
图 1 双向链表结构示意图
- 指针域:用于指向当前节点的直接前驱节点;
- 数据域:用于存储数据元素。
- 指针域:用于指向当前节点的直接后继节点;

图 2 双向链表的节点构成
因此,双链表的节点结构用 C 语言实现为:


#include<stdlib.h> #include<stdio.h> typedef struct line { struct line* prior;//指向直接前驱 int data; struct line* next;//指向直接后继 }; //初始化双向链表 line *initLine(line* head); //输出双链表函数 void display(line *head); int main() { //创建一个头指针 line* head = NULL; //调用链表创建函数 head = initLine(head); //输出创建好的链表 display(head); //显示双链表的优点 printf("链表中第4个节点的直接前驱节是:%d \n",head->next->next->next->prior->data); return 0; } //创建双链表 line *initLine(line* head) { head = (line*)malloc(sizeof(line));//创建链表第一个节点,首元节点 head->prior = NULL; head->next = NULL; head->data = 1; line* list = head;//声明一个临时节点代替头节点 for (int i = 2; i <= 5; i++) { //创建并初始化一个新节点 line *body = (line*)malloc(sizeof(line)); body->prior = NULL; body->next = NULL; body->data = i; list->next = body;//直接前驱节点的next直接指向新节点 body->prior = list;//新节点直接指向前驱节点 list = list->next;//指针后移一位 } return head; } //显示链表 void display(line *head) { line *temp = head; while (temp) { //如果该节点无后继节点,说明此节点是链表的最后一个节点 if (temp->next==NULL) { printf("%d\n",temp->data); } else { printf("%d <-> ",temp->data); } temp = temp->next; } }
程序运行结果:

双向循环链表
本节知识基于已熟练掌握双向链表创建过程的基础上,我们继续上节所创建的双向链表来学习本节内容,创建好的双向链表如 图 1 所示:

图 1 双向链表示意图
双向链表添加节点
根据数据添加到双向链表中的位置不同,可细分为以下 3 种情况:
1,添加至表头
将新数据元素添加到表头,只需要将该元素与表头元素建立双层逻辑关系即可。,
换句话说,假设新元素节点为 temp,表头节点为 head,则需要做以下 2 步操作即可:
- temp->next=head; head->prior=temp;
- 将 head 移至 temp,重新指向新的表头;
例如,将新元素 7 添加至双链表的表头,则实现过程如图 2 所示:


图 2 添加元素至双向链表的表头

图 3 双向链表中间位置添加数据元素
3,添加至表尾
与添加到表头是一个道理,实现过程如下(如图 4 所示):- 找到双链表中最后一个节点;
- 让新节点与最后一个节点进行双层逻辑关系;

图 4 双向链表尾部添加数据元素
//添加数据 line *insertLine(line* head, int data, int add) { //新建数据域为data的节点 line* temp = head; temp->prior = NULL; temp->next = NULL; temp->data = data; //插入到表头,要特殊考虑 if (add==1) { temp->next = head; head->prior = temp; head = temp;//将 head 移至 temp,重新指向新的表头 } else { line* body = head;//声明一个临时节点,代替头节点 //找到要插入位置的前一个节点 for (int i = 1; i < add - 1;i++) { body = body->next; } //判断位置为真,说明插入位置为链表尾 if (body->next==NULL) { body->next = temp; temp->prior = body; }else { //中间插入 body->next->prior = temp; temp->next = body->next; body->next = temp; temp->prior = body; } } return head; }
双向链表删除节点
双链表删除结点时,只需遍历链表找到要删除的结点,然后将该节点从表中摘除即可。
例如,从图 1 基础上删除元素 2 的操作过程如图 5 所示

