版权声明:欢迎转载,转载需要明确表明转自本文 https://blog.csdn.net/u012442157/article/details/81605572
一、background
虽然scrapy是一个非常强大的工具,也能配合selenium来使用,但是时间比较紧,不知道为什么没有成功将selenium应用在scrapy上。日后再研究一下。
本篇博文只要讲述如何使用selenium,这是一个模拟浏览器来爬取数据的工具,当然还会使用到BeautifulSoup,专门提取网页内容的工具。
二、安装
安装selenium
# 一条命令搞定
pip install selenium
BeautifulSoup
因为我是使用anaconda安装的python,已经有bs4了。
三、配置火狐浏览器
这个还是相当复杂的,搞了很多次才搞定,因为版本的问题。
下载火狐浏览器安装好了之后,需要一个插件,geckodriver。
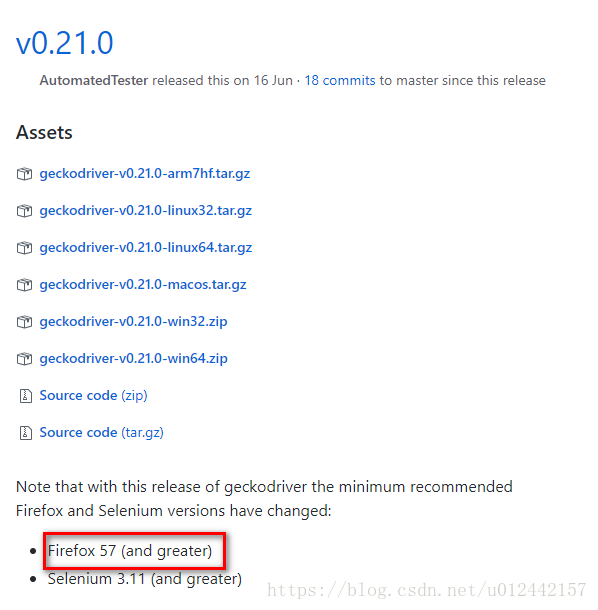
插件地址:https://github.com/mozilla/geckodriver/releases/
如图所示,虽然写着这个插件支持火狐57及以上版本,但是实验并没有成功。
解决办法:
看到一个解决办法,就是不用v0.21.0,用v0.20.1的geckodriver。

我为了保险起见,火狐浏览器的版本也换成了57,下载地址如下http://ftp.mozilla.org/pub/firefox/releases/
还有最后一步,需要把geckodriver拷贝到火狐浏览器的安装目录下,例如我的目录为:C:\Program Files\Mozilla Firefox。
然后该目录要添加到环境变量中。
四、爬虫
整理好github上传