最近一段时间一直在做网络爬虫,昨天的时候爬取了一下豆瓣,现在向大家分享一下。
一、设置Chrome无界面浏览器
1.PhantomJS的终结
在前几年的时候,PhantomJS这款无头浏览器十分的火爆,几乎大多数网络爬床都通过它来抓取网站。但是在使用之前,我进行了一个小小的测试,发现了一些问题,话不多说上测试代码(运行环境为Python3.7)
from selenium import webdriver
import time
driver = webdriver.PhantomJS(executable_path=r'E:\Pythonlearnsoftware\phantomjs-2.1.1-windows\bin\phantomjs')
driver.get("http://pythonscraping.com/pages/javascript/ajaxDemo.html")
time.sleep(3)
print(driver.find_element_by_id('content').text)
driver.close()运行这段代码,结果是正确的,但是出现了警告:
![]()
长长的一段,这是什么意思呢?经过一番研究明白了,原来是现在的Selenium已经不再支持PhantomJS了。看到这个消息我有点小懵逼。PhantomJS居然过时了。好吧,看来要学习新东西了。查阅资料才发现原来在2017年Google和Firefox都推出了自家的无界面浏览器,看了这个终于懂了,Selenium不再对PhantomJS进行支持。好吧,那就来看看Chrome的无界面浏览器吧。
2.Chrome无界面浏览器配置
要使用Chrome无界面浏览器,需要从http://chromedriver.storage.googleapis.com/index.html网址中下载与本机chrome浏览器对应的驱动程序,驱动程序名为chromedriver;(这个可是博主找了好久的)
附chromedriver与chrome的对应关系表:
| chromedriver版本 | 支持的Chrome版本 |
|---|---|
| v2.40 | v66-68 |
| v2.39 | v66-68 |
| v2.38 | v65-67 |
| v2.37 | v64-66 |
| v2.36 | v63-65 |
| v2.35 | v62-64 |
| v2.34 | v61-63 |
| v2.33 | v60-62 |
| v2.32 | v59-61 |
| v2.31 | v58-60 |
| v2.30 | v58-60 |
| v2.29 | v56-58 |
| v2.28 | v55-57 |
| v2.27 | v54-56 |
| v2.26 | v53-55 |
| v2.25 | v53-55 |
| v2.24 | v52-54 |
| v2.23 | v51-53 |
| v2.22 | v49-52 |
| v2.21 | v46-50 |
| v2.20 | v43-48 |
| v2.19 | v43-47 |
| v2.18 | v43-46 |
| v2.17 | v42-43 |
| v2.13 | v42-45 |
| v2.15 | v40-43 |
| v2.14 | v39-42 |
| v2.13 | v38-41 |
| v2.12 | v36-40 |
| v2.11 | v36-40 |
| v2.10 | v33-36 |
| v2.9 | v31-34 |
| v2.8 | v30-33 |
| v2.7 | v30-33 |
| v2.6 | v29-32 |
| v2.5 | v29-32 |
| v2.4 | v29-32 |
下载好将其放到谷歌浏览器的安装目录就可以了。哦对了,还有一件非常重要的事情,就是要配置谷歌浏览器的环境变量,相信这个大家都会吧。不会的也没有关系,博主还写过一篇JDK配置的文章,可以参考一下。
准备工作都完成了,开干吧!!!
3.使用Chrome无界面浏览器发送网页请求
这个大家去看看官方文档,很简单的,就这么几句话。
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
driver = webdriver.Chrome(options=chrome_options)
driver.get("http://www.douban.com")
二、使用Selenium登录豆瓣网
平常,我们在网页上打开豆瓣的登录界面是这样的

分析界面源代码,找出两个密码输入框,和登录按钮:
<input id="username" name="username" type="text" class="account-form-input" placeholder="手机号 / 邮箱" tabindex="1">
<input id="password" type="password" name="password" class="account-form-input password" placeholder="密码" tabindex="3">
<a href="javascript:;" class="btn btn-account">登录豆瓣</a>
根据XPath和name属性定位这个三个元素,并且输入密码,代码如下:
#输入账号密码
driver.find_element_by_name("username").send_keys("xxxxxxx")
driver.find_element_by_name("password").send_keys("xxxxxx")
#模拟点击登录
driver.find_element_by_xpath("//a[@class='btn btn-account']").click()但是程序运行以后,报错说是找不到username,what???我检查了一下,没有写错啊,怎么回事。再次分析源代码发现豆瓣的登录框是包含在一个iframe中的。哦好吧,调整登陆策略。
分析<iframe style="height: 300px; width: 300px;" frameborder="0" src="//accounts.douban.com/passport/login_popup?login_source=anony"></iframe>发现,他的登录框其实在一个网页上//accounts.douban.com/passport/login_popup?login_source=anony。
样式是这样的:
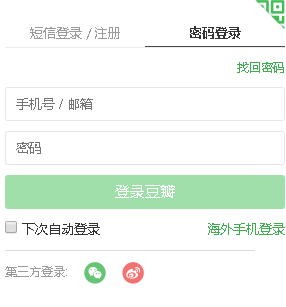
那么请求代码就要改变了
driver.get("https://accounts.douban.com/passport/login_popup?login_source=anony")好嘛,那我就请求这个网页向它提交表单进行登录。
但是

好吧,分析错误,他说没找到登录按钮。咦,怎么回事,我看看。
经过我的一番分析发现原来豆瓣的两个输入框里面都有东西才会被激活!!!
激活前
<a href="javascript:;" class="btn btn-account">登录豆瓣</a>
激活后
<a href="javascript:;" class="btn btn-account btn-active">登录豆瓣</a>好吧改变XPath路径,这回就可以了
driver.find_element_by_xpath("//a[@class='btn btn-account btn-active']").click()登录进来不会进入首页,进入了账号页面,现在我们只需要跳到首页就可以了
三、进入首页
分析账号页面发现在右下角有这么一栏:
![]()
我们就借助这个跳过去
分析源代码,写出XPath路径
driver.find_element_by_xpath("//a[@href='https://www.douban.com/about']").click()好了,跳过去了,但是还没有到首页,那就继续跳。
关于豆瓣这一页有个大大的首页二字,哈哈哈,就你了。

分析源代码上XPath
driver.find_element_by_xpath("//a[@href='https://www.douban.com']").click()现在大功告成了。
四、附件
下面是我的源代码,可以参考(注释挺详细的哦)
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
import time
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
driver = webdriver.Chrome(options=chrome_options)
driver.get("https://accounts.douban.com/passport/login_popup?login_source=anony")
# 等待3秒
time.sleep(3)
#切换为密码登录
driver.find_element_by_xpath("//li[2]").click()
#输入账号密码
driver.find_element_by_name("username").send_keys("账号")
driver.find_element_by_name("password").send_keys("密码")
#模拟点击登录
driver.find_element_by_xpath("//a[@class='btn btn-account btn-active']").click()
# 等待3秒
time.sleep(5)
driver.find_element_by_xpath("//a[@href='https://www.douban.com/about']").click()
time.sleep(2)
driver.find_element_by_xpath("//a[@href='https://www.douban.com']").click()
# 生成登陆后快照
driver.save_screenshot("douban.png")
with open("douban.html", "w", encoding="utf-8") as file:
file.write(driver.page_source)
driver.quit()