图 5 双链表删除元素操作示意图
双向链表删除节点的 C 语言实现代码如下:
//更新函数,add表示更改节点在双链表中的位置newElem为新数据的值 line *mendElem(line *head, int add, int newElem) { line * temp = head; //遍历到被删除节点 for (int i = 1; i < add;i++) { temp = temp->next; } temp->data = newElem; return head; }
总结
这里给出双链表中对数据进行 "增删查改" 操作的完整实现代码:
#include<stdlib.h> #include<stdio.h> typedef struct line { struct line* prior;//指向直接前驱 int data; struct line* next;//指向直接后继 }; //初始化双向链表 line *initLine(line* head); //输出双链表函数 void display(line *head); //双向链表添加数据 line *insertLine(line* head, int data, int add); //删除数据 line *delLine(line *head, int data); //查找元素 int selectElem(line *head, int elem); //双向链表更改节点 line *mendElem(line *p, int add, int newElem); int main() { //创建一个头指针 line* head = NULL; //调用链表创建函数 head = initLine(head); //输出创建好的链表 display(head); //显示双链表的优点 printf("链表中第4个节点的直接前驱节是:%d \n", head->next->next->next->prior->data); //在表中第3的位置插入元素7 head = insertLine(head, 7, 3); display(head); //表中删除元素2 head = delLine(head, 2); display(head); printf("元素3的位置是:%d\n", selectElem(head, 3)); //表中第3个节点中数据改为存储6 head = mendElem(head, 3, 6); display(head); return 0; } //创建双链表 line *initLine(line* head) { head = (line*)malloc(sizeof(line));//创建链表第一个节点,首元节点 head->prior = NULL; head->next = NULL; head->data = 1; line* list = head;//声明一个临时节点代替头节点 for (int i = 2; i <= 5; i++) { //创建并初始化一个新节点 line *body = (line*)malloc(sizeof(line)); body->prior = NULL; body->next = NULL; body->data = i; list->next = body;//直接前驱节点的next直接指向新节点 body->prior = list;//新节点直接指向前驱节点 list = list->next;//指针后移一位 } return head; } //显示链表 void display(line *head) { line *temp = head; while (temp) { //如果该节点无后继节点,说明此节点是链表的最后一个节点 if (temp->next == NULL) { printf("%d\n", temp->data); } else { printf("%d <->", temp->data); } temp = temp->next; } } //添加数据 line * insertLine(line * head, int data, int add) { //新建数据域为data的结点 line * temp = (line*)malloc(sizeof(line)); temp->data = data; temp->prior = NULL; temp->next = NULL; //插入到链表头,要特殊考虑 if (add == 1) { temp->next = head; head->prior = temp; head = temp; } else { line * body = head; //找到要插入位置的前一个结点 for (int i = 1; i<add - 1; i++) { body = body->next; } //判断条件为真,说明插入位置为链表尾 if (body->next == NULL) { body->next = temp; temp->prior = body; } else { body->next->prior = temp; temp->next = body->next; body->next = temp; temp->prior = body; } } return head; } //删除节点的函数,data为要删除节点的数据域的值 line *delLine(line *head, int data) { line * temp = head; //遍历链表 while (temp) { //判断当前节点中数据域和data是否相等,若相等摘除该节点 if (temp->data == data) { temp->prior->next = temp->next; temp->next->prior = temp->prior; free(temp); return head; } temp = temp->next; } printf("链表中无该数据元素"); return head; } //head为原双链表,elem表示被查找元素 int selectElem(line *head, int elem) { //新建一个指针t,初始化为头指针head line *t = head; int i = 1; while (t) { if (t->data == elem) { return i; } i++; t = t->next; } //程序执行至此处表示查询失败 return -1; } //更新函数,add表示更改节点在双链表中的位置newElem为新数据的值 line *mendElem(line *head, int add, int newElem) { line * temp = head; //遍历到被删除节点 for (int i = 1; i < add; i++) { temp = temp->next; } temp->data = newElem; return head; }
运行结果:

四、双向循环链表
1.双向循环链表:最后一个节点的next指向head,而head的prior指向最后一个节点,构成一个环。
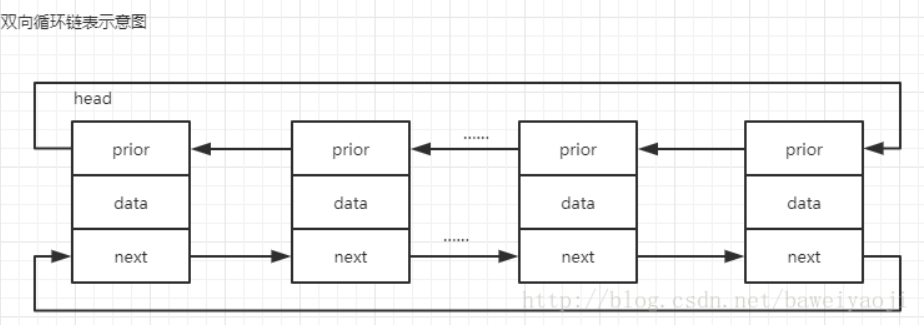
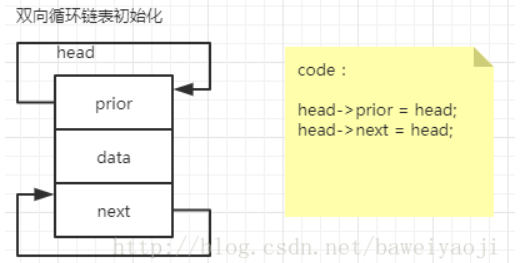
2.初始化:只有一个头节点head,就让prior和next都指向自己。
3.创建:与单向循环链表类似的,只是多了一个prior要考虑。

