1、简介
Oracle字符集是一个字节数据的解释的符号集合,有大小之分,有相互的包容关系。ORACLE 支持国家语言的体系结构允许你使用本地化语言来存储,处理,检索数据。它使数据库工具,错误消息,排序次序,日期,时间,货币,数字,和日历自动适应本地化语言和平台。
影响Oracle数据库字符集最重要的参数是NLS_LANG参数。
它的格式如下: NLS_LANG = language_territory.charset
它有三个组成部分(语言、地域和字符集),每个成分控制了NLS子集的特性。
其中:
①、Language: 指定服务器消息的语言, 影响提示信息是中文还是英文
②、Territory: 指定服务器的日期和数字格式,
③、Charset: 指定字符集。
如:AMERICAN _ AMERICA. ZHS16GBK
从NLS_LANG的组成我们可以看出,真正影响数据库字符集的其实是第三部分。
所以两个数据库之间的字符集只要第三部分一样就可以相互导入导出数据,前面影响的只是提示信息是中文还是英文。
Oracle的字符集命名遵循以下命名规则:
<Language><bit size><encoding>
即: <语言><比特位数><编码>
比如: ZHS16GBK表示采用GBK编码格式、16位(两个字节)简体中文字符集
2、数据库字符集(oracle服务器端字符集)
数据库字符集在创建数据库时指定,在创建后通常不能更改。在创建数据库时,可以指定字符集(CHARACTER SET)和国家字符集(NATIONAL CHARACTER SET)。
可以查询以下数据字典或视图查看字符集设置情况
nls_database_parameters
v$nls_parameters
其中 --> NLS_CHARACTERSET表示字符集,
--> NLS_NCHAR_CHARACTERSET表示国家字符集
①、字符集
(1)用来存储CHAR, VARCHAR2, CLOB, LONG等类型数据
(2)用来标示诸如表名、列名以及PL/SQL变量等
(3)用来存储SQL和PL/SQL程序单元等
②、国家字符集
(1)用以存储NCHAR, NVARCHAR2, NCLOB等类型数据
(2)国家字符集实质上是为oracle选择的附加字符集,主要作用是为了增强oracle的字符处理能力,因为NCHAR数据类型可以提供对亚洲使用定长多字节编码的支持,而数据库字符集则不能。国家字符集在oracle9i中进行了重新定义,只能在unicode编码中的AF16UTF16和UTF8中选择,默认值是AF16UTF16
数据库字符集在创建后原则上不能更改。不过有2种方法可行。
如果需要修改字符集:1. 通常需要导出数据库数据,重建数据库,再导入数据库数据的方式来转换。
2. 通过ALTER DATABASE CHARACTER SET语句修改字符集,但创建数据库后修改字符集是有限制的,只有新的字符集是当前字符集的超集时才能修改数据库字符集,例如UTF8是US7ASCII 的超集,修改数据库字符集可使用ALTER DATABASE CHARACTER SET UTF8。
3、客户端字符集(NLS_LANG参数)
任何发自或发往客户端的字符数据均使用客户端定义的字符集编码,客户端可以看作是能与数据库直接连接的各种应用,例如sqlplus,exp/imp等。客户端字符集是通过设置NLS_LANG参数来设定的。
NLS_LANG参数格式
NLS_LANG=<language>_<territory>.<client character set>
Language: 显示oracle消息,校验,日期命名
Territory:指定默认日期、数字、货币等格式
Client character set:指定客户端将使用的字符集
例如:NLS_LANG=AMERICAN_AMERICA.US7ASCII
AMERICAN是语言,AMERICA是地区,US7ASCII是客户端字符集
4、客户端字符集设置方法
①、Windows:
#常用中文字符集
set NLS_LANG=SIMPLIFIED CHINESE_CHINA.ZHS16GBK
#常用unicode字符集
set NLS_LANG=american_america.AL32UTF8
可以通过修改注册表键值永久设置
编辑注册表:Regedit.exe ---> HKEY_LOCAL_MACHINE --->SOFTWARE ---> ORACLE ---> HOMExx ---> NLS_LANG
