上次我们看了CAP定理,以及CP,AP架构的原则,这篇文章主要聊下redis的几种集群架构方式。以及对应的架构原则。
主从理解
对于任何一个服务我们都在讲高可用,如果对于一个单机服务如果挂掉了那岂不是就GG了。那我们为了让服务available那就进行多起几个服务进行数据冗余,达到挂掉一个还有一个顶着。但是在保存的数据的时候会有很多的麻烦事,写数据的一致性问题,当给每台机器都进行写数据的时候且各个节点之间的数据是互相同步的,这个时候就遇到了并发安全问题,通过各种加锁同步操作会对整个服务的性能严重下降,这也就本末倒置,聋子搞成了哑巴。所以我们就只写一个节点,其他节点也可以处理请求,但是都是处理读取的请求。其中写的库我们叫主库(master),读取的库叫做从库,读写分离的主从方式。这也就是我们要学习的redis第一个架构方式主从复制。
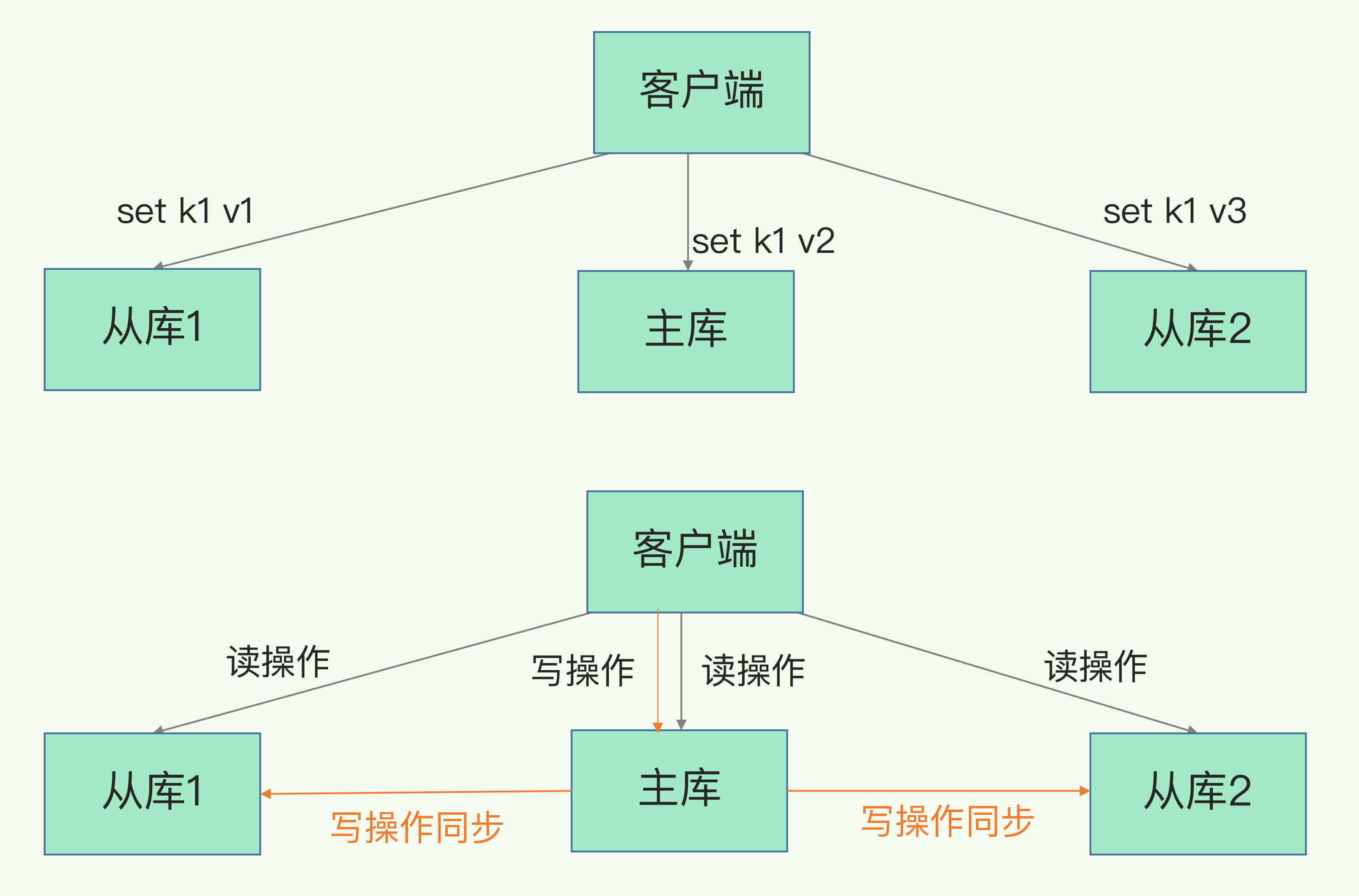
主从如何同步
首先redis就是带有这个功能的,那既然有这个功能,那作为开发者就只需要设置就可以了(还得理解其原理)。必然第一步就是启动多个redis实例,设置主从的节点 在从节点的实例上指定主节点的IP和端口(replicaof 172.16.19.3 6379)
主库与从库建立连接后那就开始同步,但是这个时候有可能从库是有数据的,那就得从库先清理数据了,数据清理完成后才能讲主库的数据进行本地的读取。
同步分为两种情况,一种是全量同步,一种是增量同步。
建立连接后从库会给主库发送命令psync,且带有两个参数:主库的I runID 和复制进度offset 是第一次建立连接从库不知道主库的runId 和 offset,runID给? offset 为-1 发送给主库,主库接受到这个命令后就会全量复制通过命令 FULLRESYNC 响应且返回自己的runID 和 offset 并且将主库的所有的数据通过RDB文件的方式传输给从库。RDB 文件是主库通过触发bgSave命令进行生成的。
人们常说redis是单线程,那如果进行了主从同步那岂不是业务的读写会被阻塞了?那这如果真实第一次同步全量那岂不是整个服务有坑阻塞不可用了。刚我们也有讲到的是,适用bgsave进行同步数据的,bgsave:创建一个子进程,专门用于写入 RDB 文件,避免了主线程的阻塞,这也是 Redis RDB 文件生成的默认配置。那我们知道了在这一步并不会阻塞主进程的读取和写数据,但是这个时候又有问题了也就是在快照的同时又有写,会导致数据不一致的。所以又用到了另一个技术CopyOnwrite(详细的原理大家自行了解),这里还有一个点就会死fork一个子进程,我们也知道fork子进程也会阻塞住进程的,在这里我就先忽略不计这个阻塞。
在一次RDB文件同步过程中也是有时间的,在同步这段时间又有数据写入呢?,这个时候就要通过增量实现再同步了,也就是说全量同步完就开始增量同步了。
上面说了通过RDP文件进行全量同步数据的过程,接下来我们看下增量同步的过程,增量同步的意思就是不用全部同步只同步更改的数据,在redis中有一个replication buffer 会存储修改数据,从中的修改操作发给从库,从库再重新执行这些操作,这么一来就实现了增量更新。
下图就是主从复制的一个过程:

但是主从一般不是一对一的,是1对多个的,那么如果是这样的话,就导致主库忙于进行生成RDB文件和传输RDB文件,在这个过程中会fork子进程,所以就会阻塞主进程,导致redis服务性能差的问问题。那这种问题我们如何解决呢?
主从从
为了避免主库压力太大影响主进程,那么我们是不是可以将压力分给从库呢?通过从库进行给从库同步数据。这么做第一个想到的问题点在于多次复制数据的实时一致性肯定会受到影响的。也就是读从从库的数据会有延迟。那这是不是就是我们所说的AP架构呢,放弃了一致性而保证了我们服务的可用性和分区容错性呢。
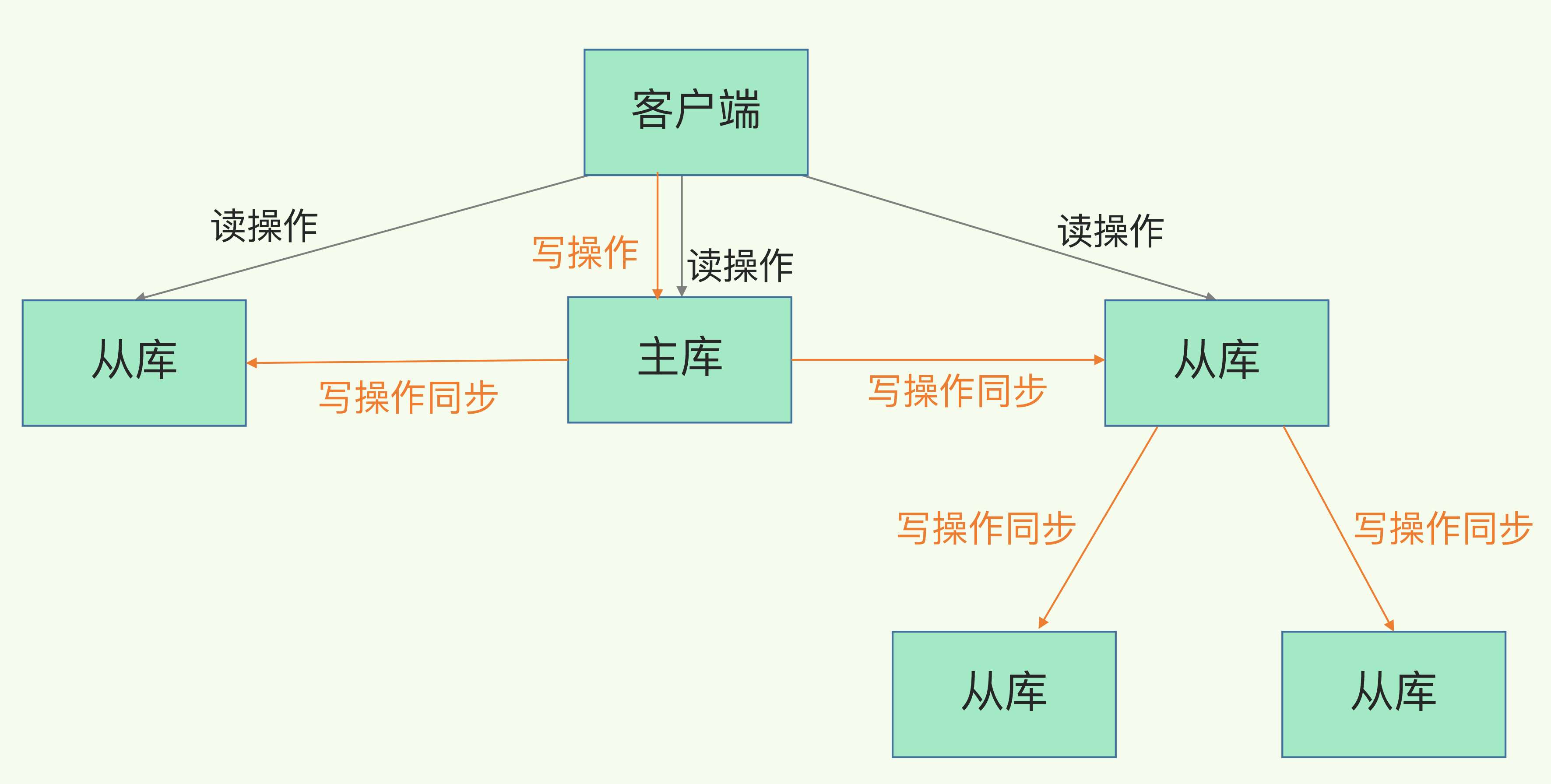
既然说到了分区容错性,那么如果主从架构出现了分区是如何应对的呢?
主从复制网络问题
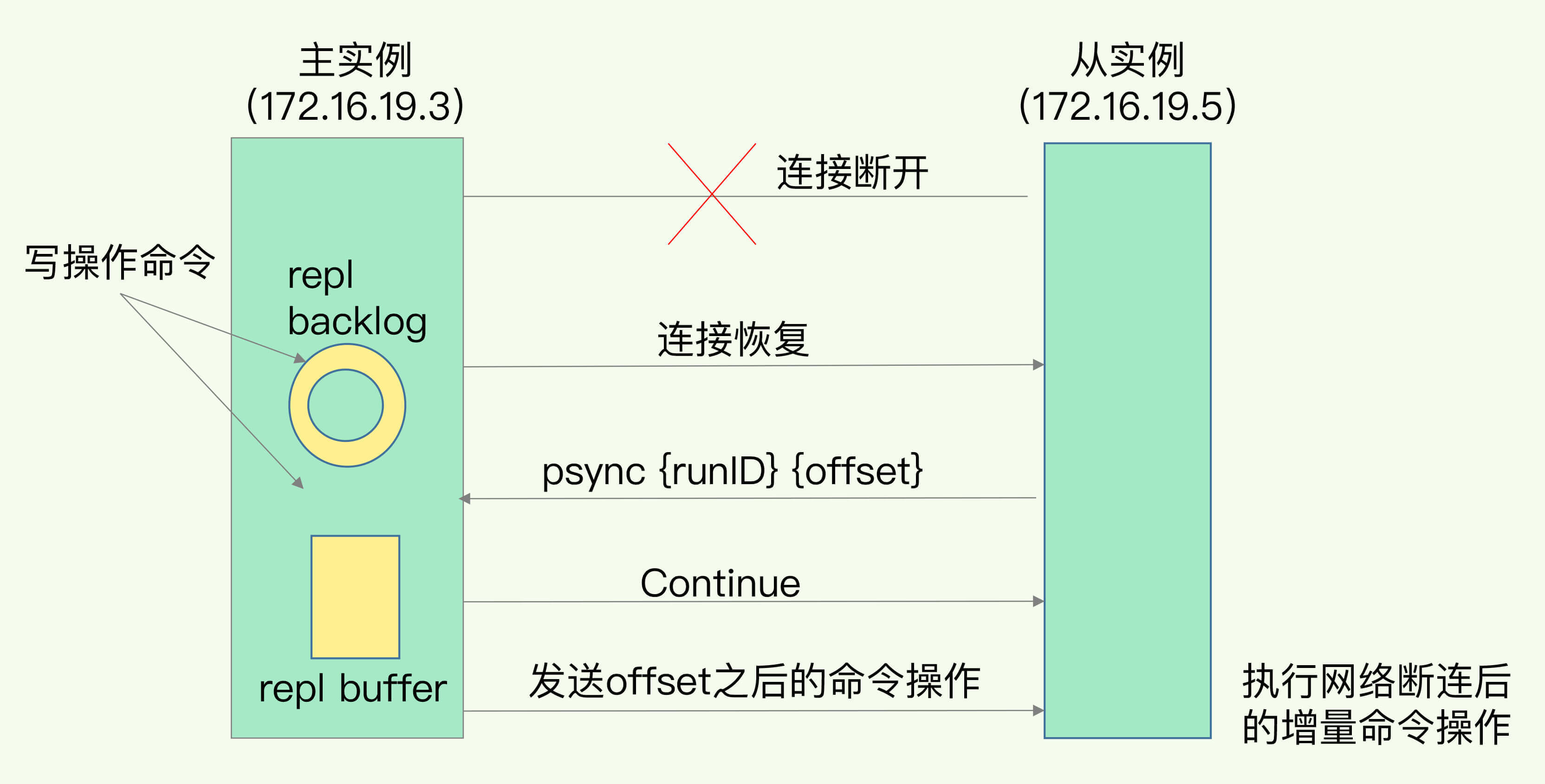
在redis 2.8之前,如果主从在命令传输出现闪断,那么从库会和主库重新进行一次全量的复制。
在2.8之后采用的是增量同步,既然是增量,那肯定是会有记录的,不然怎么增量。还有就是当断掉作为主节点是如何知道呢?这个就容易了,那肯定有一个ack的过程,没有成功那说明就断掉了。重点看一下如何记录的如何知道从那开始同步的呢?