4.插入:与单向循环链表类似,只是多了一个prior要考虑。这里就不需判断插入的位置是不是在最后了,已经构成一个环了。
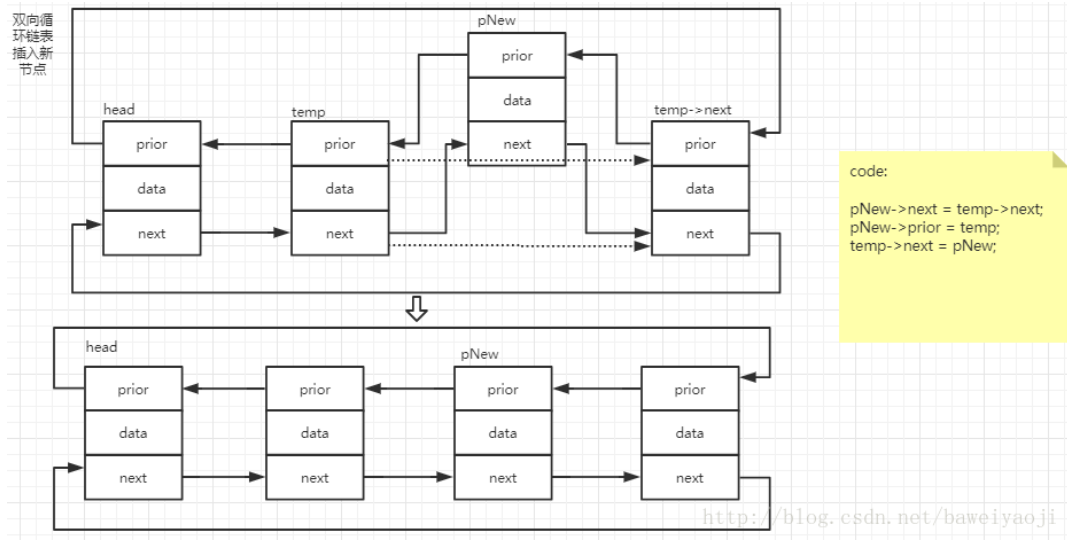
5.删除:
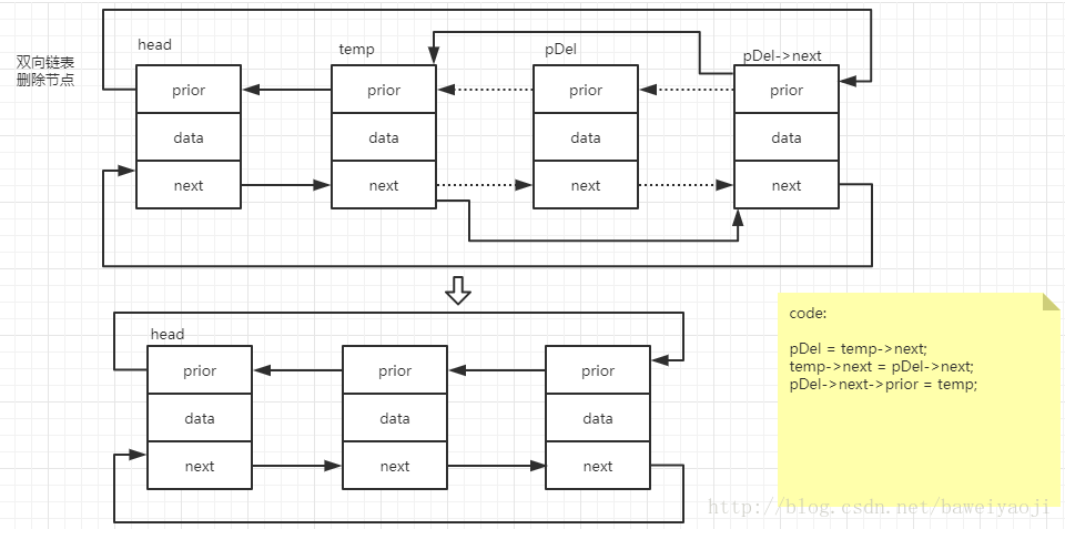
总结:开始时确实要动手画一画图,分析一下各个指针的指向,否则容易在某个地方困扰。还有多阅读别人写的代码,多分析多积累。
双向链表(双向循环链表)的建立及C语言实现

typedef struct line{ struct line * prior; //指向直接前趋 int data; struct line * next; //指向直接后继 }line;
创建双向链表并初始化
双向链表创建的过程中,每一个结点需要初始化数据域和两个指针域,一个指向直接前趋结点,另一个指向直接后继结点。
例如,创建一个双向链表line(1,2,3):