②、Unix:
#常用unicode字符集
export NLS_LANG=american_america.AL32UTF8
#常用中文字符集
export NLS_LANG=SIMPLIFIED CHINESE_CHINA.ZHS16GBK
可以编辑 bash_profile 文件进行永久设置
vi .bash_profile
export NLS_LANG="SIMPLIFIED CHINESE_CHINA.ZHS16GBK"
或export NLS_LANG="Simplified Chinese_china".ZHS16GBK
#使bash_profile 设置生效
source .bash_profile
5、EXP/IMP与字符集
Export 将 Oracle 数据库中的数据输出到操作系统文件中, Import 把这些文件中的数据读到Oracle 数据库中,由于使用exp/imp进行数据迁移时,数据从源数据库到目标数据库的过程中有四个环节涉及到字符集,如果这四个环节的字符集不一致,将会发生字符集转换。
四个字符集是:
(1)源数据库字符集
(2)Export过程中用户会话字符集(通过NLS_LANG设定)
(3)Import过程中用户会话字符集(通过NLS_LANG设定)
(4)目标数据库字符集
在Export过程中,如果源数据库字符集与Export用户会话字符集不一致,会发生字符集转换,并在导出文件的头部几个字节中存储Export用户会话字符集的ID号。在这个转换过程中可能发生数据的丢失。
如果源数据库使用ZHS16GBK,而Export用户会话字符集使用US7ASCII,由于ZHS16GBK是16位字符集,而US7ASCII是7位字符集,这个转换过程中,中文字符在US7ASCII中不能够找到对等的字符,所以所有中文字符都会丢失而变成“?? ”形式,这样转换后生成的Dmp文件已经发生了数据丢失。
因此如果想正确导出源数据库数据,则Export过程中用户会话字符集应等于源数据库字符集或是源数据库字符集的超集。
6、导入的转换过程
(1)确定导出数据库字符集环境
通过读取导出文件头,可以获得导出文件的字符集设置
(2)确定导入session的字符集,即导入Session使用的NLS_LANG环境变量
(3)IMP读取导出文件
读取导出文件字符集ID,和导入进程的NLS_LANG进行比较
(4)如果导出文件字符集和导入Session字符集相同,那么在这一步骤内就不需要转换,如果不同,就需要把数据转换为导入Session使用的字符集。可以看出,导入数据到数据库过程中发生两次字符集转换
第一次:导入文件字符集与导入Session使用的字符集之间的转换,如果这个转换过程不能正确完成,Import向目标数据库的导入过程也就不能完成。
第二次:导入Session字符集与数据库字符集之间的转换。
7、汇总查看数据库字符集(总结)
涉及三方面的字符集:
(1)oracel server端的字符集;
(2)oracle client端的字符集;
(3)dmp文件的字符集。
在做数据导入的时候,需要这三个字符集都一致才能正确导入。
①、查询oracle server端的字符集
select userenv('language') from dual;
②、查询oracle client端的字符集
在windows平台下,就是注册表里面相应OracleHome的NLS_LANG。还可以在dos窗口里面自己设置,比如: set nls_lang=AMERICAN_AMERICA.ZHS16GBK这样就只影响这个窗口里面的环境变量。
在unix平台下,就是环境变量NLS_LANG。$echo $NLS_LANG
如果检查的结果发现server端与client端字符集不一致,请统一修改为同server端相同的字符集。
③、查询dmp文件的字符集:
用oracle的exp工具导出的dmp文件也包含了字符集信息,dmp文件的第2和第3个字节记录了dmp文件的字符集。如果dmp文件不大,比如只有几M或几十M,可以用UltraEdit打开(16进制方式),看第2第3个字节的内容,如0354,然后用以下SQL查出它对应的字符集:
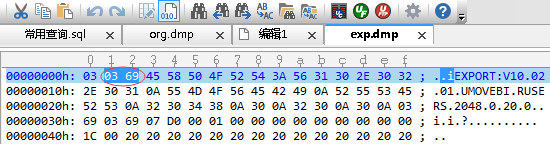
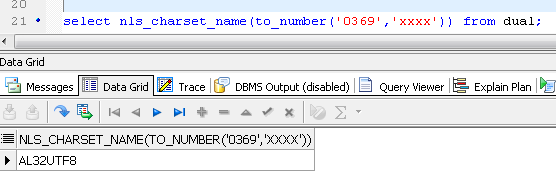
