今天在网络数据采集时,看到一个很有意思的网络爬虫,以前写到过许多爬虫都没有遇到过。做个记录写下来吧
HTTP基本接入认证:
在发明cookie之前,处理网站登录最常用的方法就是用HTTP基本接入认证,例如用来测试网站:http://pythonscraping.com/pages/auth/login.php
直接打开网页如图:

当输入用户名和密码(随便设置)时如图。

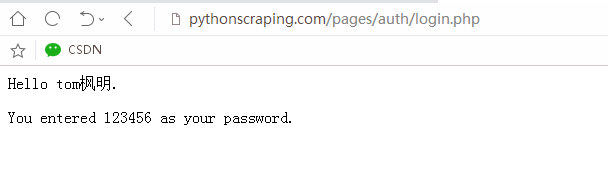
之后抓了个包看看。
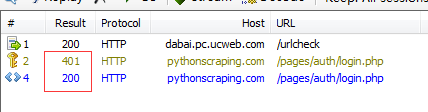
HTTP basic access authentication 过程可以去网络上查查,这里推荐个大牛:https://juejin.im/entry/5ac175baf265da239e4e3999
下面是爬虫部分。
直接请求返回的是401。

加入认证信息:

代码:
# -*- coding: utf8 -*-
"""
# __author__ = "Tom枫明"
# HomePage: https://blog.csdn.net/fm345689
# Python -V: Python 3.6.1
"""
"""
http基本接入认证
"""
import requests
from requests.auth import AuthBase
from requests.auth import HTTPBasicAuth
auth = HTTPBasicAuth("tom枫明".encode('utf-8'),"123456")
resopnse = requests.post("http://pythonscraping.com/pages/auth/login.php",auth=auth)
pass