算法复杂度:
常见的增长数量级函数:
1,logN,N,NlogN, N^2,N^3,2^N
除了指数级别 都满足:
T(N)~aN^blgN
所以T(2N)/T(N)~2^b (详见算法p122)
1.并查集
并查集(Union-Find)算法介绍 - dm_vincent的专栏 - CSDN博客 https://blog.csdn.net/dm_vincent/article/details/7655764
并查集(Union-Find) 应用举例 --- 基础篇 - dm_vincent的专栏 - CSDN博客 https://blog.csdn.net/dm_vincent/article/details/7769159
算法代码实现之Union-Find,C++实现,quick-find、quick-union、加权quick-union(附带路径压缩优化) - 陈鹏万里 - CSDN博客 https://blog.csdn.net/QQ245671051/article/details/50763168 (感觉有点小问题)
2.链表
1)单向链表

a)单向链表的指针实现
先定义一个模板类 <T>Node,数据成员T data,和 Node *next
一个单链表的节点(Node)分为两个部分,第一个部分(data)保存或者显示关于节点的信息,另一个部分next存储下一个节点的地址。最后一个节点存储地址的部分指向空值(nullptr)。
然后再定义一个模板类SingleList, private数据成员Node *first,first的next指向真正的第一个节点
单向链表只可向一个方向遍历,一般查找一个节点的时候需要从第一个节点开始每次访问下一个节点,一直访问到需要的位置。
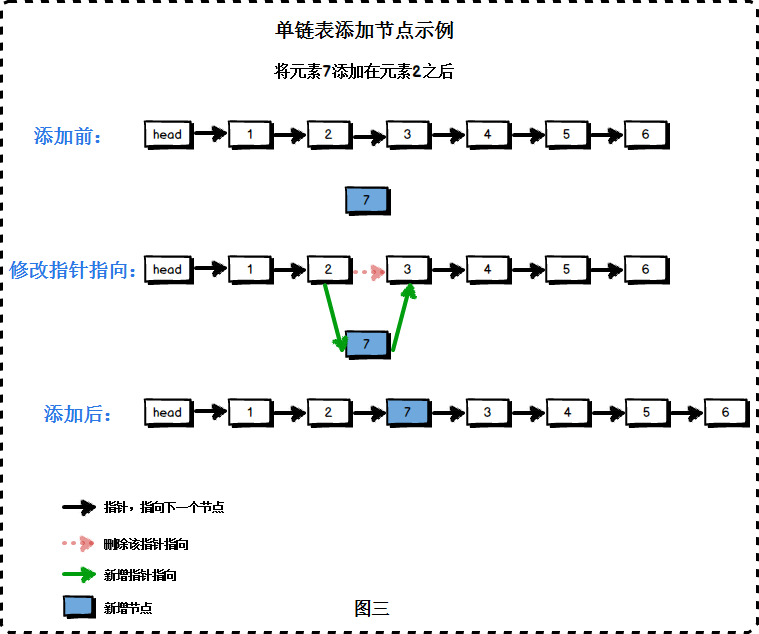
参考资料:http://www.cnblogs.com/QG-whz/p/5170147.html
b)单向链表的数组实现
第一种方法:
定义两个数组 data和right,data保存数据,right 保存下标所示的节点的右边节点的下标,并且为了方便同样增加一个表头,即data[0] 没有意义 right[0] 是真正第一个节点所在的下标 将最后一个节点的right 赋为-1
遍历的时候 首先将 t=0 读取 right[0] 知道真正第一个节点所在下标 然后输出 data[right[0]], 然后将 读取第二个节点所在下标 right[right[0]]
if(right(0)!=-1){ //检查表非空
t=right(0);
do{
cout<<data[t];
t=right[t];
}while(t!=-1)
}插入,删除就很简单了
参考资料:https://blog.csdn.net/test1280/article/details/72036146
啊哈算法
第二种方法
一个数组的数据类型是结构体Node,Node有两个int 一个data保存数据,一个next游标下一个节点 在数组中的下标
3.栈
栈就是一个后进先出的线性结构,限定只能从栈顶插入和删除操作
栈的相关概念:
- 栈顶与栈底:允许元素插入与删除的一端称为栈顶,另一端称为栈底。
- 压栈:栈的插入操作,叫做进栈,也称压栈、入栈。
- 弹栈:栈的删除操作,也叫做出栈
1)栈的数组实现
数组的末端为栈顶
一个index 表示 下一个元素要进来的位置,初始为0,也可以表示最后一个元素 初始为-1
当以数组为底层数据结构时,通常以数组头为栈底,数组头到数组尾为栈顶的生长方向: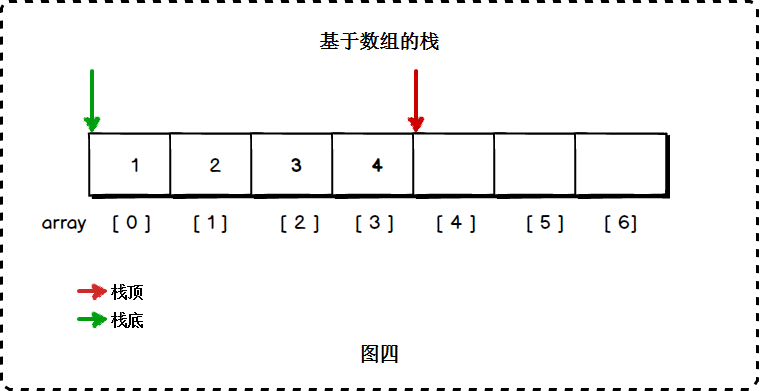
变容栈(能动态调整数组大小):
当栈的长度等于数组的大小时,即满栈 double
当栈的长度小于数组的1/4时,数组缩短1/2。
2)栈的链表实现
栈顶为表头first指向的真正第一个节点, pop,push均从表头实现
参考资料:http://www.cnblogs.com/QG-whz/p/5170418.html
4.队列
队列(Queue)与栈一样,是一种线性存储结构,它具有如下特点:
- 队列中的数据元素遵循“先进先出”(First In First Out)的原则,简称FIFO结构。
- 在队尾添加元素,在队头删除元素。
队列的相关概念:
- 队头与队尾: 允许元素插入的一端称为队尾,允许元素删除的一端称为队头。
- 入队:队列的插入操作。
- 出队:队列的删除操作。
1)数组队列
2个int( first last )分别标记队头 最后一个元素的下一个 数组头下标为队头 数组尾为队尾,
不使用循环队列:
加元素 元素放在数组尾 last++
删除元素 ++first
使用循环队列: 让数组中有个别被用
实现方式(一个指向第一个元素,一个指向尾后元素) 相同表示空 first==(last+1) %size 表示为满
见参考资料:http://www.cnblogs.com/QG-whz/p/5171123.html
2)链队列
以链表头部为队首,链表尾部为队尾。
