由若干旧状态并行组合形成。
迭代:新状态由已形成的状态再次迭代形成。
小结:
(1)神经网络的高效:“学习的过程是因素间关系拆分,关系的拆分是信息的回卷,信息的回卷是变体的消除,变体的消除是不确定性的缩减”
(2)ANN的变体-RNN、CNN就是提供了更多的十分具有针对性的先验知识,可以缩小搜索的可能性空间,排除掉那些噪音的规律所带来的额外干扰。
设计深度神经网络理念与原则
设计DL的关键在于如何拆分与合并——演化出一个能更好关联T的F的。
通俗的说就是,如何共享这些参数的,这个网络框架又是由什么子系统组成。


从此角度出发:
注意: 所谓“层”(layer)不是图片中的几个圈,而应该是一个状态(时空)到另一个状态|(时空)的变化!
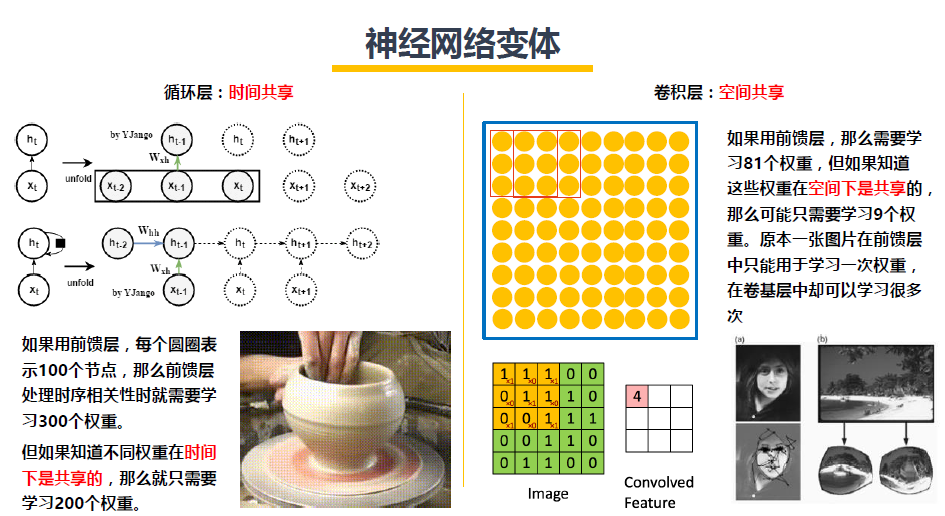
(1)卷积并不针对画面识别,循环也不仅针对时序信号,实质-RNN是时间共享,CNN是空间共享!
时间共享:不同时刻的状态都具有相同规则,这也是物理世界的规律。具体的说,循环层有两个共享,一个是从输入流得到Wh,另一个是信息流是从上一个时刻的状态得到的Wxh。
空间共享:不同区域的状态都具有类似的规则。比如一幅画,虽然画面颜色斑斓,但是每个部分之间都是有一定关联的。
(2)残差网络实现不同层之间的组合而不是本层与下一层的简简单单I/O关系-跨层组合
(3)Distribution(蒸馏模型,类似于RL里面的IRL-模拟学习)是标签共享 !属于迁移学习但又有区别。
(4)迁移学习就是f1(部分层的权重)的共享:

多任务还会有数据上共享:

作用:约束f更快收敛,扩充数据集。
过拟合处理策略

参考资料:
https://github.com/YJango/tensorflow_basic_tutorial