实现代码:
line* initLine(line * head){ head=(line*)malloc(sizeof(line));//创建链表第一个结点(首元结点) head->prior=NULL; head->next=NULL; head->data=1; line * list=head; for (int i=2; i<=3; i++) { //创建并初始化一个新结点 line * body=(line*)malloc(sizeof(line)); body->prior=NULL; body->next=NULL; body->data=i; list->next=body;//直接前趋结点的next指针指向新结点 body->prior=list;//新结点指向直接前趋结点 list=list->next; } return head; }
双向链表中插入结点
比如在(1,2,3)中插入一个结点 4,变成(1,4,2,3)。
实现效果图:

在双向链表中插入数据时,首先完成图 3 中标注为 1 的两步操作,然后完成标注为 2 的两步操作;反之,如果先完成 2,就无法通过头指针访问结点 2,需要额外增设指针,虽然能实现,但较前一种麻烦。
line * insertLine(line * head,int data,int add){ //新建数据域为data的结点 line * temp=(line*)malloc(sizeof(line)); temp->data=data; temp->prior=NULL; temp->next=NULL; //插入到链表头,要特殊考虑 if (add==1) { temp->next=head; head->prior=temp; head=temp; }else{ line * body=head; //找到要插入位置的前一个结点 for (int i=1; i<add-1; i++) { body=body->next; } //判断条件为真,说明插入位置为链表尾 if (body->next==NULL) { body->next=temp; temp->prior=body; }else{ body->next->prior=temp; temp->next=body->next; body->next=temp; temp->prior=body; } } return head; }
双向链表中删除节点
双链表删除结点时,直接遍历链表,找到要删除的结点,然后利用该结点的两个指针域完成删除操作。
例如,在(1,4,2,3)中删除结点 2:
#include <stdio.h> #include <stdlib.h> typedef struct line{ struct line * prior; int data; struct line * next; }line; line* initLine(line * head); line * insertLine(line * head,int data,int add); line * delLine(line * head,int data); void display(line * head); int main() { line * head=NULL; head=initLine(head); head=insertLine(head, 4, 2); display(head); head=delLine(head, 2); display(head); return 0; } line* initLine(line * head){ head=(line*)malloc(sizeof(line)); head->prior=NULL; head->next=NULL; head->data=1; line * list=head; for (int i=2; i<=3; i++) { line * body=(line*)malloc(sizeof(line)); body->prior=NULL; body->next=NULL; body->data=i; list->next=body; body->prior=list; list=list->next; } return head; } line * insertLine(line * head,int data,int add){ //新建数据域为data的结点 line * temp=(line*)malloc(sizeof(line)); temp->data=data; temp->prior=NULL; temp->next=NULL; //插入到链表头,要特殊考虑 if (add==1) { temp->next=head; head->prior=temp; head=temp; }else{ line * body=head; //找到要插入位置的前一个结点 for (int i=1; i<add-1; i++) { body=body->next; } //判断条件为真,说明插入位置为链表尾 if (body->next==NULL) { body->next=temp; temp->prior=body; }else{ body->next->prior=temp; temp->next=body->next; body->next=temp; temp->prior=body; } } return head; } line * delLine(line * head,int data){ line * temp=head; //遍历链表 while (temp) { //判断当前结点中数据域和data是否相等,若相等,摘除该结点 if (temp->data==data) { temp->prior->next=temp->next; temp->next->prior=temp->prior; free(temp); return head; } temp=temp->next; } printf("链表中无该数据元素"); return head; } //输出链表的功能函数 void display(line * head){ line * temp=head; while (temp) { if (temp->next==NULL) { printf("%d\n",temp->data); }else{ printf("%d->",temp->data); } temp=temp->next; } }
总结
双向链表和单链表唯一的不同在于结构中多了一个指向直接前趋的指针,其他完全一样。如果问题中需要频繁的调取当前结点的前趋结点,那使用双向链表的数据结构为最佳方案。
补:双向链表和循环链表的结合体
约瑟夫环问题其实还可以这样玩:如果顺时针报数,有人出列后,顺时针找出出列位置的下一个人,开始反方向(也就是逆时针)报数,有人出列后,逆时针找出出列位置的下一个人,开始顺时针报数。依次重复,直至最后一个出列。
例如,还是从编号为 3 的开始数,数到 2 的人出列:
