计算机系统原理实验四报告
Cache仿真模拟
实验日期:2019.4.18~2019.5.3
实验目的
理解cache的工作原理,以及相应参数与算法对程序性能的影响
实验要求
- 编写由c语言实现的随机填充的500*500的整数矩阵乘法样例程序作为benchmark
- 通过gem5获得程序的内存地址访问序列
- 编写cache模拟器,即用软件的方法实现cache的工作原理,比如命中检查机制、内存地址和cache块的映射(全相联、组相联、直接映射)的实现和一些替换算法(Random,LRU)等。
- Cache模拟器,以获得的内存地址访问序列文件为输入,统计miss/hit。调整相关参数(cache块大小、cache大小)和算法(映射方式、替换算法),查看miss/hit的变化情况,并作出相应解释。
- Bonus:
Cache模拟器的算法流程图
实验过程
一、创建随机矩阵乘文件
首先我们先是写了一个500*500的随机矩阵乘的c文件
在此文件中我们一共创建了三个矩阵,两个随机矩阵,一个结果矩阵。两个随机矩阵的初始化如下:
for(i=0;i<500;i++){
for(j=0;j<500;j++){
matrix1[i][j]=rand()%100;
matrix2[i][j]=rand()%100;
}
}
而矩阵相乘的实现是由三层循环嵌套相乘得到,其内容如下:
for(i=0;i<500;i++){
for(j=0;j<500;j++){
int sum=0;
for(k=0;k<500;k++){
sum+=matrix1[i][k]*matrix2[k][j];
}
matrix3[i][j]=sum;
}
}
500*500500的随机矩阵乘的matrix.c文件已经写完了,接下来就要搭建gem5来对这个matrix.c文件进行交叉编译。
二、gem5的安装及可执行文件的生成
由于gem5是在Linux系统上搭建运行的,所以安装gem5以及往后的操作将在Ubuntu的终端上进行。
首先是对gem5的安装,在安装gem5之前要先安装各种库文件
sudo apt-get install mercurial scons swig gcc m4 python python-dev libgoogle-perftools-dev
g++ libprotobuf-dev
还要安装好编译环境
sudo apt-get install build-essential
sudo apt-get install libboost-dev
之后需要下载gem5的源码
hg clone http://repo.gem5.org/gem5
之后就进入到gem5目录下,编译gem5的各种架构,这一步花费的时间比较长
cd gem5
scons build/ARM/gem5.opt
编译完成后再安装arm交叉编译器
sudo apt-get install gcc-arm-linux-gnueabi
自此,gem5及其需求的相关资源已经配置完成,接下来就要对matrix.c文件进行交叉编译生成可执行文件。
对matrix.c进行交叉编译:(这里需要注意的是静态编译)
--static
arm-linux-gnueabi-gcc \文件路径\matrix.c -o \生成路径\matrix --static
接下来运行gem5生成可以分析的trace文件
build/ARM/gem5.opt --outdir=memaccess --debug-flag=DRAM --debug-file=dram.out
configs/example/se.py -c matrix
build/ARM/gem5.opt --outdir=memaccess --debug-flag=MemoryAccess --debug-file=
memoryaccess.out configs/example/se.py -c matrix
build/ARM/gem5.opt --outdir=memaccess --debug-flag=MMU --debug-file=mmu.out
configs/example/se.py -c matrix
dram.out文件包含了每条指令的地址及其类型(读和写)