--可用以下SQL查询 select nls_charset_name(to_number('0369','xxxx')) from dual; --大部分都是‘0354’ select nls_charset_name(to_number('0354','xxxx')) from dual; --结果:0354 --> ZHS16GBK
如果dmp文件很大,比如有2G以上(这也是最常见的情况),用文本编辑器打开很慢或者完全打不开,可以用以下命令(在unix主机上):
cat exp.dmp |od -x|head -1|awk '{print $2 $3}'|cut -c 3-6
[root@192 tmp]# ls -lh 总用量 199M -rw-r--r--. 1 root root 199M 5月 4 20:42 20190504.dmp -rw-r-----. 2 root root 23 7月 4 2014 issue.hard [root@192 tmp]# cat 20190504.dmp |od -x|head -1|awk '{print $2 $3}'|cut -c 3-6 0345
然后用上述SQL也可以得到它对应的字符集。
(PS:如果服务器字符集为SIMPLIFIED CHINESE_CHINA.ZHS16GBK,dmp的字符集不为ZHS16GBK时,也可以通过修改dmp中的第2,3字节数字来骗过导入时的字符集验证)
常用查询
--(1).数据库服务器字符集 select * from NLS_DATABASE_PARAMETERS;--显示数据库当前NLS参数取值,包括数据库字符集取值 select * from V$NLS_PARAMETERS;--显示数据库当前NLS参数取值 select * from v$nls_valid_values;--查看数据库可用字符集参数设置 来源于props$,是表示数据库的字符集。 --(2).客户端字符集环境 select * from nls_instance_parameters; 其来源于v$parameter,表示客户端的字符集的设置,可能是参数文件,环境变量或者是注册表 --(3).会话字符集环境 select * from nls_session_parameters;--显示由NLS_LANG 设置的参数,或经过alter session 改变后的参数值(不包括由NLS_LANG 设置的客户端字符集) 来源于v$nls_parameters,表示会话自己的设置,可能是会话的环境变量或者是alter session完成,如果会话没有特殊的设置,将与nls_instance_parameters一致。 --(4).客户端的字符集要求与服务器一致,才能正确显示数据库的非Ascii字符。 如果多个设置存在的时候,NLS作用优先级别:Sql function > alter session > 环境变量或注册表 > 参数文件 > 数据库默认参数 字符集要求一致,但是语言设置却可以不同,语言设置建议用英文。如字符集是zhs16gbk,则nls_lang可以是American_America.zhs16gbk。
8、与字符集相关的问题
(1)、在UTF8环境下运行SQL语句报错的问题:
SQL*PLUS工具不提供编码自动转换的功能,当数据库字符集为UTF8,客户端的NLS_LANG如果也是UTF8,那么在SQL*PLUS中运行 SQL语句时,语句全是英文,不会出现问题,如果语句包含了中文或其它一些特殊字符,SQL语句运行时就会报错。对于返回的含中文的结 果,SQL*PLUS也会显示乱码。造成此错误的原因在于当SQL语句中包含汉字等一些特殊字符时,由于这些字符的编码属于GBK,ORACLE没有进行 字符转换,而是直接把SQL语句送到服务器上进行解析。此时服务器的字符集是UTF8,因此它按UTF8编码格式对SQL语句中GBK编码的字符解析时就 会产生错误。如果把客户端的NLS_LANG设置为本地环境的字符集,如ZHS16GBK,此时可以直接在SQL*PLUS中输入包含中文的SQL语 句,ORACLE在把SQL语句提交到服务器时会自动转换成UTF8编码格式,因此SQL语句可以正常运行。对于英文字母,由于它在UTF8中的编码数值 采用的还是ASCII的编码数值,因此英文字母可以直接使用而不需要转换,这就是如果SQL语句或输出结果全是英文时不会出现错误的原因。正确的做法是先 把需要运行的SQL做成脚本文件,用代码转换工具把它转换成UTF8编码格式的文件,(注意!XP中的记事本是提供了代码转换功能的,可以在保存文件或选 择文件另存为的时候,弹出的对话框最后一项,编码,选择UTF8,再保存,即可把文件转换成UTF8编码格式)。完成后用IE打开这个脚本,选择编码-》 UTF8,观察此时SQL脚本是否含有乱码或“?”符号。如果没有,说明编码格式已经是UTF8了,此时在SQL*PLUS中运行这个脚本就不会产生错误 了。运行结束后,输出的结果中如果包含中文,需要把结果SPOOL输出到一个文件中,然后用代码转换工具把这个结果文件由UTF8转换成本地编码格式,再 用写字板打开,才能看到正常显示的汉字。由于IE具有代码转换功能,因此也可以不用代码转换工具,直接在IE中打开输出的结果文件,选择UTF8编码,也 能正常显示含中文的结果文件。