class队列含有两个private Node * 数据成员 一个first的next指向链表头,方便删除元素
一个last的next指向链表尾,方便插入元素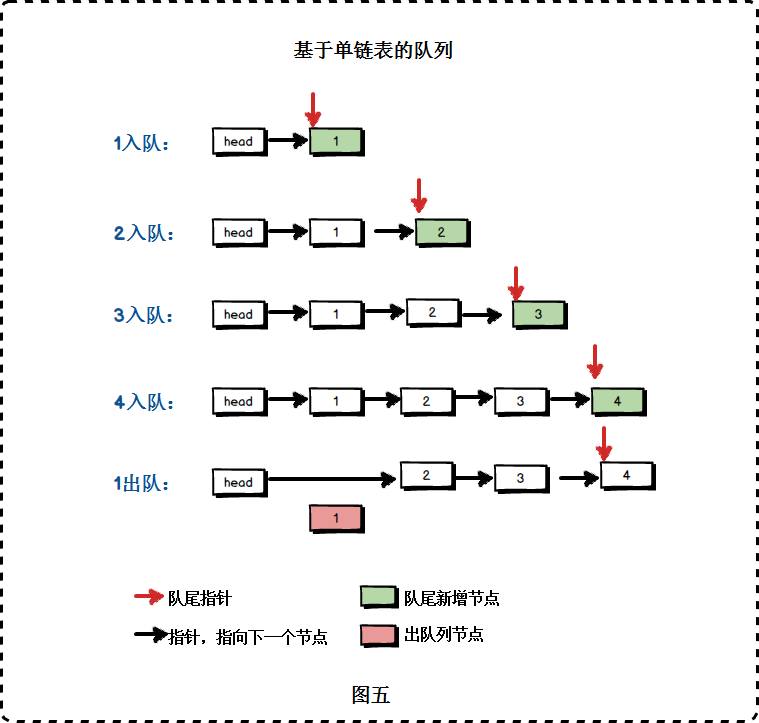
5. 排序
白话经典算法系列讲的挺好的:https://blog.csdn.net/MoreWindows/column/info/algorithm-easyword
1)冒泡排序
冒泡排序:总结起来就一句话:从左到右,数组中相邻的两个元素进行比较,将较大的放到后面
2)选择排序 O(N^2)
选择排序:总结一句话就是:从第一个位置开始比较,找出最小的,和第一个位置互换,开始下一轮
冒泡和选择的区别:
(1)冒泡排序是比较相邻位置的两个数,而选择排序是按顺序比较,找最大值或者最小值;
(2)冒泡排序每一轮的每一次比较,位置不对都需要换位置,选择排序每一轮比较都只需要换一次位置;
(3)冒泡排序是通过数去找位置,选择排序是给定位置去找数
参考资料:https://www.cnblogs.com/Good-good-stady-day-day-up/p/9055698.html
3)插入排序 O(N^2)
简单插入排序算法原理:从整个待排序列中选出一个元素插入到已经有序的子序列中去,得到一个有序的、元素加一的子序列,直到整个序列的待插入元素为0,则整个序列全部有序。
在实际的算法中,我们经常选择序列的第一个元素作为有序序列(因为一个元素肯定是有序的),我们逐渐将后面的元素插入到前面的有序序列中,直到整个序列有序。
一个维度为n的数组A[n] , 第i轮排序:把A[i] 从 A[i-1] 比较到A[0] 如果A[i] 小 则互换位置,继续往左比较,直到碰到第一个比它小的停下来 进行下一轮比较 i从0-n-1
参考资料:https://www.cnblogs.com/WuNaiHuaLuo/p/5397041.html
4)希尔排序
设待排序元素序列有n个元素,首先取一个整数increment(小于n)作为间隔将全部元素分为increment个子序列,所有距离为increment的元素放在同一个子序列中,在每一个子序列中分别实行直接插入排序。然后缩小间隔increment,重复上述子序列划分和排序工作。直到最后取increment=1,将所有元素放在同一个子序列中排序为止。
增长序列的取值方法
int h = 1;
while(h<N/3)
h =3*h+1; //1 4 13 40...