mmu.out是程序加载过程中“gem5简单页表”的加载过程,即trace中的虚拟地址与物理地址的映射关系
memoryaccess.out文件为计算机执行指令的信息,包含了每条指令的操作类型、地址及操作数据的值
对于本次实验,我们只需要分析memoryaccess.out文件即可
三、编写cache模拟器
关于cache模拟器
我们是在GitHub上面找到一个别人已经写好上传的cache模拟器(jiangxincode/CacheSim),该模拟器功能非常全面,具有直接映射、全相联映射、组相联映射的映射机制,可以自己选择输入所需要的cache的大小以及cache块的大小,还有LRU和Random的替换策略,对于比较不同条件的cache命中率提供了很方便的环境。
关于cache模拟器的函数分析
在主函数中用到do(){}while();来进行多次对于cache命中率的计算,内部含有对于数据初始化、cache信息的初始化、文件的读取与进行命中判断、替换策略、以及对于cache命中率计算的函数,下面主要对于cache在各种情况下的命中判断与替换策略的思路/原理进行分析。
关于cache模拟器的原理/思路
该程序代码中对于cache_item的创建是用了bitset而不是采用int型数组,bitset是存储二进制的数位,就像是一个bool类型的数组,而且有空间优化,另外bitset的大小在编译时就要确定下来,也就是说bitset<>的尖括号里写的是大小,在本程序中创建的cacheline大小为32,其中31位存有效位,30位存命中位,29位存脏数据位,其余存数据。
而分析命中需要分别对不同的映射机制进行分析,判断是否命中的函数存在functions.cpp文件中的IsHit(bitset<32> flag)。
对于LRU策略的分析
LRU替换策略使用优先级数组进行判断,优先级数组的大小即为cache块的数量,若优先级数组中元素数值越大,对应其cache块的使用次数就越少,并且将最近访问的cache块所对应的优先级数组的元素置为0。
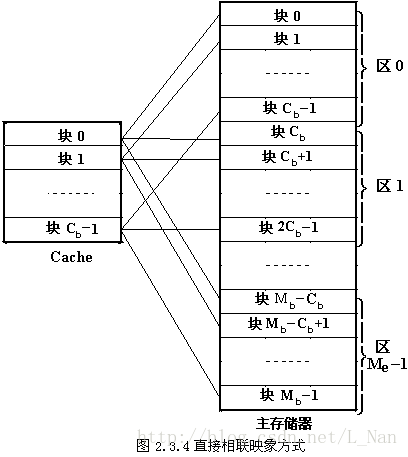
直接映射
首先将地址存入一个bitset,再通过从地址中取出bit_line(在代码中以for循环的形式)来判断在cache中的行号,取其后32位,来判断该cacheline中最后一位有效位valid是否为1,若为0,即无效,就是不命中;若为1,即有效,再比较该地址的tag与cacheline里的tag是否相同,若相同则命中;否则则不命中。
对于直接映射
a. 当其为命中且为读操作时,只是将访问次数、读次数、读命中次数和命中次数都+1,其余不做操作;
b.当其为不命中且为读操作时,只增加读的次数和访问的次数,另外将该地址所对应的数据块从内存放到cache中;
c.当其为命中且为写操作时,增加访问次数、写操作次数、写命中次数和命中次数,将其dirty位改为1,表示该内存块内容进行了写操作,内容发生了变化,以便于以后被替换时,将其写回内存中;
d.当其为不命中且为写操作时,只增加访问次数与写操作次数,另外将该地址所对应的数据块从内存放到cache中,再将写操作的数据写入cache块中,并将dirty位置为1。
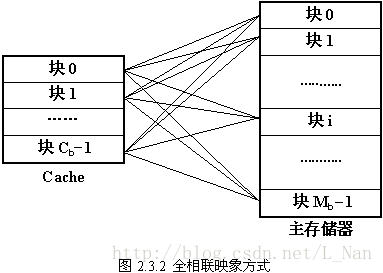
全相联映射
首先要计算出cache块的数量,由用户输入的cachesize/cachelinesize计算得到,并且能够通过cachelinesize来计算出块内地址的偏移量,也能求出tag的位数。
先将hit位判为true,再进行判定,判断地址(bitset<32> flag)中的valid有效位,若为0则不命中,若为1,则继续用tag位与cache块的tag位进行对比,若相同,则命中,若不相同,则与其他cache块的tag位进行比对,若都不相同,则判hit位为false,即不命中。
a.当其为命中且为读操作时,如直接映射,其访问次数等增加,再查看替换策略。若替换策略为LRU,则将此读命中的cache块的优先级与其他cache块的优先级进行比较,如果读命中的块的优先级小于其他块的优先级,则令其他块的优先级+1,再令读命中的cache块的优先级置为0;若替换策略为Random则不做处理。
