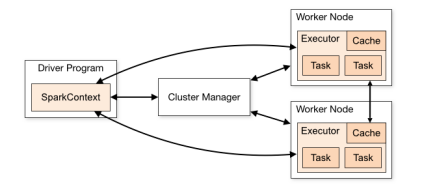
这是 Spark 的基本框架图。
- Driver 程序初始化 SparkContext 对象;
- SparkContext 对象初始化过程中,连接集群资源管理器 Cluster Manager,申请资源,注册 app 信息;
- Cluster Manager 根据 Driver 申请的资源,在 worker 节点创建 Executor;
- 创建好的 Executor 将其信息发送到 Driver,申请注册;
- Driver 将创建一个 job,并交给 DAGSchedule;
- DAGSchedule 会把 job 分成多个 stages,并为每个 stage 创建一个 taskset 集合,集合中的 task 计算逻辑完全相同,只是处理的数据不同;
- DAGSchedule 会把 taskset 交给 TaskSchedule,TaskSchedule 再把 taskset 里的 task 发送给 Executor;
- Executor 接收到 task,会启动一个线程池 TaskRunner,在里面运行 task 任务。
这是一个 Application 应用程序执行的一系列基本操作。现在就通过分析源码的方式来追踪分析下代码是如何处理的。
SparkContext 对象负责与 Spark 集群交互,支持本地 local 模式和集群等模式。在开发 Spark 应用程序时,首先会创建 SparkConf 对象 – SparkConf 是参数配置的类;之后 SparkConf 对象作为参数传递给 SparkContext。
-- SparkContext.scala
class SparkContext(config: SparkConf) extends Logging {
// The call site where this SparkContext was constructed.
private val creationSite: CallSite = Utils.getCallSite()
// 阻止同时有多个 SparkContext 实例被创建激活,因为一个JVM 只能有一个 SparkContext 实例。
SparkContext.markPartiallyConstructed(this)
val startTime = System.currentTimeMillis()
private[spark] val stopped: AtomicBoolean = new AtomicBoolean(false)
}
接着会对设置的 SparkConf 进行解析确认,判断所必须的参数是否缺失。这里可以发现,其通过 clone 浅拷贝一份副本,保证设置的参数不会被修改。
-- SparkContext.scala
try {
_conf = config.clone()
_conf.validateSettings()
if (!_conf.contains("spark.master")) {
throw new SparkException("A master URL must be set in your configuration")
}
if (!_conf.contains("spark.app.name")) {
throw new SparkException("An application name must be set in your configuration")
}
_driverLogger = DriverLogger(_conf)
// log out spark.app.name in the Spark driver logs
logInfo(s"Submitted application: $appName")
完成上述参数的确认后,构建 Spark 的运行环境
-- SparkContext.scala
// Create the Spark execution environment (cache, map output tracker, etc)
_env = createSparkEnv(_conf, isLocal, listenerBus)
SparkEnv.set(_env)
这里在上述程序执行过程中,SparkContext 初始化的一系列操作。
现在先来看看环境是如何创建的。
Spark 的环境处理在 SparkEnv.scala 中,这里可以知道,在初始化时,首先创建的是 Driver 的环境。
-- SparkEnv.scala
private[spark] def createDriverEnv(
conf: SparkConf,
isLocal: Boolean,
listenerBus: LiveListenerBus,
numCores: Int,
mockOutputCommitCoordinator: Option[OutputCommitCoordinator] = None): SparkEnv = {
val ioEncryptionKey = if (conf.get(IO_ENCRYPTION_ENABLED)) {
Some(CryptoStreamUtils.createKey(conf))
} else {
None
}
create(
conf,
SparkContext.DRIVER_IDENTIFIER,
bindAddress,
advertiseAddress,
Option(port),
isLocal,
numCores,
ioEncryptionKey,
listenerBus = listenerBus,
mockOutputCommitCoordinator = mockOutputCommitCoordinator
)
}
如果不考虑加密的话,或者说没有设置加密属性,那么走:
-- SparkEnv.scala
private def create(
conf: SparkConf,
executorId: String,
bindAddress: String,
advertiseAddress: String,
port: Option[Int],
isLocal: Boolean,
numUsableCores: Int,
ioEncryptionKey: Option[Array[Byte]],
listenerBus: LiveListenerBus = null,
mockOutputCommitCoordinator: Option[OutputCommitCoordinator] = None): SparkEnv = {
这里创建 Spark 环境,首先是 Driver 的环境。所以, executorId == SparkContext.DRIVER_IDENTIFIER。
这里亦发现了,实例化了 Application 应用程序的类。

-- SparkEnv.scala
def instantiateClass[T](className: String): T = {
val cls = Utils.classForName(className)
// Look for a constructor taking a SparkConf and a boolean isDriver, then one taking just
// SparkConf, then one taking no arguments
try {
cls.getConstructor(classOf[SparkConf], java.lang.Boolean.TYPE)
.newInstance(conf, java.lang.Boolean.valueOf(isDriver))
.asInstanceOf[T]
} catch {
case _: NoSuchMethodException =>
try {
cls.getConstructor(classOf[SparkConf]).newInstance(conf).asInstanceOf[T]
} catch {
case _: NoSuchMethodException =>
cls.getConstructor().newInstance().asInstanceOf[T]
}
}
}
同时还实例化了:Boardcast,mapOutputTracker – 主要根据 map 任务把数据结果写到哪里。
同时也实例化了 shuffleManager,Shuffle 有两种管理器,分别是 sort 和 tungsten-sort。
-- SparkEnv.scala
val shortShuffleMgrNames = Map(
"sort" -> classOf[org.apache.spark.shuffle.sort.SortShuffleManager].getName,
"tungsten-sort" -> classOf[org.apache.spark.shuffle.sort.SortShuffleManager].getName)
val shuffleMgrName = conf.get(config.SHUFFLE_MANAGER)
val shuffleMgrClass =
shortShuffleMgrNames.getOrElse(shuffleMgrName.toLowerCase(Locale.ROOT), shuffleMgrName)
val shuffleManager = instantiateClass[ShuffleManager](shuffleMgrClass)
实例化了内存管理器
-- SparkEnv.scala
val memoryManager: MemoryManager = UnifiedMemoryManager(conf, numUsableCores)
以及块管理器。BlockManagerMaster 块管理器是用来获取、协调、管理远程节点上的 Block 集合。创建的 BlockManager,主要运行在 Worker 节点上。这里虽然创建成功了,但是只有在 BlockManager 中初始化函数之后才执行相关操作。
-- SparkEnv.scala
val blockManagerPort = if (isDriver) {
conf.get(DRIVER_BLOCK_MANAGER_PORT)
} else {
conf.get(BLOCK_MANAGER_PORT)
}
val blockTransferService =
new NettyBlockTransferService(conf, securityManager, bindAddress, advertiseAddress,
blockManagerPort, numUsableCores)
val blockManagerMaster = new BlockManagerMaster(registerOrLookupEndpoint(
BlockManagerMaster.DRIVER_ENDPOINT_NAME,
new BlockManagerMasterEndpoint(rpcEnv, isLocal, conf, listenerBus)),
conf, isDriver)
至此,Spark 运行环境基本在 SparkEnv.create中初始化完毕。