主从复制
主从复制是主机数据更新后根据配置和策略,自动同步到备机的master/slaver机制,master以写为主,slaver只可读
作用:1、读写分离,性能扩展;2、容灾快速恢复

例如有三台服务器代号分别取为6379、6380、6381
首先按照需要修改各服务器conf配置文件,例如设置daemonize为yes;appendonly可关掉;如果6380、6381配置文件的参数slaveof后面添加6379的IP地址和端口号,则启动后6379自动为后两者的主服务器
如果配置文件中slaveof参数设置,可以在所有选定的从服务器启动后命令行输入“slaveof IP地址 端口号“,建立主从关系。主服务器自动向从服务器同步数据。

多级主从关系中,只有顶端的那台主服务器可写

在多级主从关系6379 <——6380<——6381中,如果主服务器6379宕机,希望6380成为主服务器并可写,在6380上用SLAVEOF no one命令

一主二仆模型下的哨兵模式

演示步骤:
1、建立三个服务器,6379、6380、6381,并设立后两个是6379的从服务器
2、每个服务器中创建sentinel.conf文件,文件填写内容为:sentinel monitor mymaster 127.0.0.1 6379 1。其中mymaster为监控对象起的服务器名称,1为当所有服务器中有1个哨兵认为主服务器宕机就开始迁移主机
3、执行该文件

当6379宕机,哨兵自动选择一台从服务器为主服务器,这里选了6381,当6379再启动后会作为6381的从服务器工作

此时选择哪一台从服务器,其优先级根据为:1、首先比较各服务器conf文件里参数slave-priority的值;2、当优先级值一样时,自动判断并选择偏移量最大(数据最全,获得原主数据最多)的那台;3、选择runid最小的那台,每个redis实例启动后都会随机生成一个runid。
集群
集群实现了对redis的水平扩容,即启动N个redis节点,将整个数据库分布存储在这N个节点中,每个节点存储总数据的1/N。redis集群通过分区提供一定程度的可用性:即使集群中有一部分节点失效或无法进行通讯,集群也可以继续处理命令请求。
集群的好处:实现扩容、分摊压力、无中心配置相对简单
集群的不足:多键操作不被支持、多键的redis事务不被支持,lua脚本不被支持、由于集群出现较晚,很多公司采用其他集群方案,而代理或者客户端分片的方案想要迁移到redis cluster,需要整体迁移而不是逐步过渡,复杂度较大。
建立集群操作
1、一个集群至少要有3个主节点,一个主节点至少一个从节点,所以使用至少6台服务器,假设代号为6379、6380、6381、6389、6390、6391
2、安装ruby、rubygems及gem install xxxx

3、修改每台服务器的conf配置文件,例如cluster-enabled yes打开集群模式、cluster-config-file nodes-6379.conf 设定节点配置文件名、cluster-node-timeout 15000 设定节点失联时间,超过改时间(毫秒),集群自动主从切换
4、./redis-trib.rb create --replicas 1 ip 端口 ip 端口 ip 端口。。。 其中1表示为一个主分配一个从
如下图自动分配了3主3从


连接集群需要命令后面加-c
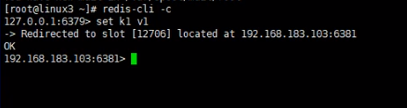
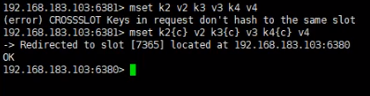
整个集群分成16384个槽,平均分布到3个主服务器中,每个键按照一定算法储存在对应的槽中,不在同一个槽中的键不能使用mget、mset命令,可在键名后加{},括号内的内容一样的话,所有键会储存在一个槽
如果某主节点宕机,对应从节点自动升为主节点,原主节点在恢复正常后会作为从节点。
如果一对主从节点都宕机,根据conf文件中参数cluster-require-full-coverage设定的值决定整个集群继续还是停止