(2)、数据库出现乱码的问题:
数据库出现乱码的问题主要和客户的本地化环境,客户端NLS_LANG设置,服务器端的数据库字符集设置这三者有关,如果它们的设置不一致或者某个设置错误,就会很容易出现乱码,下面我们简要介绍以下几种情况:
①、数据库字符集设置不当引起的乱码
例如:一个存储简体中文字符的数据库,它的字符集选用了US7ASCII,当它的客户端NLS_LANG也选用US7ASCII时,这个系统单独使用是没 有问题的,因为两者设置一致,因此ORACLE不会进行字符集的转换,客户输入的GBK码被直接在数据库中存储起来,当查询数据时,实际客户端取出来的数 据也是GBK的编码,因此显示也是正常的。但当其它的系统需要从这个数据库取数据,或者它的数据要EXP出来,IMP到其它数据库时,问题就会开始出现 了。其它系统的字符集一般是ZHS16GBK,或者其它系统客户端的NLS_LANG设置为ZHS16GBK,此时必然会产生字符集的转换。虽然数据库字 符集设置为US7ASCII,但我们知道,实际存储的数据编码是ZHS16GBK的。可惜ORACLE不会知道,它会把存储的ZHS16GBK编码数据当 作US7ASCII编码的数据,按照US7ASCII转换成ZHS16GBK的转换算法进行转换,可以想象,这种情况下,乱码的产生是必然的。
②、数据库字符集与客户端NLS_LANG设置不同引起的乱码:
例如:对于一个需要存储简体文信息的数据库来说,它的字符集设置和客户端NLS_LANG设置一般可以使用ZHS16GBK编码。但是如果数据库字符集选 用了UTF8的话,也是可以的,因为ZHS16GBK编码属于UTF8的子集。ORACLE在数据库与客户端进行数据交换时自动进行编码的转换,在数据库 中实际存储的也是UTF8编码的数据。此时其它数据库和此数据库也可以正常的进行数据交换,因为ORACLE会自动进行数据的转换。在实际使用中,遇到过 繁体XP的字符集ZHT16MSWIN950转换成AL32UTF8 字符集时,一些特殊的字符和个别冷僻的汉字会变成乱码。后来证实是XP需要安装一个字库补丁软件,最后顺利解决此问题。
③、客户端NLS_LANG与本地化环境不同引起的乱码:
一般情况下,客户端NLS_LANG与本地化环境采用了不同的字符集会出现乱码,除非本地化环境的字符集是客户端NLS_LANG设置字符集的子集。如果 把客户端NLS_LANG设置为UTF8就属于这种情况,由于目前还没有可以直接使用UNICODE字符集的操作系统,因此客户本地化环境使用的字符集只 能是某种语言支持的字符集,它属于UTF8的子集。下面我们就着重讨论这种情况。
虽然目前WINDOWS的内核是支持UNICODE的,但是WINDOWS并不支持直接显示UNICODE编码的字符,而且它并不知道目前的字符采用了何 种字符集,所以默认情况下,它使用缺省的代码页来解释字符。因此,对于其它类型的编码,需要先进行转换,变成系统目前的缺省代码页支持的字符集才能正常使用。
WINDOWS中的缺省代码页是由控制面板设置中的语言及区域的选择所决定的,属于客户本地化的环境设置。简体中文WINDOWS的字符编码就是GBK,它的缺省代码页是936。对于其它非WINDOWS的操作系统,我们可以把它们目前缺省使用的字符集作为用户的本地化环境设置。另外,我们使用的大部分工具,如写字板,SQL*PLUS等,它们没有提供编码转换功能,因此在客户端直接输入或查询数据往往都会遇到乱码的问题,必须由应用程序或一些工具去做编码的转换,才能保证正常的使用。
(注:此为学习记录笔记,仅供参考若有问题请指正,后续补充......)
参考文章:https://www.cnblogs.com/rootq/articles/2049324.html
https://blog.csdn.net/jkl_123/article/details/6157379