b.当其为不命中且为读操作时,将该地址所对应的数据块从内存放到cache块中(遍历cache,将内存放入遍历到第一个valid=0的cache块中,并将valid置为1,且设置tag与hit位)。若替换策略为LRU,将其他块的优先级+1,再将导入数据块的cache块的优先级置为0;若替换策略为Random则不做处理。但若cache中所有cache块的valid都为1,则需要进行替换来为读操作所要导入的数据块腾出空间。若替换策略为LRU,需要找到优先级数组中数值最大的索引所对应的cache块,因为优先级数组元素的值越大说明该cache块最不常访问,再使此cache块与要导入的数据块进行替换;若替换策略为Random则便随机选择一个cache块进行替换。
c.当其为命中且为写操作时,其操作与直接映射的写命中操作一样,并且LRU替换策略的操作与全相联映射中读命中操作的LRU替换策略一样,若替换策略为Random则不做处理。
d.当其为不命中且为写操作时,其操作与全相联映射的读不命中操作相似,只是在寻找替换cache块后要将数据写入替换后的cache块中,并且将dirty位置为1;若替换策略为Random则便随机选择一个cache块进行替换。
组相联映射
与全相联映射类似,组相联映射也需要事先输入cachesize、cachelinesize以及cacheset(组相联的路数),再进行计算求出cache的组数(此操作在CalcInfo.cpp中的CalcInfo()函数中),再通过计算组数与2的幂次关系,就能得到内存地址中组地址的位数。
在判断命中之前,还是将内存地址存入32位的bitset中(bitset<32> flag),再根据内存地址中组地址来找到对应的组号,来判断该组中cache块valid与tag位。若某一块的valid=1且tag与内存地址中的tag相等,则命中;否则直到查完整组没有相同的,便不命中。
a.当其为命中且为读操作时,其操作与全相联映射的读命中操作一样。
b.当其为不命中且为读操作时,其操作与全相联映射的读不命中操作一样,不过在查找可以替换的cache块时是在组号对应的cache组中寻找。
c.当其为命中且为写操作时,其在组间的操作与全相联映射的写命中操作一样。
d.当其为不命中且为写操作时,其操作与全相联映射的写不命中操作一样,不过在查找可以替换的cache块时是在组号对应的cache组中寻找。

四、数据预处理
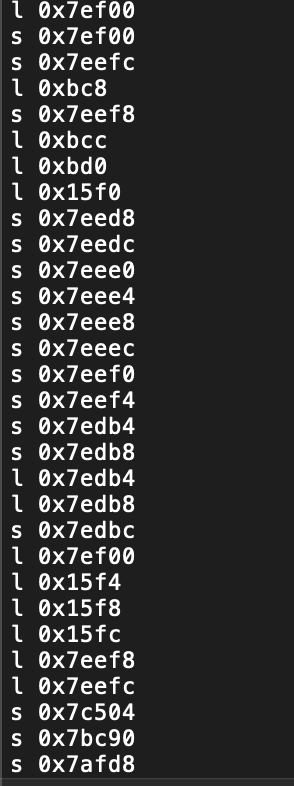
在编写完cache模拟器之后,我们清楚地了解了cache模拟器程序对于数据文件内的格式有一定的要求,而需要进行分析的memoryaccess.out文件内的内容格式如下:
由上图可见每行数据非常冗长,且存在许多无用数据,因此要对数据进行预处理。
 编写一个python程序来对memoryaccess.out文件进行预处理
编写一个python程序来对memoryaccess.out文件进行预处理
浏览CSDN博客(基于gem5模拟trace的cache模拟器的实现)可知:
Memoryaccess.out :(此文件相对较大,打开比较慢)
分成两部分:
第一部分:0---------------------------------0,tick 不增。
0 Tick:
此处显示的内容是把 hello 二进制程序“加载”到 gem5 的内存当中。
第二部分: 0--500--1000---------------------------end
0-500-1000,以 interval=500cycles 递增。此时就是实际程序逐条指令执行的过程。其中包括的信息和容易可以读懂。
因此根据memoryaccess.out文件中每行数据的第一列的数字是否为0来判断该指令是否是有用的指令,再根据第二列中“IFetch”、“Write”、“Read”来判断操作是取指令、写还是读。
因此这个python数据预处理的思路就已经出来了:首先读取文件里的每一行数据,以空格为参数进行切片,再存入一个列表中,根据固定几列的内容不同来进行分类,分成有用/无用指令以及读/写操作,实现代码如下:
for line in open("D:\\MemoryAccess.out"):
