1. Fork/Join框架
fork操作的作用是把一个大的问题划分成若干个较小的问题。在这个划分过程一般是递归进行的。直到可以直接进行计算。需要恰当地选取子问题的大小。太大的子问题不利于通过并行方式来提高性能,而太小的子问题则会带来较大的额外开销。每个子问题计算完成后,可以得到关于整个问题的部分解。join操作的作用是把这些分解手机组织起来,得到完整解。
简单的说,ForkJoin其核心思想就是分治。Fork分解任务,Join收集数据。
2. Fork/Join框架的主要类
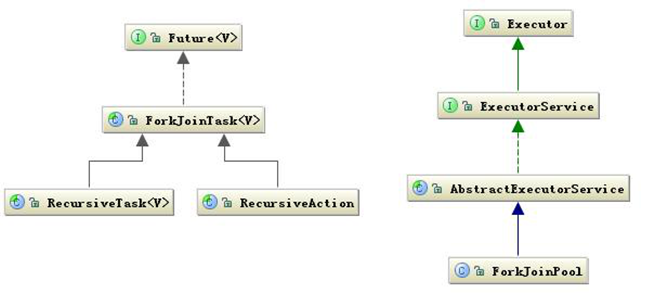
一个fork/join框架之下的任务由ForkJoinTask类表示。ForkJoinTask实现了Future接口,可以按照Future接口的方式来使用。在ForkJoinTask类中之重要的两个方法fork和join。fork方法用以一部方式启动任务的执行,join方法则等待任务完成并返回指向结果。在创建自己的任务是,最好不要直接继承自ForkJoinTask类,而要继承自ForkJoinTask类的子类RecurisiveTask或RecurisiveAction类。两种的区别在于RecurisiveTask类表示的任务可以返回结果,而RecurisiveAction类不行。
简单总结:
ForkJoin主要提供了两个主要的执行任务的接口。RecurisiveAction与RecurisiveTask 。
- RecurisiveAction :没有返回值的接口。
- RecurisiveTask :带有返回值的接口
parallelStream是什么
parallelStream其实就是一个并行执行的流.它通过默认的ForkJoinPool,可能提高你的多线程任务的速度.
parallelStream的作用
Stream具有平行处理能力,处理的过程会分而治之,也就是将一个大任务切分成多个小任务,这表示每个任务都是一个操作,因此像以下的程式片段:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9);
numbers.parallelStream()
.forEach(out::println);
1
2
3
4
parallelStream背后的男人:ForkJoinPool
要想深入的研究parallelStream之前,那么我们必须先了解ForkJoin框架和ForkJoinPool.本文旨在parallelStream,但因为两种关系甚密,故在此简单介绍一下ForkJoinPool,如有兴趣可以更深入的去了解下ForkJoin***(当然,如果你想真正的搞透parallelStream,那么你依然需要先搞透ForkJoinPool).*
ForkJoin框架是从jdk7中新特性,它同ThreadPoolExecutor一样,也实现了Executor和ExecutorService接口。它使用了一个无限队列来保存需要执行的任务,而线程的数量则是通过构造函数传入,如果没有向构造函数中传入希望的线程数量,那么当前计算机可用的CPU数量会被设置为线程数量作为默认值。
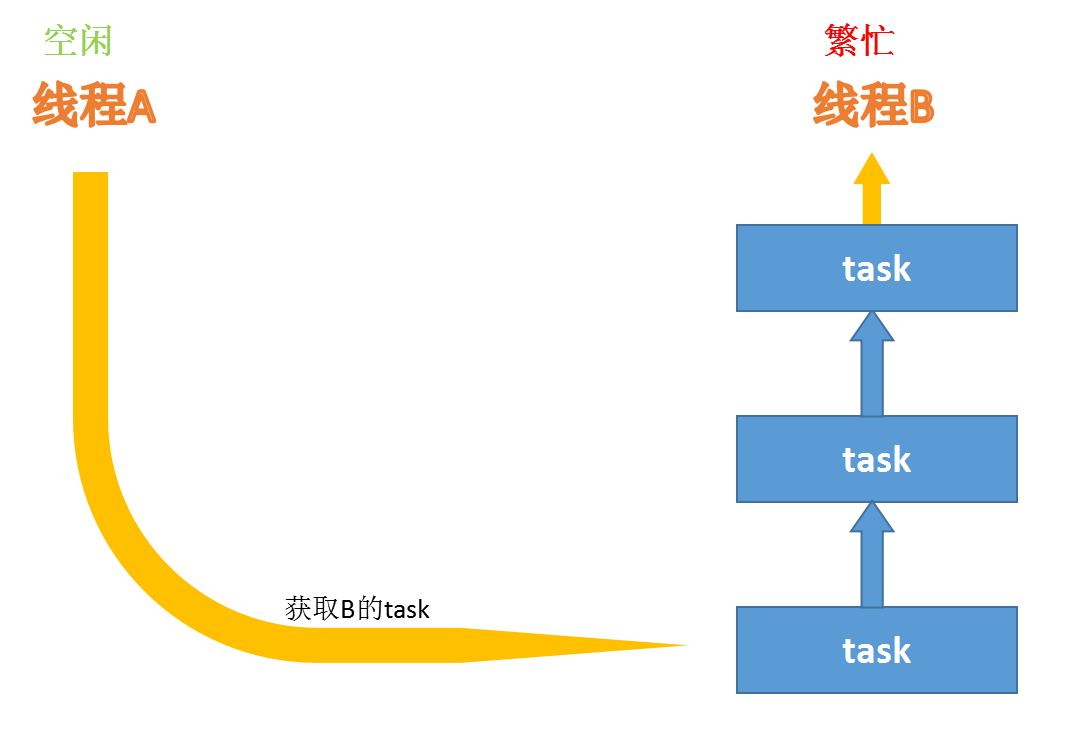
工作窃取算法
forkjoin最核心的地方就是利用了现代硬件设备多核,在一个操作时候会有空闲的cpu,那么如何利用好这个空闲的cpu就成了提高性能的关键,而这里我们要提到的工作窃取(work-stealing)算法就是整个forkjion框架的核心理念,工作窃取(work-stealing)算法是指某个线程从其他队列里窃取任务来执行。
那么为什么需要使用工作窃取算法呢?
假如我们需要做一个比较大的任务,我们可以把这个任务分割为若干互不依赖的子任务,为了减少线程间的竞争,于是把这些子任务分别放到不同的队列里,并为每个队列创建一个单独的线程来执行队列里的任务,线程和队列一一对应,比如A线程负责处理A队列里的任务。但是有的线程会先把自己队列里的任务干完,而其他线程对应的队列里还有任务等待处理。干完活的线程与其等着,不如去帮其他线程干活,于是它就去其他线程的队列里窃取一个任务来执行。而在这时它们会访问同一个队列,所以为了减少窃取任务线程和被窃取任务线程之间的竞争,通常会使用双端队列,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务的线程永远从双端队列的尾部拿任务执行。