我们知道,查询的逻辑处理过程是分阶段完成的,每个阶段都会产生一个虚拟表,该虚拟表会作为下一个阶段的输入。但是,这些过程中间阶段生成的虚拟表对于查询用户是不可用的,只有最后阶段所生成的虚拟表(即查询结果)才返回给查询用户。
多表查询中常用到的九个关键词,并且他们的书写顺序依次为
select–distinct–from–join–on–where–group by–having–order by
这九个关键词的执行顺序
sql语句的执行顺序不是完全跟书写顺序一样从上往下书写执行执行的!而是
根据关键字执行顺序进行执行的!关键字执行顺序依次为
from–on–join–where–group by–having-- select–distinct–order by
1.from:两个表或两个表以上没有通过连接条件进行联接的结果集会产生笛卡儿乘积

2.on:使用on对多表有联接作用,从而对from产生的笛卡儿集进行筛选过滤

3.join:在SQL: 1999 语法中使用join可表与表之间进行外连接!可添加表中未匹配的外部行!

4.where:可以过滤出符合条件的数据!

5.group by:可将上面过滤出的数据根据group by子句中的列进行分组
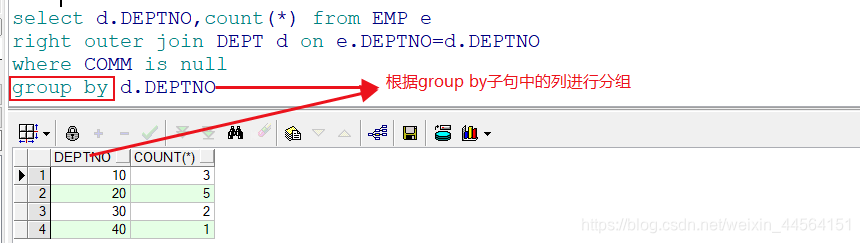
6.having:对上面已经分组的数据进行过滤,

7.select:经过前面的关键字的重重修剪后最后再查看确认结果集中要显示的哪个列,或列的计算结果,从
而查询显示出我们想要的数据来

8.distinct:再把已经查询出来的结果进行去除重复数据过滤,一般经过分组后的数据都是唯一的!不需要去除重复数据

9.order by :把最终的查询结果进行升序ascend或倒序descend排序显示出来!

重点难点:
(1)不管是普通的查询还是复杂的查询中select和from是必须的,其他关键词是可选的
(2)为了避免笛卡尔集,如果是通过where联接的可以在 where 里加入有效的联接条件。如果是在SQL: 1999 语法中使用join进行表与表联接的可以在on里加入有效的联接条件
(3)where子句不能使用分组函数!因为 group by的执行顺序在where之后!所以数据还没有分组!因此不能在where中出现对统计的过滤
(4)having可以使用分组函数进行过滤!但过滤的效率比where低,尽量用where进行过滤
下面以员工表和部门表的连接查询为例!查询出奖金系数相同的总人数