curLine=line.strip().split(" ")
#if curLine[1] == 'global:':
dataMat.append(curLine)
#print(dataMat[i][1])
#i = i +1
if dataMat[i][0] != "0:":
if dataMat[i][1] == 'global:' and dataMat[i][3] =='from':
if dataMat[i][2] == 'Read':
index.append('l')
elif dataMat[i][2] == 'Write':
index.append('s')
add = dataMat[i][10]
address.append(add[2:])
i = i + 1
判断结束后再根据cache模拟器里的文件输入格式进行调整输出文件,保存为test1.txt,代码如下:
l = []
for j in range(0,len(index)):
l.append([index[j],address[j]])
print(l[j])
#print ('dataMat:',dataMat)
#print(type(dataMat))
print('index:',index)
print('address:',address)
#print(l)
filename ="test1.txt"
text_save(filename,l) //关于此函数会在压缩文件夹中附python文件
生成test1文件后把该文件的后缀名改为trace即完成了对于文件的预处理,预处理完成的结果如下图所示:
实验过程中发现此格式化python文件处理大文件时,具有一定程度上占内存的坏处,处理大文件所需时间过长,格式化方法时间和空间复杂度过长,需要改正,现将读文件过程中的将两列数据存至列表再写至文件的方式改为,
每从文件中读取一行,便将处理后的数据写至新文件中,减少内存的占用,大幅提高效率。
try:
if curline[0] != "0:":
if curline[1] == 'global:' and curline[3] =='from':
#if dataMat[i][2] == 'IFetch':
# index.append(0)
if curline[2] == 'Read':
#index.append('l')
rs.write('l'+ ' ' + str(curline[10]) + '\n')
elif curline[2] == 'Write':
rs.write('s'+ ' ' + str(curline[10]) + '\n')
except:
continue
将新文件命名为newformat.py附在文件
自此数据预处理完成
五、运行cache模拟器、测试数据结果及分析
依次输入以下参数:Cache容量、块容量、映射方式、替换策略和写策略。
数据结果整理至附件中的cache-Result-format.csv中
结论:
1、Cache的命中率与容量大小有何关系?
Cache的容量与块长是影响cache效率的重要因素;
Cache容量越大,其CPU命中率就越高,当然容量过大,增加成本,而且cache容量达到一定值时, 命中率已不因容量的增加而又明显的提高;

2、Cache块大小对不命中率有何影响?
Cache 当块由小到大,在已被访问字的附近,近期也可能访问,增大块长,可将更多有用字存入缓存,提高命中率;但是继续增大块长,命中率可能下降,因为所装入缓存的有用数据反而少于被替换掉的有用数据,由于块长增大,块数减少,装入新的块要覆盖旧块,很可能出现少数块刚装入就被覆盖,故命中率可能下降;

3、替换算法对不命中率有何影响?
替换算法中:LRU算法的平均命中率比FIFO的高
LRU算法比较好地利用访存局部性原理,替换出近期用得最少的字块,它需要随时记录cache 各个字块使用情况。FIFO不需要记录各个字块的使用情况,比较容易实现开销小,但是没有根据访存的局部性原理,最早调入的信息可能以后还要用到,或经常用到例如循环程序;
4、相联度大小对不命中率有何影响?
Cache 容量一定时,随着相联度的不断增加,不命中率渐渐减小,但是当相连度增加到一定程度时,不命中率保持不变;