redis内部有一个repl_backlog_buffer,主库会记录自己写到的位置,从库会记录读到的位置。简单描述就是,主库会记录一个偏移量master_repl_offset,从库会记录slave_repl_offset,当发现断开恢复连接后会从库发送psync 并且把slave_repl_offset发送给主库,主库通过对比就发现了需要进行增量同步缺失的数据了。
但是repl_backlog_buffer这个空间是有限制的,如果我们服务并发量很高的情况下还是会有一致性问题的。
统一回顾一下主从复制过程
优缺点
那聊了这么多,那主从的优缺点是什么呢?这个架构算是简单,搭建一套成本不算高。
但是对于这个架构如果内存不够用了我们怎么进行横向扩容呢?
还有就是如果主节点/从节点宕机了是否能自动恢复?
还有就是全量复制的问题,fork子进程导致住进程阻塞,服务缓慢。
总结
上文我们聊了主从复制的主要过程,还有一些问题点,以及优缺点。我们从上文的分析过程中,我们觉得主从算是一个CAP定理中的那种架构方式呢?我认为是CP架构,因为我们可以看到,主从复制为了达到一致性,牺牲了可用性。fork子进程去哪领同步,存储log增量同步重连再增量同步。。这都是对可用性的损失。
这篇文章主要是redis 主从复制的学习,和对CAP定理的巩固和应用理解。
下篇我们再聊如果主节点挂了我们怎么应对 。。。。。
参考资料
- https://www.163.com/dy/article/FTJ943870531A0HG.html
- https://time.geekbang.org/column/article/272852