简介
Spark 是专为大规模数据处理而设计的快速通用的计算引擎,其是由 scala 语言编写而成。如下图所示,这是显示了 Spark standalone 应用程序上下文中所有的 Spark 组件。
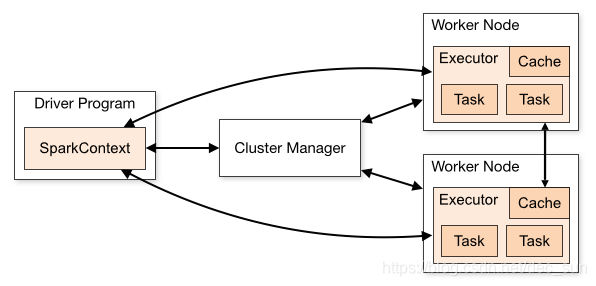
Spark 应用程序是由一个 Driver(驱动程序)和一组 Executor 进程组成。
Driver 进程
负责运行 main 函数,其进程位于集群的一个节点上。其主要:
- 维护有关 Spark 应用程序的信息;
- 响应用户的程序与输入;
- 分析、分配和调度 Executor 的工作。
Spark 引用程序的生命周期从 Driver 程序开始到结束。
Executor 进程
实际执行 driver 分配给他们的工作。Executor 主要负责两件事:
- 执行由驱动程序分配给它的代码;
- 将计算状态报告给驱动节点。
| 注意 |
|---|
| Spark 除了集群 cluster 模式之外,还具有本地 local 模式。driver 驱动程序和 executor 执行器是简单的进程,这意味着它们可以在同一台机器或不同的机器上运行。在本地 local 模式中,驱动程序和执行程序(作为线程)在您的个人计算机上运行,而不是集群。 |
SparkDriver
上述已经介绍了 SparkDriver 主要负责包括
- 维护有关 Spark 应用程序的信息;
- 响应用户的程序或输入;
- 分配和调度 Executor 的 task 和资源。
SparkContext
Spark Driver 程序负责创建 SparkContext。SparkContext 在 spark shell 中对应的变量对象名为 sc。其用于连接 Spark 集群,是与 Spark 集群交互的入口。SparkContext 在 Spark 应用程序的开始实例化,并应用于整个程序。
应用程序执行计划(DAGScheduler)
Driver 程序的主要功能之一就是规划应用程序的执行。驱动程序接受所有 transformation 和 action 操作,并创建一个有向无环图(DAG)。
有向无环图 DAG 是由 tasks 和 stages 组成。task 是 Spark 程序中可调度工作的最小单位。stage 是 一组可以一起运行的 task。多个 stage 之间是相互依存的。
tips:因为是数据不动代码动,所以 DAG 其实是一系列的连续操作的集合。
应用程序的调度(TaskScheduler)
Driver 程序还协调 DAG 中定义的 stage 和 task 的运行。在调度和运行 task 时设计的主要 Driver 活动:
- 跟踪可用资源以执行 task。
- 调度任务,以便在可能的情况下,“接近”数据运行
- 协调数据在 stage 之间的移动。
tips:一系列的连续数据操作形成后,数据就通过这些连续操作,生成新的结果。
其它功能
Driver 驱动处理计划和编排 Spark 程序的执行之外。其还负责从应用程序返回结果。driver 程序在 4040 端口上自动创建了应用程序 UI。如果在同一个主机上启动后续应用程序,则会为应用程序 UI 使用连续的端口(例如 4041、4042 等等)。
Executor
executor 的主要工作:
- 执行由驱动程序分配给它的代码(task)
- 将执行器 executor 的计算状态报告给 driver 节点
Executor 和 Worker
Spark Executor 是运行来自 Spark DAG 的 task 进程。Executor 在 Spark 集群中的 worker 节点上获取 CPU 和内存等计算资源。Executor 专用于特定的 Spark 应用程序,并在应用程序完成而终止。在Spark 程序中,Spark Executor 可以运行成百上千的 task。
通常情况下,work 节点具有有限个 Executor。因此:一个 worker 节点上存在有限数量级的 Executor 进程,一个 Executor 进程可以运行多个 task。
Spark Executor 驻留在 jvm 中。Executor 的 jvm 分配了一个堆内存,这是一个用于存储和管理对象的专用内存空间。堆内存的大小由 Spark 配置文件 spark-default.xml 中的 spark.executor.memory 属性确定,或者由提交应用程序时 spark-submit 的参数 --executor-memory 确定。
Worker 和 Executor 只知道分配给它的 task,而 Driver 程序负责理解组成应用程序的完整 task 集合它们各自的依赖关系。
Master 和 ClusterManager
Spark Driver 程序计划并协调运行 Spark 应用程序所需的 task 集。task 本身在 Executor 中运行,Executor 驻留在 worker 节点上。
Master 和 Cluster 是监控、分配、回收集群( Executor 运行的节点)资源的核心进程,Master 和Cluster Manager 可以是各自独立的进程(Spark OnYarn),也可以组合成一个进程(Standalone 运行模式)。
Master
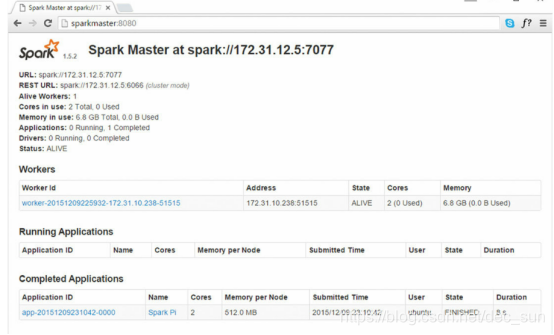
Spark master 用于请求集群中的资源并将资源提供给 Spark Driver 程序的进程。
Spark Master 进程在 Master 进程所在主机上的端口为 8080,提供 web 用户界面。
tips:master 只是请求资源,并将资源分配给 driver。但是 Master 只是监控这些资源的状态和健康情况而不参与应用程序的执行已经 task 与 stage 的协调。
Cluster Manager
Cluster Manager 进程负责监控分配给 Worker 节点上的资源,这些资源是 Master 进程请求分配的。然后 Master 以 Executor 的形式将集群资源提供给 Driver 程序。如前所述,集群管理器可以独立于 master 进程(Spark On Yarn),也可以组合成一个进程(Standalone 运行模式)。
Tips:
- Driver -> SparkContext:与集群交互的入口;
- Driver -> DAGScheduler:创建有向无环图 DAG;
- Driver -> TaskScheduler:执行调度 Task;
- Worker:集群节点,上面运行了 Executor 进程,一个 worker 可以运行有限个 executor;
- Executor:在 Worker 节点上运行,运行 task 任务。一个Executor可以运行多个 task 任务。
- Master:分配资源到 Driver 程序的进程。
- Cluster Manager: 在standalone 模式下,与 master 组合成一个进程;在 spark on yarn 模式下,可以独立于master进程。