while(h>=1){
//排序
h = h/3
} 参考资料:https://blog.csdn.net/weixin_37818081/article/details/79202115
5)归并排序 O(NlogN) 但是因为需要 一个辅助数组,空间复杂度 double
首先考虑一个数组 first-mid mid+1-last都排好序了,那应该怎么把所有的都排好呢, 搞一个辅助数组, 只要从比较二个数列的第一个数,谁小就先取谁,取了后放在辅助数组里去。然后再进行比较,如果有数列为空,那直接将另一个数列的数据依次取出即可。
最后记得把辅助数组里的值赋给数组A
https://blog.csdn.net/MoreWindows/article/details/6678165
注意 mergearray 中的第22行 把辅助数组中的值都给回数组a对应的位置
最后的new
还有一个tips 要注意稳定性(e.g. 全年级的成绩,先按分数排序,再按班级排序,保证在一个班里 也是按分数排序),当合并时,当左边的数组一个值跟右边的数组一样时,先放左边的 再放右边的
//合并两个有序数组
void merge_array(int a[], int first, int mid, int last, int temp[]) {
int i = first, j = mid + 1;
int k = 0;
while (i <= mid && j <= last) {
if (a[i] <= a[j])
temp[k++] = a[i++];
else
temp[k++] = a[i++];
}
while (i <= mid)
temp[k++] = a[i++];
while (j <= last)
temp[k++] = a[j++];
for (i = 0; i < k; ++i)
a[first + i] = temp[i]; //不要忘了复制回去
}
//merge内部方法
void merge(int a[], int first, int last, int temp[]) {
if (last <= first) //当数组size小于等于1的时候 递归结束
return;
int mid = first + (last - first) / 2;
merge(a, first, mid, temp);
merge(a, mid + 1, last, temp);
merge_array(a, first, mid, last, temp);
}
//外部接口
void merge(int a[], int n) {
int *p = new int[n];
merge(a, 0, n - 1, p);
delete[] p;
}6) 快速排序 平均O(NlgN) 最坏O(N^2)
最坏的情况是:
第一次从最小的元素切分,第二次从第二小的元素切分
N+N-1+N-2+...+2+1 ~ N^2
所以要把数组随机洗牌 确保有序的可能性贼小
快速排序是C.R.A.Hoare于1962年提出的一种划分交换排序。它采用了一种分治的策略,通常称其为分治法(Divide-and-ConquerMethod)。
该方法的基本思想是:
1.先从数列中取出一个数作为基准数。
2.分区过程,将比这个数大的数全放到它的右边,小于或等于它的数全放到它的左边。
3.再对左右区间重复第二步,直到各区间只有一个数。
就是先搞定一个数 把它放到正确的位置,再继续搞
跟啊哈算法的 差不多
把第一个数 A[0] 当做基准数,i从1出发 碰到比A[0] 小的就停下 或者碰到尾了 就说明A[0]是最小的了 break
然后j从N-1出发
tips:
a) 碰到 一样的也停下来 交换 ,假设你有一个完全一样的数组A={1,1,...1} 你不交换的话,你每次都到数组尾停下来交换,那你每次 只得到了 左边一个半边 那复杂度跟最坏的情况一样 平方级,那假如每次都交换,那你就是每次从中间切,性能就NlogN
//啊哈算法的,有个坑,碰到相同的不停下来,以后有时间再看吧
void quicksort(int a[], int first, int last) {
if (last <= first)
return;
int i = first , j = last, x = a[first];
while (i != j) {
//先从右往左找
while (a[j] >= x && i < j)
--j;
while (a[i] <= x &&i < j)
++i;
if (i < j) {
int t = a[i];
a[i] = a[j];
a[j] = t;
}
}
a[first] = a[i];
a[i] = x;
quicksort(a, first, i - 1);
quicksort(a, i + 1, last);
}这是算法课的实现: (坑有点多,我没时间一步一步理解了,以后再说)


7)快速选择 quick select 复杂度O(N)
在一个数列中 找到第k大的数
基于快排
把一个数当做基准数,然后把小于它的都放在左边,大于它的都放在右边,然后看看它的下标是多少 假如小于k,那说明k在右半边,大于k,k在左边,等于k返回, 然后跟快排不一样 只对k在的半边 继续


8)3-way quick sort
看算法 p188
void threewaysort(int a[],int lo, int hi) {
if (hi <= lo)
return;
int lt = lo, i = lo + 1, gt = hi,v=a[lo];
while (i <= gt) {
if (a[i] < v) {
int temp = a[lt];
a[lt] = a[i];
a[i] = temp;
++lt, ++i;
}
if (a[i] == v) {
++i;
}
if (a[i] > v) {
int temp = a[gt];
a[gt] = a[i];
a[i] = temp;
--gt;
}
}
threewaysort(a, lo, lt - 1);
threewaysort(a, gt + 1, hi);
}总结对比
